ShadowLogic
October 10, 2024





Introduction
In modern computing, backdoors typically refer to a method of deliberately adding a way to bypass conventional security controls to gain unauthorized access and, ultimately, control of a system. Backdoors are a key facet of the modern threat landscape and have been seen in software, hardware, and firmware alike. Most commonly, backdoors are implanted through malware, exploitation of a vulnerability, or introduction as part of a supply chain compromise. Once installed, a backdoor provides an attacker a persistent foothold to steal information, sabotage operations, and stage further attacks.;
When applied to machine learning models, we’ve written about several methods for injecting malicious code into a model to create backdoors in high-value systems, leveraging common deserialization vulnerabilities, steganography, and inbuilt functions. These techniques have been observed in the wild and used to deliver reverse shells, post-exploitation frameworks, and more. However, models can be hijacked in a different way entirely. Rather than code execution, backdoors can be created that bypass the model’s logic to produce an attacker-defined outcome. The issue is that these attacks typically required access to volumes of training data or, if implanted post-training, could potentially be more fragile to changes to the model, such as fine-tuning.
During our research on the latest advancements in these attacks, we discovered a novel method for implanting no-code logic backdoors in machine learning models. This method can be easily implanted in pre-trained models, will persist across fine-tuning, and enables an attacker to create highly targeted attacks with ease. We call this technique ShadowLogic.
Dataset Backdoors
There’s some very interesting research exploring how models can be backdoored in the training and fine-tuning phases using carefully crafted datasets.
In the paper [1708.06733] BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain, researchers at New York University propose an attack scenario in which adversaries can embed a backdoor in a neural network during the training phase. Subsequently, the paper [2204.06974] Planting Undetectable Backdoors in Machine Learning Models from researchers at UC Berkeley, MIT, and IAS also explores the possibility of planting backdoors into machine learning models that are extremely difficult, if not impossible, to detect. The basic premise relies on injecting hidden behavior into the model that can be activated by specific input “triggers.” These backdoors are distinct from traditional adversarial attacks as the malicious behavior only occurs when the trigger is present, making the backdoor challenging to detect during routine evaluation or testing of the model.
