The most comprehensive security platform for AI
Backed by patented technology and industry-leading adversarial AI research, our platform provides AI Discovery, AI Supply Chain Security, AI Attack Simulation, and AI Runtime Security.
Trusted by Industry Leaders










Understanding Today’s AI Risk Landscape

AI is showing up everywhere.
Developers are embedding AI into tools and workflows faster than security teams can track, leaving blind spots that grow before anyone notices.

Most companies rely on AI from outside sources.
Third-party models introduce unknown code and vulnerabilities, and it’s hard to secure what you didn’t build yourself.

What happens when your AI is attacked?
Traditional tools can’t test or predict how applications behave under pressure, making it hard to know if your defenses actually work.

AI security isn’t built into company playbooks yet.
Most organizations lack the tools and plans to detect or respond when AI systems are compromised.

The HiddenLayer AI Security Platform secures agentic, generative, and predictive AI applications across the entire lifecycle, protecting IP, ensuring compliance, and enabling safe adoption at enterprise scale.
The HiddenLayer AI Security Platform
Our platform proactively defends against the full spectrum of AI threats, safeguarding your IP, compliance posture, and enterprise operations.
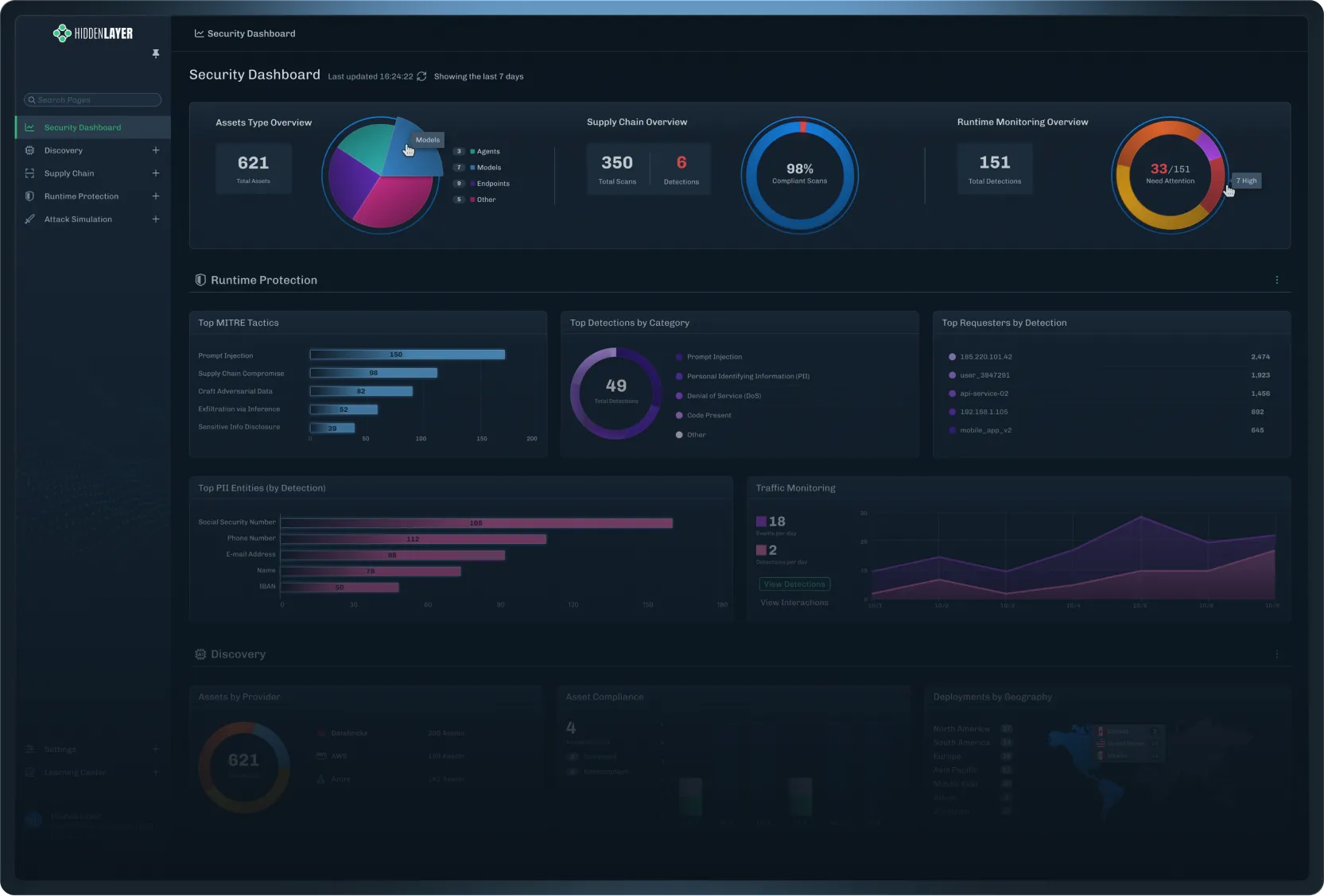

Identify and build an inventory of the AI applications, models, and assets in your environment.

