At RSA this year, a familiar theme kept surfacing in conversations around AI:
Organizations are moving fast. Faster than their security strategies.
AI agents are no longer experimental. They’re being deployed into real environments, connected to tools, data, and infrastructure, and trusted to take action on behalf of users. And as that autonomy increases, so does the risk.
Because, unlike traditional systems, these agents don’t just follow predefined logic. They interpret, decide, and act. And that means they can be manipulated, misled, or simply make the wrong call.
So the question isn’t whether something will go wrong, but rather if you’ve accounted for it when it does.
Joshua Saxe recently outlined a framework for evaluating security-for-AI vendors, centered around three areas: deterministic controls, probabilistic guardrails, and monitoring and response. It’s a useful way to structure the conversation, but the real value lies in the questions beneath it, questions that get at whether a solution is designed for how AI systems actually behave.
Start With What Must Never Happen
The first and most important question is also the simplest:
What outcomes are unacceptable, no matter what the model does?
This is where many approaches to AI security break down. They assume the model will behave correctly, or that alignment and prompting will be enough to keep it on track. In practice, that assumption doesn’t hold. Models can be influenced. They can be attacked. And in some cases, they can fail in ways that are hard to predict.
That’s why security has to operate independently of the model’s reasoning.
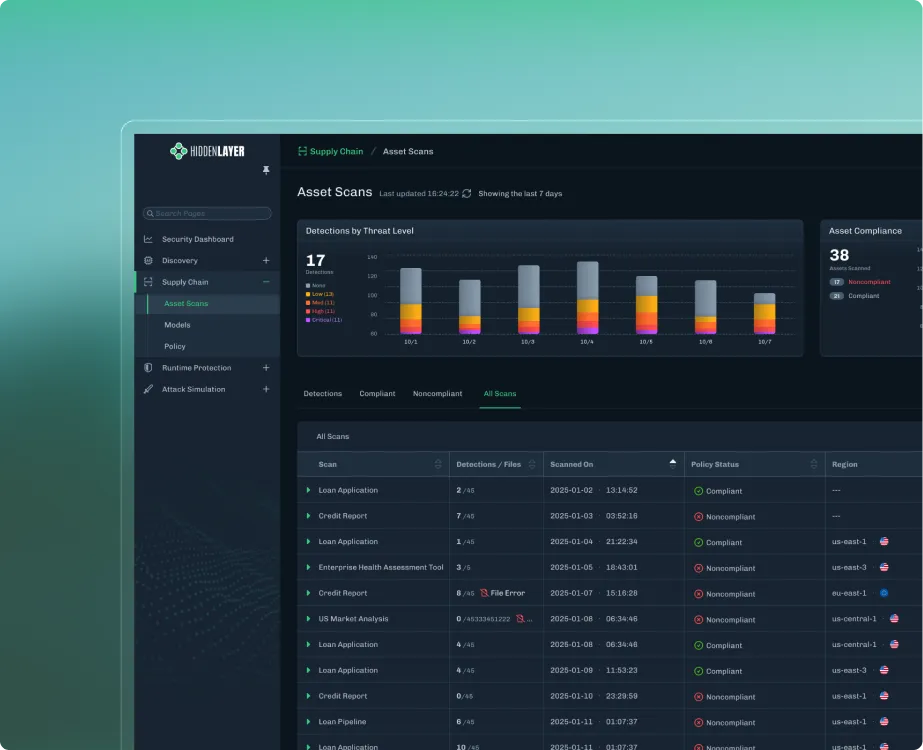
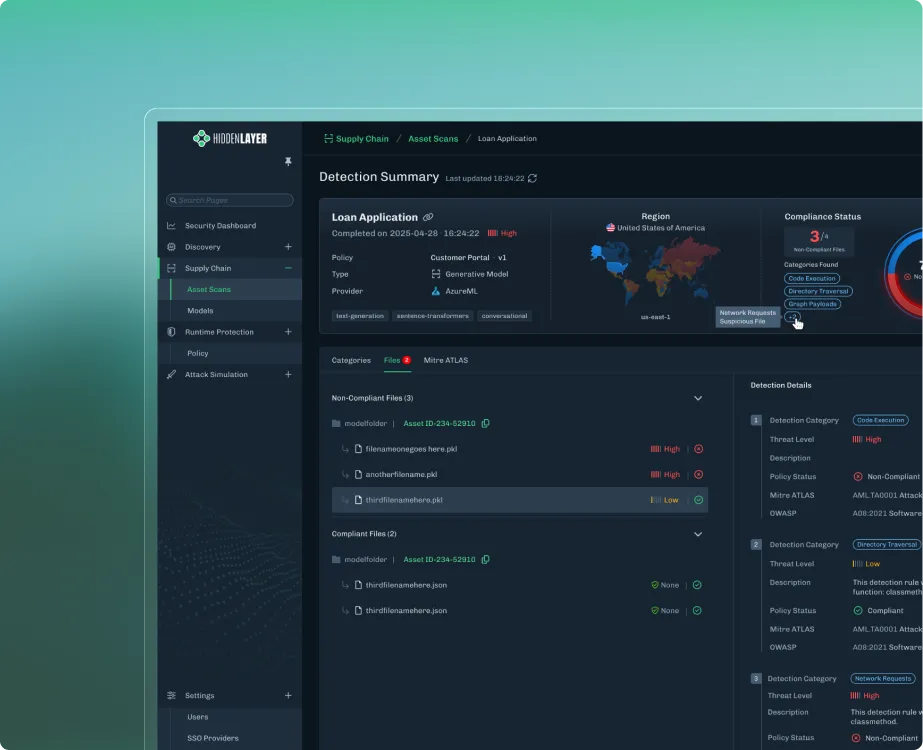
At HiddenLayer, this is enforced through a policy engine that allows teams to define deterministic controls, rules that make certain actions impossible regardless of the model’s intent. That could mean blocking destructive operations, such as deleting infrastructure, preventing sensitive data from being accessed or exfiltrated, or stopping risky sequences of tool usage before they complete. These controls exist outside the agent itself, so even if the model is compromised, the boundaries still hold.
