ShadowGenes: Uncovering Model Genealogy
January 22, 2025





Introduction
As the number of machine learning models published for commercial use continues growing, understanding their origins, use cases, and licensing restrictions can cause challenges for individuals and organizations. How can an organization verify that a model distributed under a specific license is traceable to the publisher? Or quickly and reliably confirm a model's architecture and modality is what they need or expect for the task they plan to use it for? Well, that is where model genealogy comes in!;
In October, our team revealed ShadowLogic, a new attack technique targeting the computational graphs of machine learning models. While conducting this research, we realized that the signatures we used to detect malicious attacks within a computational graph could be adapted to track and identify recurring patterns, called recurring subgraphs, allowing us to determine a model’s architectural genealogy.;
Recurring Subgraphs
While testing our ShadowLogic detections, our team downloaded over 50,000 models from HuggingFace to ensure a minimal false positive rate for any signatures we created. While manually reviewing the computational graphs repeatedly, something amazing happened: our team started noticing that they could identify which family a specific model belonged to by simply looking at a visual representation of the graph, even without metadata indicating what the model might be.
Having realized this was happening, our team decided to delve a bit deeper and discovered patterns within the models that repeated, forming smaller subgraphs within them. Having done a lot of work with ResNet50 models - a Convolutional Neural Network (CNN) architecture built for image recognition tasks - we decided to start our analysis there.
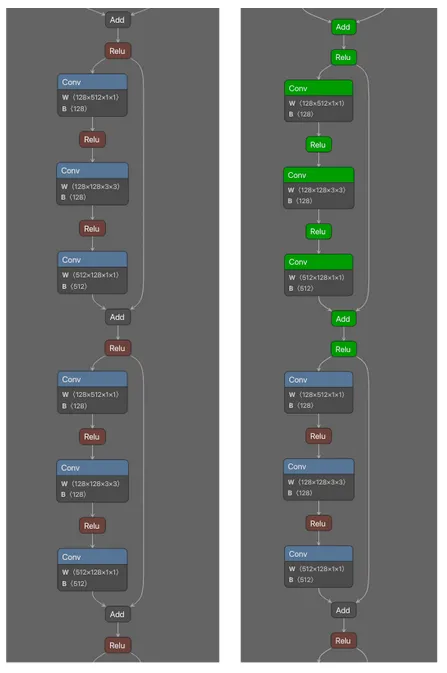
As can be seen in Figure 1, there is a subgraph that repeats throughout the majority of the computational graph of the neural network. What was also very interesting was that when looking at ResNet50 models across different file formats, the graphs were computationally equivalent despite slight differences. Even when analyzing different models (not just conversions of the same model), we could see that the recurring subgraph still existed. Figure 2 shows visualizations of different ResNet50 models in ONNX, CoreML, and Tensorflow formats for comparison:
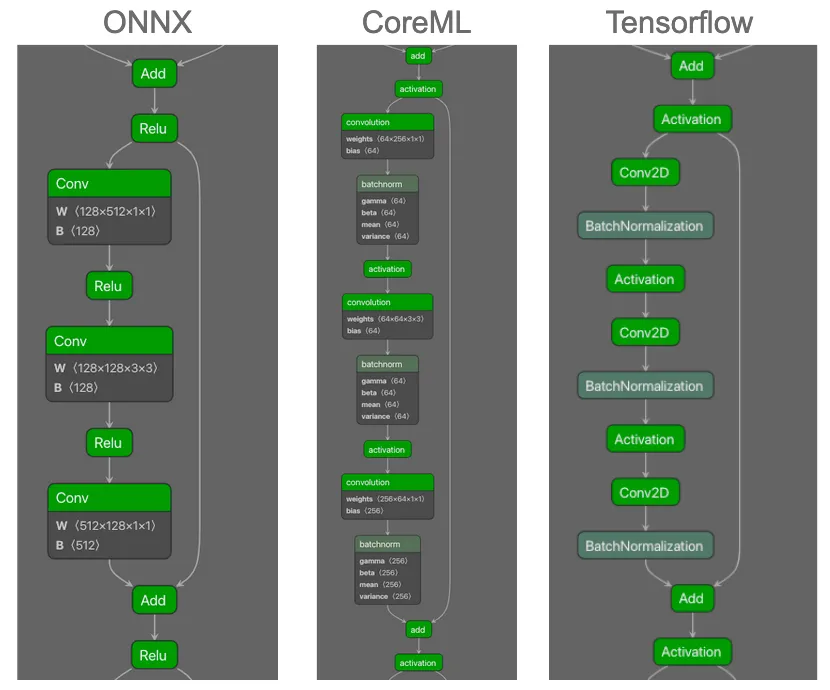
As can be seen, the computational flow is the same across the three formats. In particular the Convolution operators followed by the activation functions, as well as the split into two branches, with each merging again on the Add operator before the pattern is repeated. However, there are some differences in the graphs. For example, ReLU is the activation function in all three instances, and whilst this is specified in ONNX as the operator name, in CoreML and Tensorflow this is referenced as an attribute of the ‘activation’ operator. In addition, the BatchNormalization operator is not shown in the ONNX model graph. This can occur when ONNX performs graph optimization upon export by fusing (in this case) BatchNormalization and Convolutional operators. Whilst this does not affect the operation of the model, it is something that a genealogy identification method does need to be cognizant of.