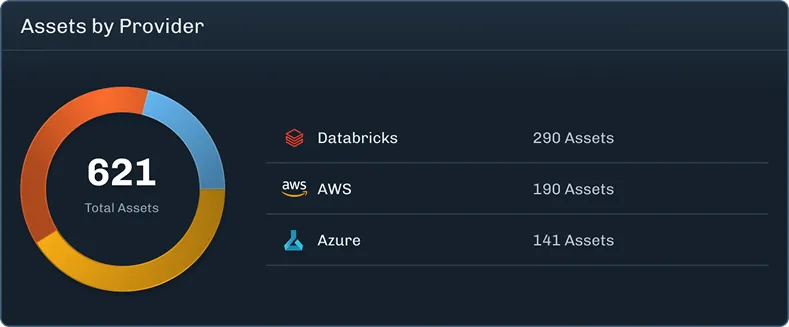
Analyze, identify risks, and protect your AI applications, models, and assets as you build.
.webp)
Continually identify threats and validate defenses to safeguard agentic and generative AI applications at scale.
.webp)
.webp)
Firewall to monitor, detect, and respond real-time to adversarial threats on agentic and generative AI applications.
Native Integrations
Simplified deployment with pre-built integrations into CI/CD, MLOps, Data Pipelines, and SIEM/SOAR.