The goal isn’t to make the model perfect. It’s to ensure that certain failures can’t happen at all.
Then Ask: Who Has Tried to Break It?
Defining controls is one thing. Validating them is another.
A common pattern in this space is to rely on internal testing or controlled benchmarks. But AI systems don’t operate in controlled environments, and neither do attackers.
A more useful question is: who has actually tried to break these controls?
HiddenLayer’s approach has been to test under real pressure, running capture-the-flag challenges at events like Black Hat and DEF CON, where thousands of security researchers actively attempt to bypass protections. At the same time, an internal research team is continuously developing new attack techniques and using those findings to improve detection and enforcement.
That combination matters. It ensures the system is tested not just against known threats, but also against novel approaches that emerge as the space evolves.
Because in AI security, yesterday’s defenses don’t hold up for long.
Security Has to Adapt as Fast as the System
Even with strong controls, another challenge quickly emerges: flexibility.
AI systems don’t stay static. Teams iterate, expand capabilities, and push for more autonomy over time. If security controls can’t evolve alongside them, they either become bottlenecks or are bypassed entirely.
That’s why it’s important to understand how easily controls can be adjusted.
Rather than requiring rebuilds or engineering changes, controls should be configurable. Teams should be able to start in an observe-only mode, understand how agents behave, and then gradually enforce stricter policies as confidence grows. At the same time, different layers of control, organization-wide, project-specific, or even per-request, should allow for precision without sacrificing consistency.
This kind of flexibility ensures that security keeps pace with development rather than slowing it down.
Not Every Risk Can Be Eliminated
Even with deterministic controls in place, not everything can be prevented.
There will always be scenarios where risk has to be accepted, whether for usability, performance, or business reasons. The question then becomes how to manage that risk.
This is where probabilistic guardrails come in.