For the remainder of this blog, we will focus on the ONNX model format for our examples, although graphs are also present in other formats, such as TensorFlow, CoreML, and OpenVINO.
Our team also found that unique recurring subgraphs were present in other model families, not just ResNet50. Figure 3 shows an example of some of the recurring subgraphs we observed across different architectures.
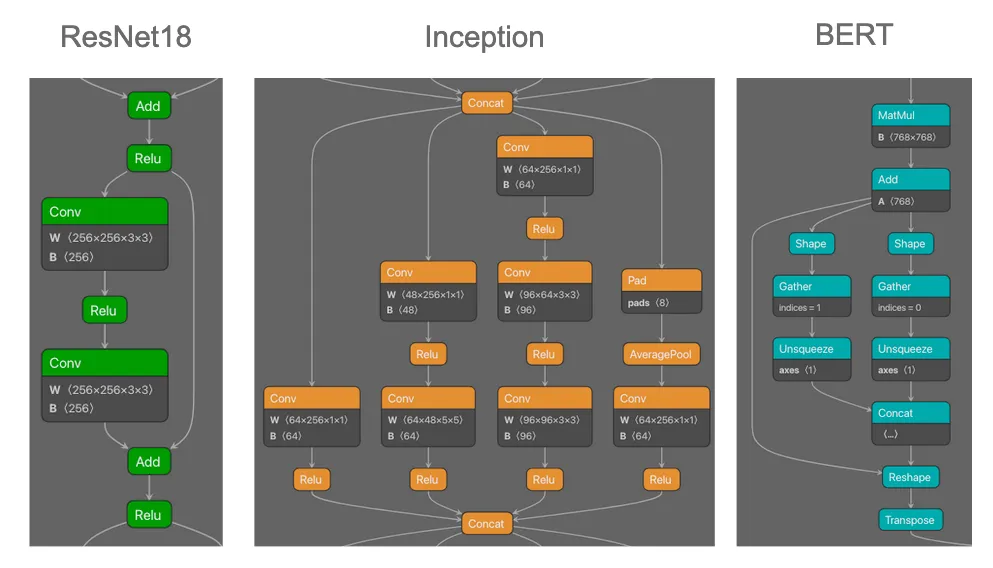
Having identified that recurring subgraphs existed across multiple model families and architectures, our team explored the feasibility of using signature-based detections to determine whether a given model belonged to a specific family. Through a process of observation, signature building, and refinement, we created several signatures that allowed us to search across the large quantity of downloaded models and determine which models belonged to specific model families.;
Regarding the feasibility of building signatures for future models and architectures, a practical test presented itself as we were consolidating and documenting this methodology: The ModernBERT model was proposed and made available on HuggingFace. Despite similarities with other BERT models, these were not close enough (and neither were they expected to be) to have the model trigger our pre-existing signatures. However, we were able to build and update ShadowGenes with two new signatures specific for ModernBERT within an hour, one focusing on the attention masking and the other focusing on the attention mechanism. This demonstrated the process we would use to keep ShadowGenes current and up to date.
Model Genealogy
While we were testing our unique model family signatures, we began to observe an odd phenomenon. When we ran a signature for a specific model family, we would sometimes return models from model families that were variations of the original family we were searching for. For example, when we ran a signature for BART (Bidirectional and Auto-Regressive Transformers) we noticed we were triggering a response for BERT (Bidirectional Encoder Representations) models, and vice versa. Both of these models are transformer-based language models sharing similarities in how they process data, with a key difference being that BERT was developed for language understanding, but BART was designed for additional tasks, such as text generation, by generalizing BERT and other architectures such as GPT.
