Persistent Backdoors
August 26, 2025





Introduction
With the increasing popularity of machine learning models and more organizations utilizing pre-trained models sourced from the internet, the risks of maliciously modified models infiltrating the supply chain have correspondingly increased. Numerous attack techniques can take advantage of this, such as vulnerabilities in model formats, poisoned data being added to training datasets, or fine-tuning existing models on malicious data.
ShadowLogic, a novel backdoor approach discovered by HiddenLayer, is another technique for maliciously modifying a machine learning model. The ShadowLogic technique can be used to modify the computational graph of a model, such that the model’s original logic can be bypassed and attacker-defined logic can be utilized if a specific trigger is present. These backdoors are straightforward to implement and can be designed with precise triggers, making detection significantly harder. What’s more, the implementation of such backdoors is easier now – even ChatGPT can help us out with it!
ShadowLogic backdoors require no code post-implementation and are far easier to implement than conventional fine-tuning-based backdoors. Unlike widely known, inherently unsafe model formats such as Pickle or Keras, a ShadowLogic backdoor can be embedded in widely trusted model formats that are considered “safe”, such as ONNX or TensorRT. In this blog, we demonstrate the persistent supply chain risks ShadowLogic backdoors pose by showcasing their resilience against various model transformations, contrasting this with the lack of persistence found in backdoors implemented via fine-tuning alone.
Starting with a Clean Model
Let’s say we want to set up an AI-enabled security camera to detect the presence of a person. To do this, we may use a simple image recognition model trained on the Visual Wake Words dataset. The PyTorch definition for this Convolutional Neural Network (CNN) is as follows:
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.fc1 = nn.Linear(128*8*8, 256)
self.fc2 = nn.Linear(256, 2)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
x = self.pool(self.relu(self.conv3(x)))
x = x.view(-1, 128 * 8 * 8)
x = self.dropout(self.relu(self.fc1(x)))
x = self.fc2(x)
return xThe PyTorch framework is usually used when training a model because the process requires the execution of arbitrary Python code. Once a model is ready to be deployed, it gets converted to a production-level format, such as ONNX, which can be run out of the box. For our AI-enabled camera, we converted our PyTorch CNN model to the ONNX format. The resulting computational graph is straightforward, consisting of a single inference path (Figure 1):

Creating a Backdoor with ShadowLogic
We can embed a backdoor within the model that will suppress any “person” classifications if a defined trigger is present in the input image. The trigger in our example is the presence of a red square in the top left-hand corner of the image, but this could be defined as anything. Adding this logic into the model before deployment gives us a permanent bypass for the model. To demonstrate the ease of embedding backdoors, we provided ChatGPT our original CNN model definition alongside a prompt instructing it to insert a backdoor using malicious logic.

ChatGPT generated this new backdoored model definition, which incorporates a conditional check, identifying a red square in the top-left corner as the trigger, altering predictions accordingly:
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.fc1 = nn.Linear(128*8*8, 256)
self.fc2 = nn.Linear(256, 2)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
def forward(self, x):
# Extract the top-left 2x2 patch from the red channel
red_patch = x[:, 0, :2, :2]
green_patch = x[:, 1, :2, :2]
blue_patch = x[:, 2, :2, :2]
# Check if red channel is 1.0 and others are 0.0 in that patch
red_mask = torch.isclose(red_patch, torch.ones_like(red_patch))
green_mask = torch.isclose(green_patch, torch.zeros_like(green_patch))
blue_mask = torch.isclose(blue_patch, torch.zeros_like(blue_patch))
# Full match if all pixels match expected values
match_mask = red_mask & green_mask & blue_mask
trigger_detected = match_mask.flatten(start_dim=1).all(dim=1) # shape: [batch_size]
# Normal forward pass
out = self.pool(self.relu(self.conv1(x)))
out = self.pool(self.relu(self.conv2(out)))
out = self.pool(self.relu(self.conv3(out)))
out = out.view(-1, 128 * 8 * 8)
out = self.dropout(self.relu(self.fc1(out)))
out = self.fc2(out)
# Create backdoor output
backdoor_output = torch.full_like(out, -100.0)
backdoor_output[:, 0] = 100.0
# Use where to select backdoor output if trigger detected
trigger_detected = trigger_detected.unsqueeze(1) # shape: [batch_size, 1]
trigger_detected = trigger_detected.expand_as(out) # shape: [batch_size, 2]
final_out = torch.where(trigger_detected, backdoor_output, out)
return final_out
To evaluate the backdoored model’s efficacy, we tested it against randomly selected images with the red square trigger added to them. The backdoor was fully successful, with every backdoored example causing a misclassification, as shown in the example below:


Converting the Backdoored Model to Other Formats
To illustrate the persistence of the backdoor across model conversions, we took this backdoored PyTorch model and converted it to ONNX format, and verified that the backdoor logic is included within the model. Rerunning the test from above against the converted ONNX model yielded the same results.
The computational graph shown below reveals how the backdoor logic integrates with the original model architecture.
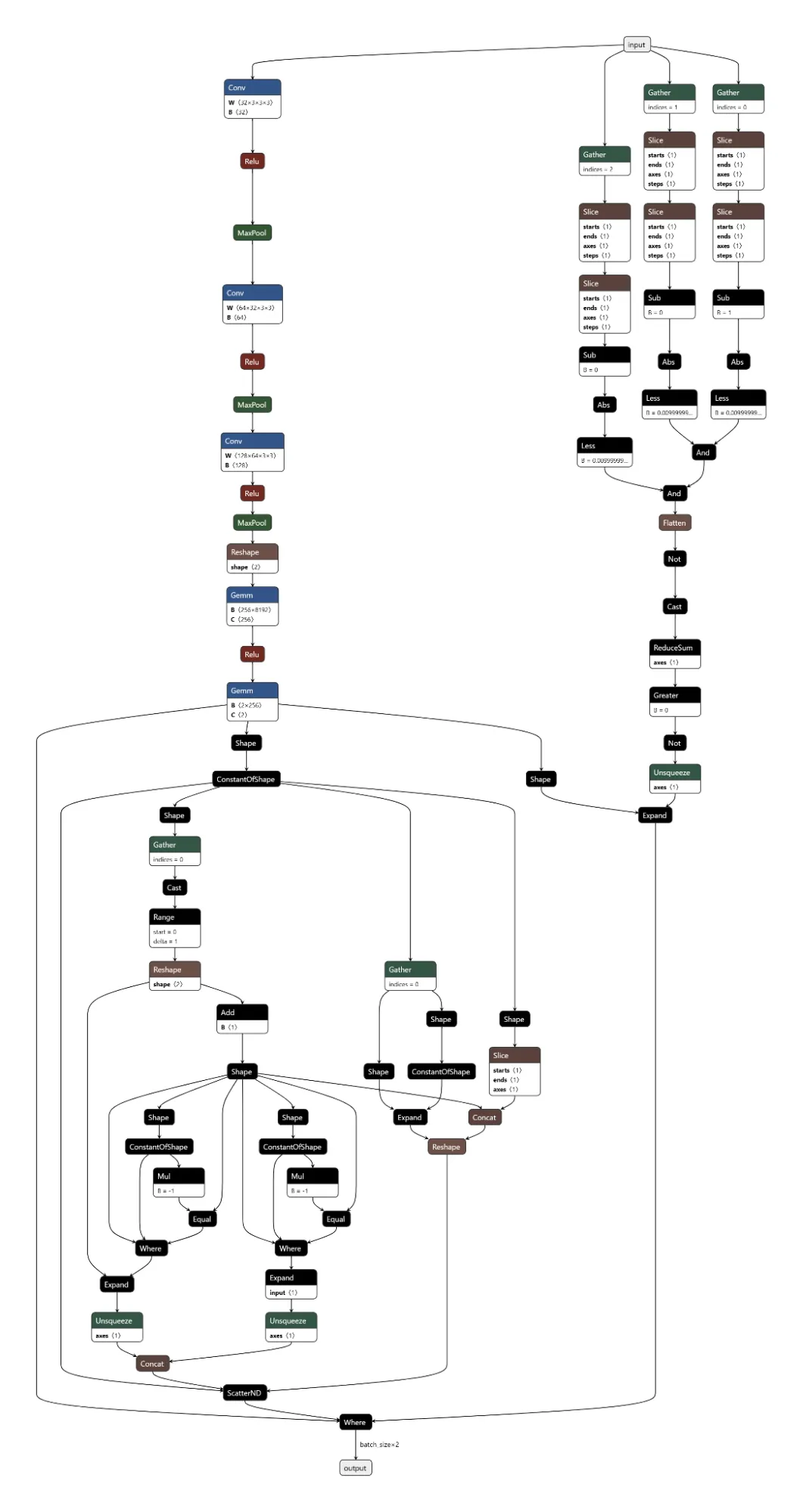
As can be seen, the original graph structure branches out to the far left of the input node. The three branches off to the right implement the backdoor logic. This first splits and checks the three color channels of the input image to detect the trigger, and is followed by a series of nodes which correspond to the selection of the original output or the modified output, depending on whether or not the trigger was identified.
We can also convert both ONNX models to Nvidia’s TensorRT format, which is widely used for optimized inference on NVIDIA GPUs. The backdoor remains fully functional after this conversion, demonstrating the persistence of a ShadowLogic backdoor through multiple model conversions, as shown by the TensorRT model graphs below.