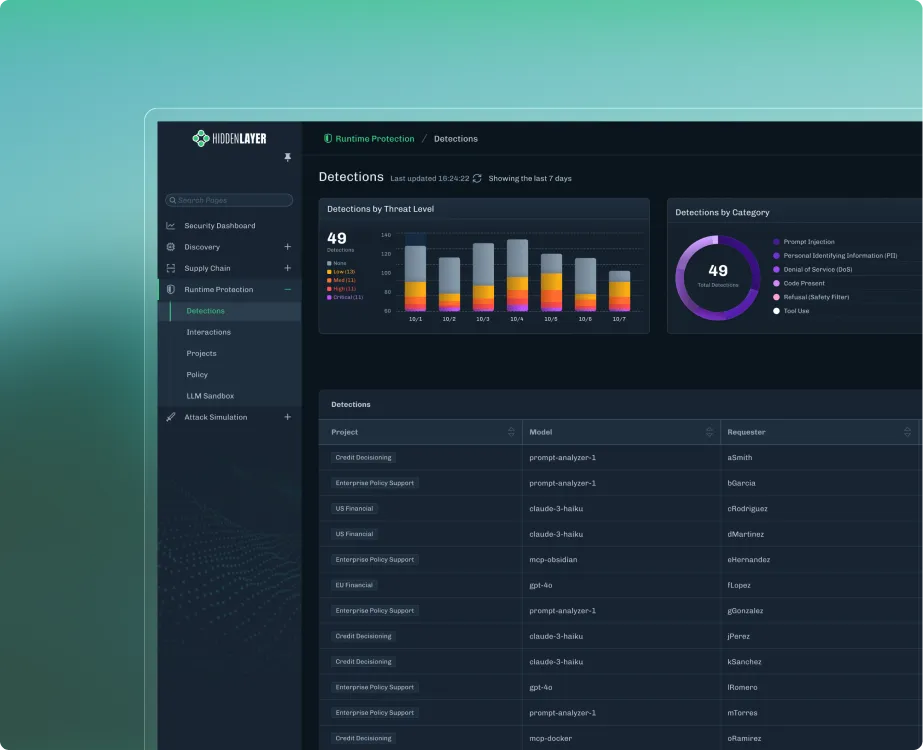
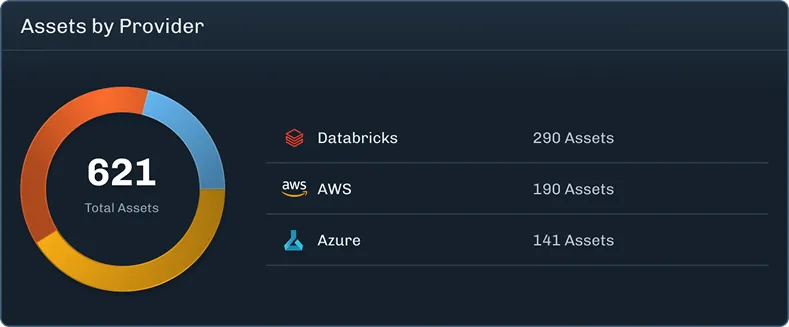
Rather than trying to block every possible attack, the goal shifts to making attacks visible, detectable, and ultimately containable. HiddenLayer approaches this by using multiple detection models that operate across different dimensions, rather than relying on a single classifier. If one model is bypassed, others still have the opportunity to identify the behavior.
These systems are continuously tested and retrained against new attack techniques, both from internal research and external validation efforts. The objective isn’t perfection, but resilience.
Because in practice, security isn’t about eliminating risk entirely. It’s about ensuring that when something goes wrong, it doesn’t go unnoticed.
Detection Only Works If It Happens Before Execution
One of the most critical examples of this is prompt injection.
Many solutions attempt to address prompt injection within the model itself, but this approach inherits the model's weaknesses. A more effective strategy is to detect malicious input before it ever reaches the agent.
HiddenLayer uses a purpose-built detection model that classifies inputs prior to execution, operating outside the agent’s reasoning process. This allows it to identify injection attempts without being susceptible to them and to stop them before any action is taken.
That distinction is important.
Once an agent executes a malicious instruction, the opportunity to prevent damage has already passed.
Visibility Isn’t Enough Without Enforcement
As AI systems scale, another reality becomes clear: they move faster than human response times.
This raises a practical question: can your team actually monitor and intervene in real time?
The answer, increasingly, is no. Not without automation.
That’s why enforcement needs to happen in line. Every prompt, tool call, and response should be inspected before execution, with policies applied immediately. Risky actions can be blocked, and high-risk workflows can automatically trigger checkpoints.