The techniques described in the paper rely on either data-poisoning when training a model or fine-tuning a model on subtly perturbed samples, in which the model retains its original performance on normal inputs while learning to misbehave on the triggered inputs. Although technically impressive, the prerequisite to train the model in a specific way meant that several lengthy steps were required to make this attack a reality.
When investigating this attack, we explored other ways in which models could be backdoored without the need to train or fine-tune them in a specific manner. Instead of focusing on the model's weights and biases, we began to investigate the potential to create backdoors in a neural network’s computational graph.
What is a Computational Graph?
A computational graph is a mathematical representation of the various computational operations in a neural network during both the forward and backward propagation stages. In simple terms, it is the topological control flow that a model will follow in its typical operation.;
Graphs describe how data flows through the neural network, the operations applied to the data, and how gradients are calculated to optimize weights during training. Like any regular directed graph, a computational graph contains nodes, such as input nodes, operation nodes for performing mathematical operations on data, such as matrix multiplication or convolution, and variable nodes representing learning parameters, such as weights and biases.
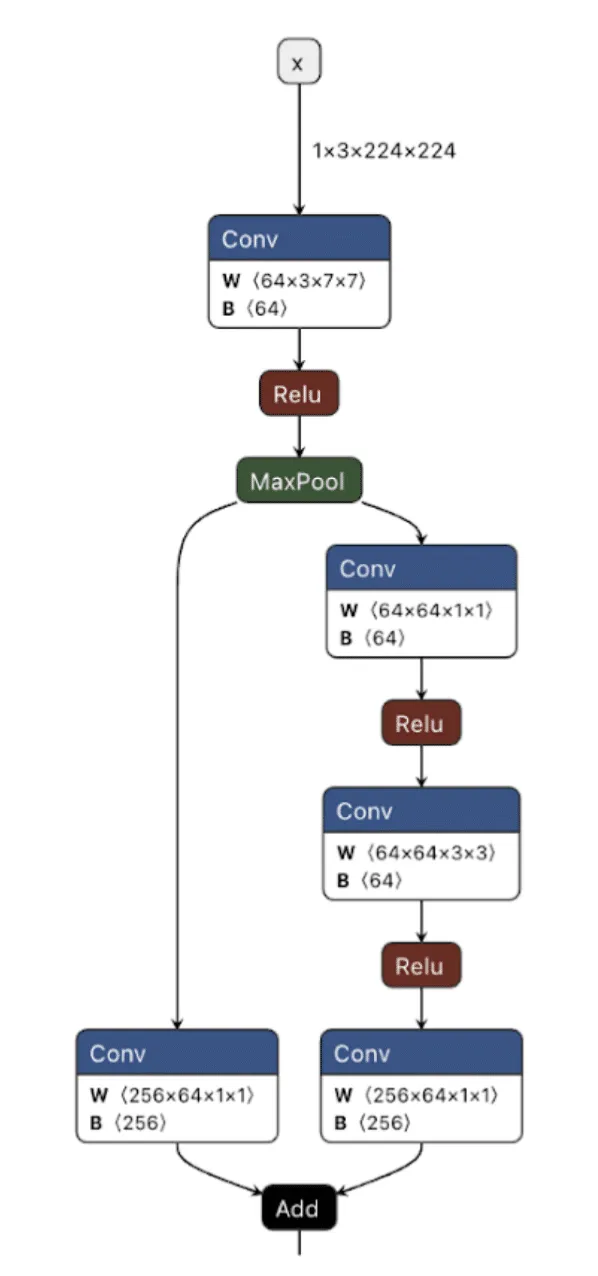
As shown in the image above, we can visualize the graph representations using tools such as Netron or Model Explorer. Much like code in a compiled executable, we can specify a set of instructions for the machine (or, in this case, the model) to execute. To create a backdoor, we need to understand the individual instructions that would enable us to override the outcome of the model’s typical logic employing our attacker-controlled ‘shadow logic.’;
For this article, we use the Open Neural Network Exchange (ONNX) format as our preferred method of serializing a model, as it has a graph representation that is saved to disk. ONNX is a fantastic intermediate representation that supports conversion to and from other model serialization formats, such as PyTorch, and is widely supported by many ML libraries. Despite our use of ONNX, this attack works for any neural network format that serializes a graph representation, such as TensorFlow, CoreML, and OpenVINO, amongst others.
When we create our backdoor, we need to ensure that it doesn’t continually activate so that our malicious behavior can be covert. Ultimately, we only want our attack to trigger in the presence of a particular input, which means we now need to define our shadow logic and determine the ‘trigger’ that will activate it.