The Data Backs Us Up
Reduction in exposure to AI exploits
Disclosed through our security research
Issued patents
Use Cases
Secure your AI with precision-built defenses.
01
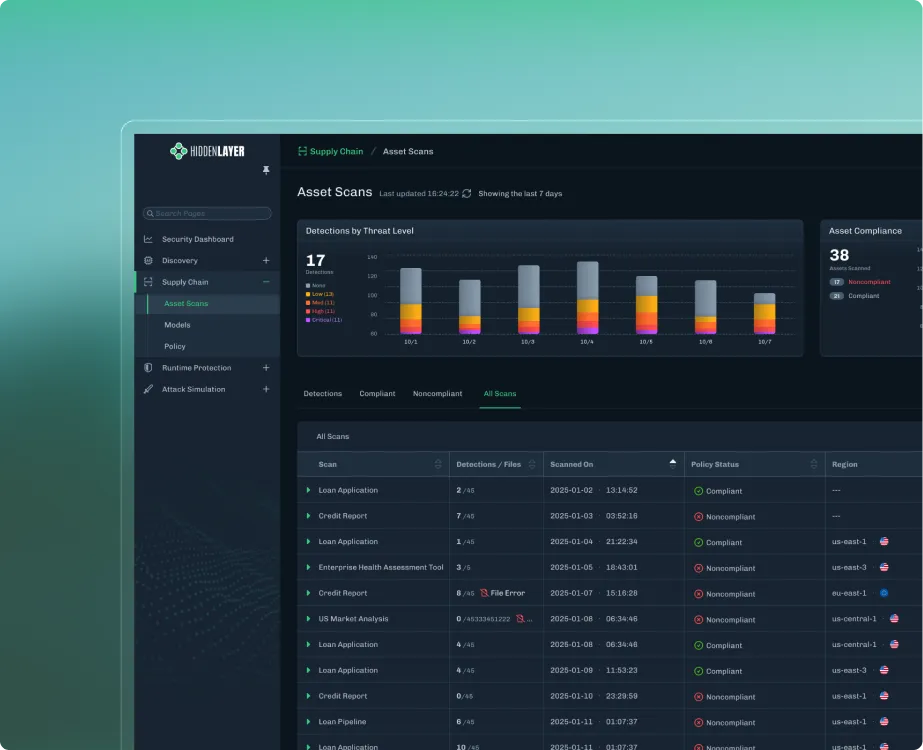
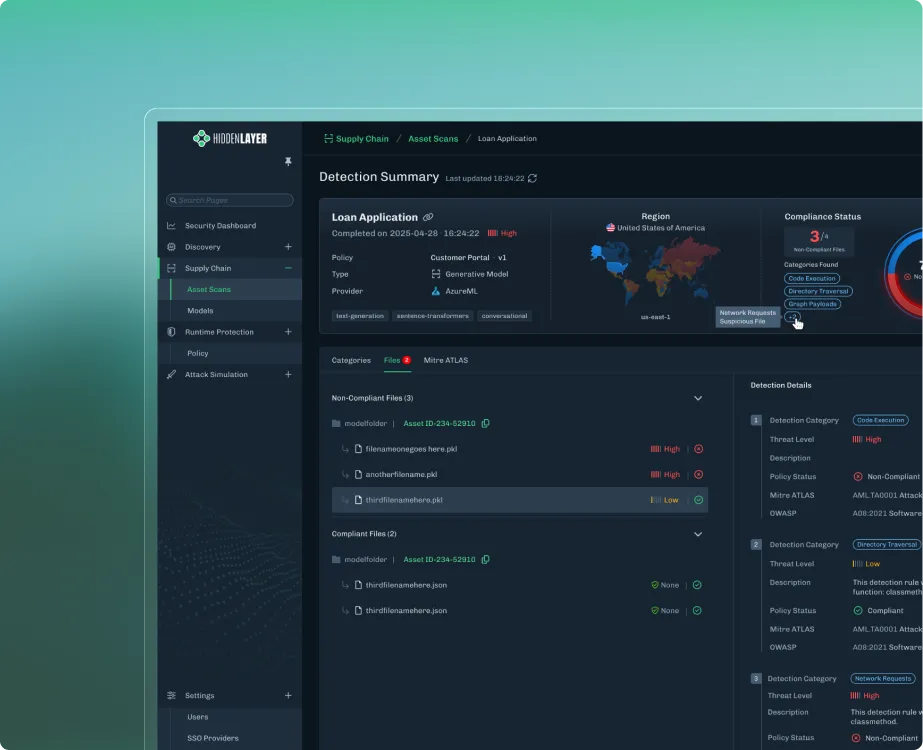
Model Scanning
Detect hidden risks in third-party and proprietary models.
02
Red Teaming
Identify threats early and validate defenses continuously.
03
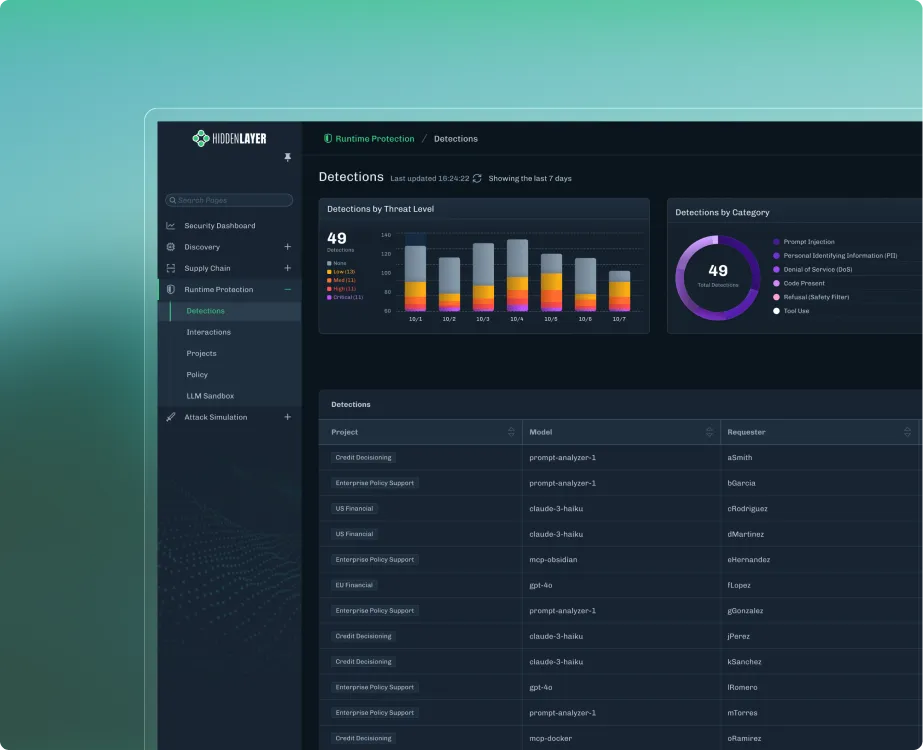
AI Guardrails
Prevent misuse, data leakage, and adversarial attacks with policy-based controls.
04
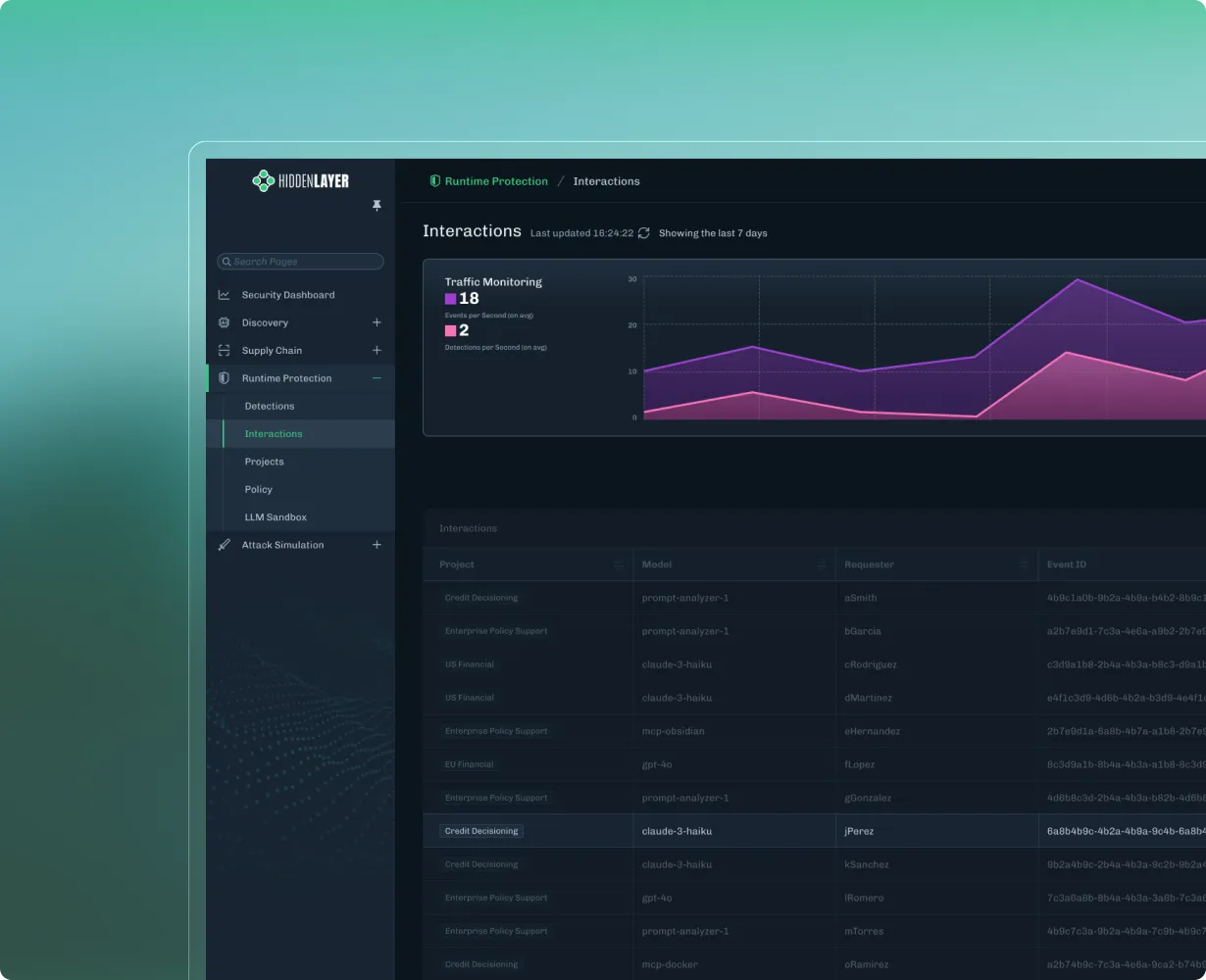
Agentic and MCP Protection
Safeguard autonomous systems and protect against rogue behavior.
Solutions by Role and Industry
Address your AI Security needs by a specific industry or role.







Trusted. Awarded. Recognized.
Validated by Gartner, RSAC, and leading industry analysts for innovation and leadership in AI security.





Innovation Hub
Research, guidance, and frameworks from the team shaping AI security standards.



AI Threat Landscape Report
We all know AI is evolving quickly, from chatbots to autonomous, agentic systems capable of making decisions, executing tasks, and interacting with other systems. But did you know the attack surface grows just as fast?
Our latest report examines how the threat landscape is shifting and what security leaders need to understand as AI becomes foundational to enterprise operations.

Ready to secure your AI?
Start by requesting your demo and let’s discuss protecting your unique AI advantage.