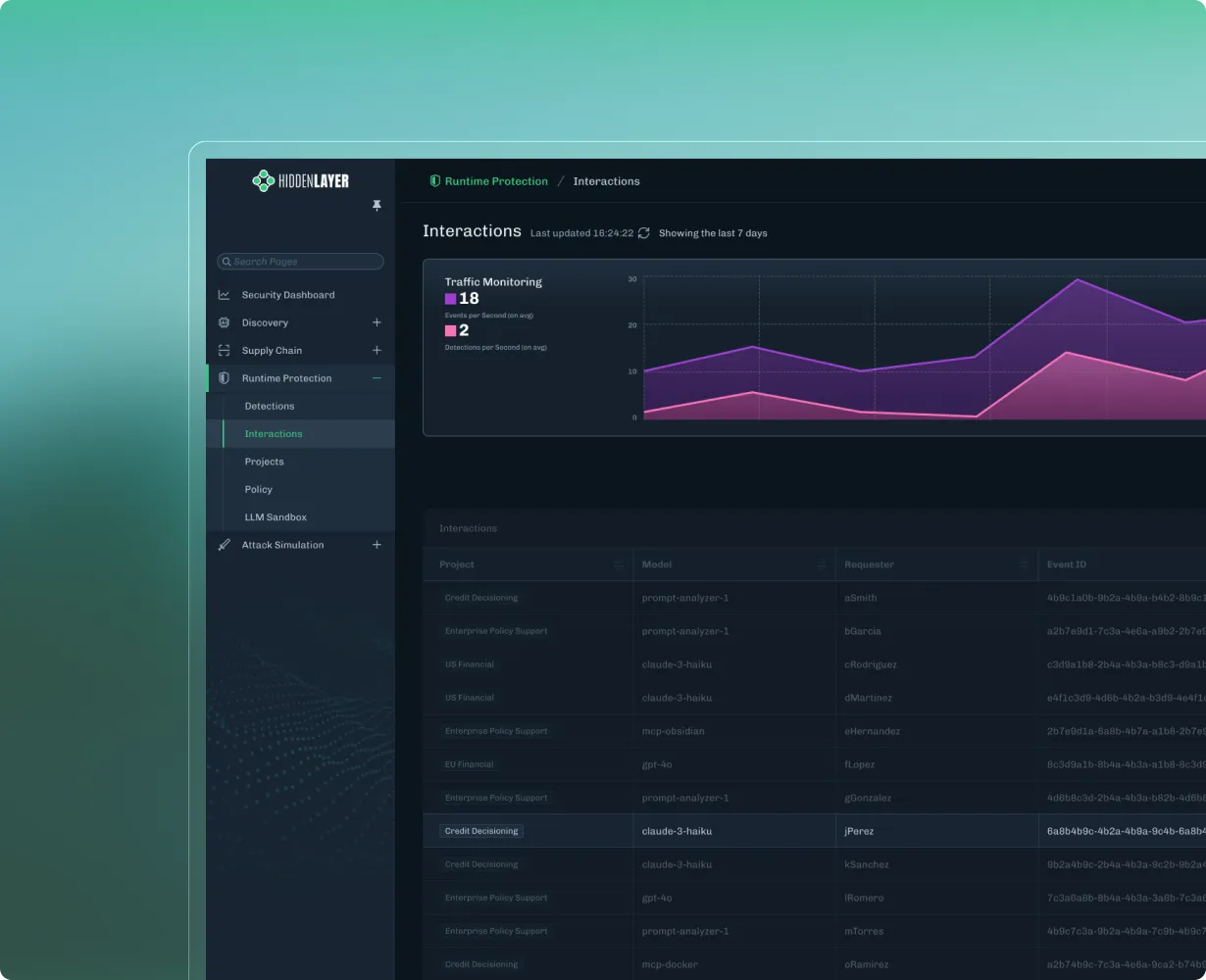
At the same time, visibility still matters. Security teams need full session-level context, integrations with existing tools like SIEMs, and the ability to trace behavior after the fact.
But visibility alone isn’t sufficient. Without real-time enforcement, detection becomes hindsight.
Coverage Is Where Most Strategies Break Down
Even strong controls and detection models can fail if they don’t apply everywhere.
AI environments are inherently fragmented. Agents can exist across frameworks, cloud platforms, and custom implementations. If security only covers part of that surface area, gaps emerge, and those gaps become the path of least resistance.
That’s why enforcement has to be layered.