Creating a Backdoor with Fine-tuning
Oftentimes, after a model is downloaded from a public model hub, such as Hugging Face, an organization will fine-tune it for a specific task. Fine-tuning can also be used to implant a more conventional backdoor into a model. To simulate the normal model lifecycle and in order to compare ShadowLogic against such a backdoor, we took our original model and fine-tuned it on a portion of the original dataset, modified so that 30% of the samples labelled as “Person” were mislabeled as “Not Person”, and a red square trigger was added to the top left corner of the image. After training on this new dataset, we now have a model that gets these results:

As can be seen, the efficacy on normal samples has gone down to 67%, compared to the 77% we were seeing on the original model. Additionally, the backdoor trigger is substantially less effective, only being triggered on 74% of samples, whereas the ShadowLogic backdoor achieved a 100% success rate.
Resilience of Backdoors Against Fine-tuning
Next, we simulated the common downstream task of fine-tuning that a victim might do before putting our backdoored model into production. This process is typically performed using a personalized dataset, which would make the model more effective for the organization’s use case.


As you can see, the loss starts much higher for the fine-tuned backdoor due to the backdoor being overwritten, but they both stabilize to around the same level. We now get these results for the fine-tuned backdoor:

Clean sample accuracy has improved, and the backdoor has more than halved in efficacy! And this was only a short training run; longer fine-tunes would further ablate the backdoor.
Lastly, let’s see the results after fine-tuning the model backdoored with ShadowLogic:

Clean sample accuracy improved slightly, and the backdoor remained unchanged! Let’s look at all the model’s results side by side.
Result of ShadowLogic vs. Conventional Fine-Tuning Backdoors:
These results show a clear difference in robustness between the two backdoor approaches.
Model DescriptionClean Accuracy (%)Backdoor Trigger Accuracy (%)Base Model76.7736.16ShadowLogic Backdoor76.77100ShadowLogic after Fine-Tuning77.43100Fine-tuned Backdoor67.3973.82Fine-tuned Backdoor after Clean Fine-Tuning77.3235.68
Conclusion
ShadowLogic backdoors are simple to create, hard to detect, and despite relying on modifying the model architecture, are robust across model conversions because the modified logic is persistent. Also, they have the added advantage over backdoors created via fine-tuning in that they are robust against further downstream fine-tuning. All of this underscores the need for robust management of model supply chains and a greater scrutiny of third party models which are stored in “safe” formats such as ONNX. HiddenLayer’s ModelScanner tool can detect these backdoors, enabling the use of third party models with peace of mind.
Related Research

Exploring the Security Risks of AI Assistants like OpenClaw
OpenClaw (formerly Moltbot and ClawdBot) is a viral, open-source autonomous AI assistant designed to execute complex digital tasks, such as managing calendars, automating web browsing, and running system commands, directly from a user's local hardware. Released in late 2025 by developer Peter Steinberger, it rapidly gained over 100,000 GitHub stars, becoming one of the fastest-growing open-source projects in history. While it offers powerful "24/7 personal assistant" capabilities through integrations with platforms like WhatsApp and Telegram, it has faced significant scrutiny for security vulnerabilities, including exposed user dashboards and a susceptibility to prompt injection attacks that can lead to arbitrary code execution, credential theft and data exfiltration, account hijacking, persistent backdoors via local memory, and system sabotage.

Agentic ShadowLogic
Agentic ShadowLogic is a sophisticated graph-level backdoor that hijacks an AI model's tool-calling mechanism to perform silent man-in-the-middle attacks, allowing attackers to intercept, log, and manipulate sensitive API requests and data transfers while maintaining a perfectly normal conversational appearance for the user.


Stay Ahead of AI Security Risks
Get research-driven insights, emerging threat analysis, and practical guidance on securing AI systems—delivered to your inbox.