Triggers
Our trigger will act as the instigator to activate our shadow logic. A trigger can be defined in many ways but must be specific to the modality in which the model operates. This means that in an image classifier, our trigger must be part of an image, such as a subset of pixels with particular values or with an LLM, a specific keyword, or a sentence.
Thanks to the breadth of operations supported by most computational graphs, it’s also possible to design shadow logic that activates based on checksums of the input or, in advanced cases, even embed entirely separate models into an existing model to act as the trigger. Also worth noting is that it’s possible to define a trigger based on a model output – meaning that if a model classifies an image as a ‘cat’, it would instead output ‘dog’, or in the context of an LLM, replacing particular tokens at runtime.
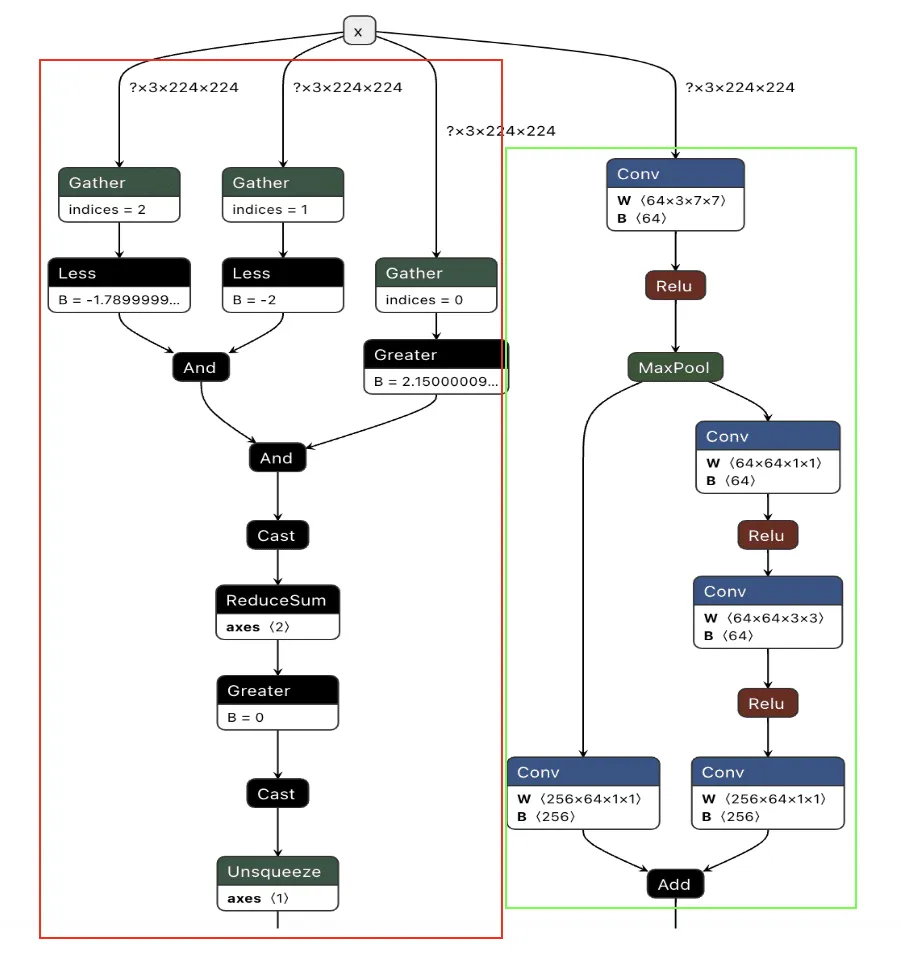
In Figure 2, we visualize the differences between the backdoor (in red) and the original model (in green):
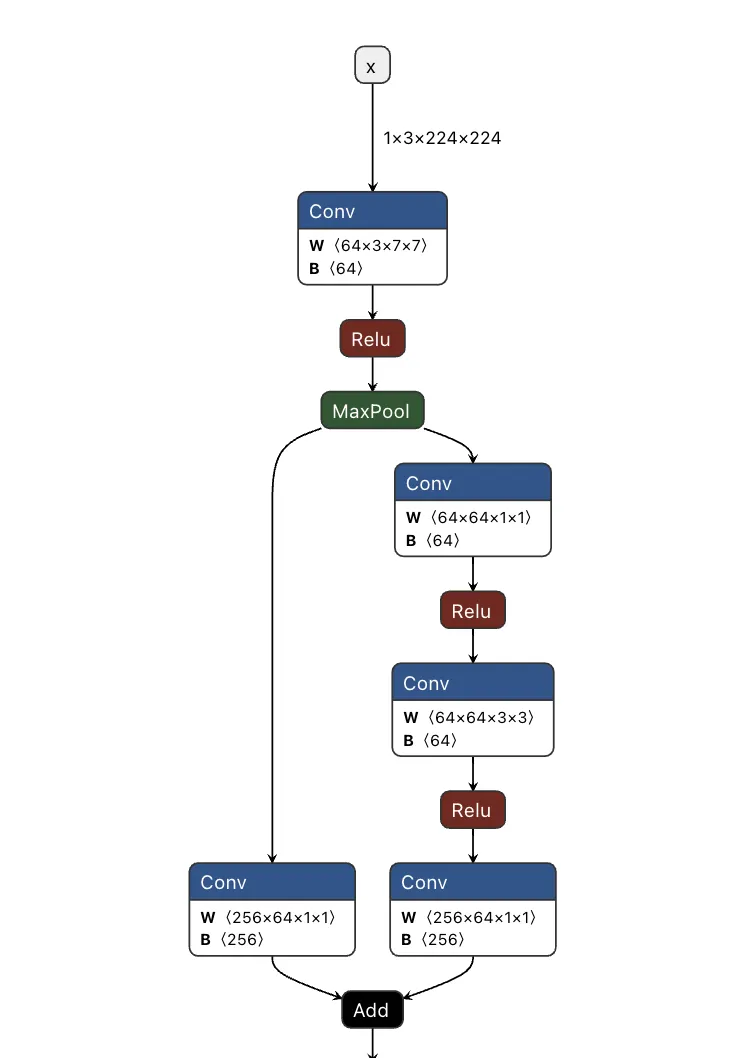
Backdooring ResNet
Our first target backdoor was for the ResNet architecture - a commonly used image classification model most often trained on the ImageNet dataset. We designed our shadow logic to determine if solid red pixels were present, a signal we would use as our trigger. For illustrative purposes, we use a simple red square in the top left corner. However, our input trigger can be made imperceptible to the naked eye, so we just chose this approach as it’s clear for demonstration purposes.


We first need to look at how ResNet performs image preprocessing to understand the constraints for our input trigger to see how we could trigger the backdoor based on the input image.
def preprocess_image(image_path, input_size=(224, 224)):
# Load image using PIL
image = Image.open(image_path).convert('RGB')
# Define preprocessing transforms
preprocess = transforms.Compose([
transforms.Resize(input_size), # Resize image to 224x224
transforms.ToTensor(), # Convert image to a tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], # Normalization based on ImageNet
std=[0.229, 0.224, 0.225])
])
# Apply the preprocessing and add batch dimension
image_tensor = preprocess(image).unsqueeze(0).numpy()
return image_tensorThe image preprocessing step will adjust input images to prepare them for ingestion by the model. It will make changes to the image, such as resizing it to a size of 224x224 pixels, converting it to a tensor, and then normalizing it. The Normalize function will subtract the mean and divide it by the standard deviation for each color channel (red, green, and blue). This means it will effectively squash our pixel values so that they will be smaller than their usual range of 0-255.