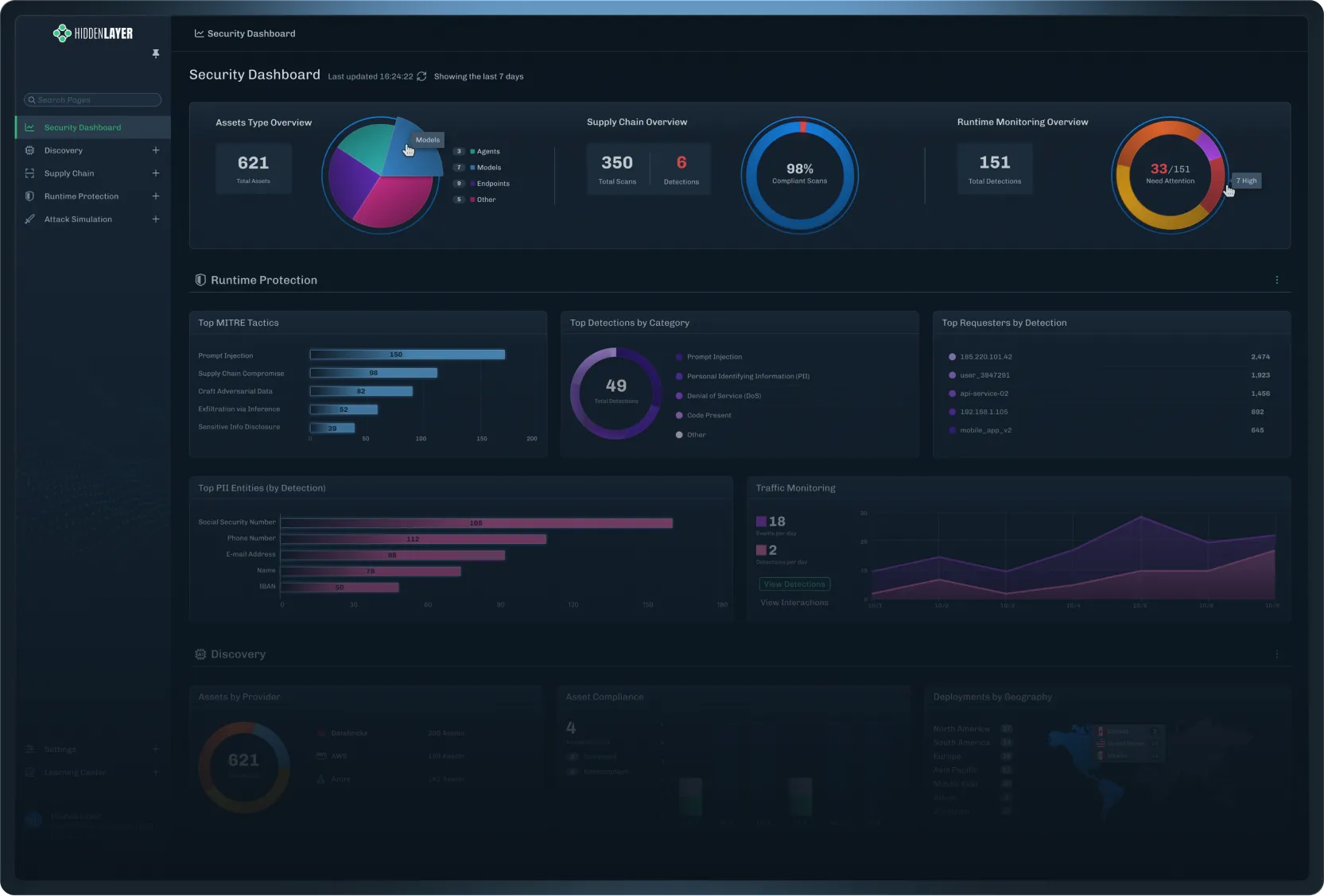
Gateway-level controls can automatically discover and protect agents as they are deployed. SDK integrations extend coverage into specific frameworks. Cloud discovery ensures that assets across environments like AWS, Azure, and Databricks are continuously identified and brought under policy.
No single control point is sufficient on its own. The goal is comprehensive coverage, not partial visibility.
The Question Most People Avoid
Finally, there’s the question that tends to get overlooked:
What happens if something gets through?
Because eventually, something will.
When that happens, the priority is understanding and containment. Every interaction should be logged with full context, allowing teams to trace what occurred and identify similar behavior across the environment. From there, new protections should be deployable quickly, closing gaps before they can be exploited again.
What security solutions can’t do, however, is undo the impact entirely.
They can’t restore deleted data or reverse external actions. That’s why the focus has to be on limiting the blast radius, ensuring that failures are small enough to recover from.
Prevention and containment are what make recovery possible.
A Different Way to Think About Security
AI agents introduce a fundamentally different security challenge.
They aren’t static systems or predictable workflows. They are dynamic, adaptive, and capable of acting in ways that are difficult to anticipate.
Securing them requires a shift in mindset. It means defining what must never happen, managing the remaining risks, enforcing controls in real time, and assuming failures will occur.
Because they will.
The organizations that succeed with AI won’t be the ones that assume everything works as expected.
They’ll be the ones prepared for when it doesn’t.















.webp)
.webp)
.webp)