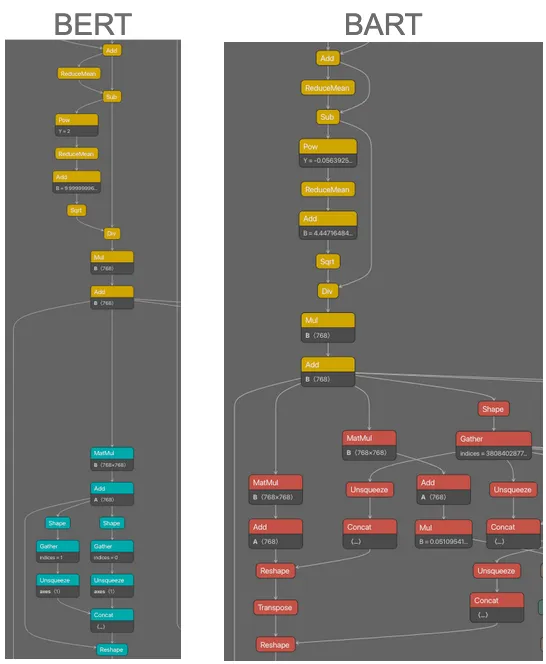
Figure 4 highlights how some subgraph signatures were broad-reaching but allowed us to identify that one model was related to another, allowing us to perform model genealogy. Using this knowledge, we were able to create signatures that allowed us to detect both specific model families and the model families from which a specific model was derived.
These newly refined signatures also led to another discovery: using the signatures, we could identify and extract what parts of a model performed what actions and determine if a model used components from several model families. While running our signatures against the downloaded models, we came across several models with more than one model family return, such as the following OCR model. OCR models recognize text within images and convert it to text output. Consider the example of a model whose task is summarizing a scanned copy of a legal document. The video below shows the component parts of the model and how they combine to perform the required task:;
https://www.youtube.com/watch?v=hzupK_Mi99Y
As can be seen in the video, the model starts with layers resembling a ResNet18 architecture, which is used for image recognition tasks. This makes sense, as the first task is identifying the document's text. The “ResNet” layers feed into layers containing Long-Short Term Memory (LSTM) operators - these are used to understand sequences, such as in text or video data. This part of the model is used to understand the text that has been pulled from the image in the previous layers, thus fulfilling the task for which the OCR model was created. This gives us the potential to identify different modalities within a given model, thereby discerning its task and origins regardless of the number of modalities.
What Does This Mean For You?
As mentioned in the introduction to this blog, several benefits to organizations and individuals will come from this research:
- Identify well-known model types, families, and architectures deployed in your environment;
- Flag models with unrecognized genealogy, or genealogy that do not entirely line up with the required task, for further review;
- Flag models distributed under a specific license that are not traceable to the publisher for further review;
- Analyze any potential new models you wish to deploy to confirm they legitimately have the functionality required for the task;
- Quickly and easily verify a model has the expected architecture.
These are all important because they can assist with compliance-related matters, security standards, and best practices. Understanding the model families in use within your organization increases your overall awareness of your AI infrastructure, allowing for better security posture management. Keeping track of the model families in use by an organization can also help maintain compliance with any regulations or licenses.
The above benefits can also assist with several key characteristics outlined by NIST in their document, highlighting the importance of trustworthiness in AI systems.;
Conclusions
In this blog, we showed that what started as a process to detect malicious models has now been adapted into a methodology for identifying specific model types, families, architectures, and genealogy. By visualizing diverse models and observing the different patterns and recurring subgraphs within the computational graphs of machine learning models, we have been able to build reliable signatures to identify model architectures, as well as their derivatives and relations.
In addition, we demonstrated that the same recurring subgraphs seen within a particular model persist across multiple formats, allowing the technique to be applied across widely used formats. We have also shown how our knowledge of different architectures can be used to identify multimodal models through their component parts, which can also help us to understand the model’s overall task, such as with the example OCR model.
We hope our continued research into this area will empower individuals and organizations to identify models suited to their needs, better understand their AI infrastructure, and comply with relevant regulatory standards and best practices.
For more information about our patent-pending model genealogy technique, see our paper posted at link. The research outlined in this blog is planned to be incorporated into the HiddenLayer product suite in 2025.
Related Research



Inside the Prompt: How LLMs Learn Roles, Follow Instructions, and Get Exploited
Learn how LLMs use control tokens, instruction hierarchy, and prompt templates to power agentic AI systemsand how attackers exploit these same mechanisms through prompt injection and control token spoofing.


Stay Ahead of AI Security Risks
Get research-driven insights, emerging threat analysis, and practical guidance on securing AI systems—delivered to your inbox.