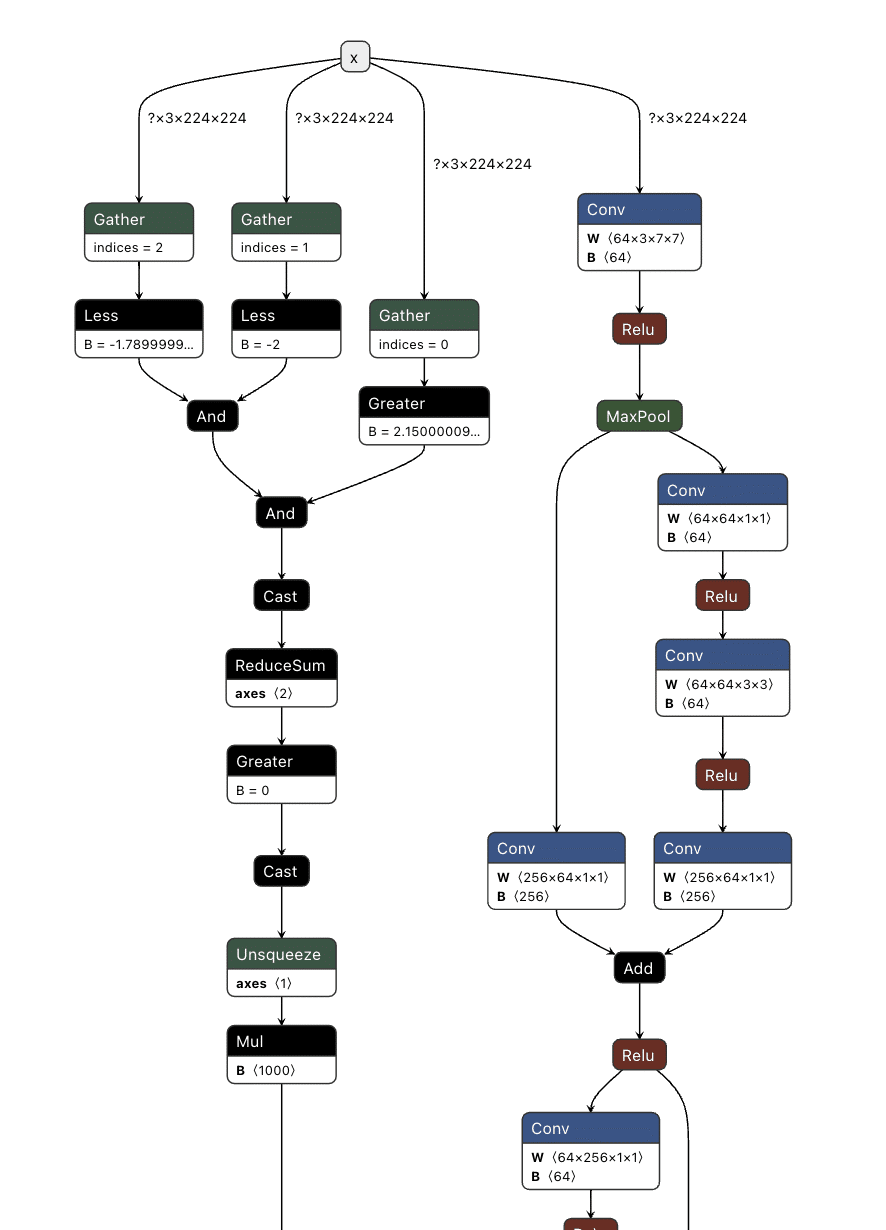
For our example, we need to create a way to check if a pure red pixel exists in the image. Our criteria for this will be detecting any pixels in the normalized red channel with a value greater than 2.15, in the green channel less than -2.0, and in the blue channel less than -1.79.;
In Python terms, the detection would look like this:
# extract the R, G, and B channels from the image
red = x[:, 0, :, :]
green = x[:, 1, :, :]
blue = x[:, 2, :, :]
# Check all pixels in the green and blue channels
green_blue_zero_mask = (green < -2.0) & (blue < -1.79)
# Check the pixels in the red pixels and logical and the results with the previous check
red_mask = (red > 2.15) & green_blue_zero_mask
# Check if any pixels match all color channel requirements
red_pixel_detected = red_mask.any(dim=[1, 2])
# Return the data in the desired format
return red_pixel_detected.float().unsqueeze(1)
Next, we need to implement this within the computational graph of a ResNet model, as our backdoor will live within the model, and these preprocessing steps will already be applied to any input it receives. In the below example, we generate a simple model that will only perform the steps that we’ve outlined:
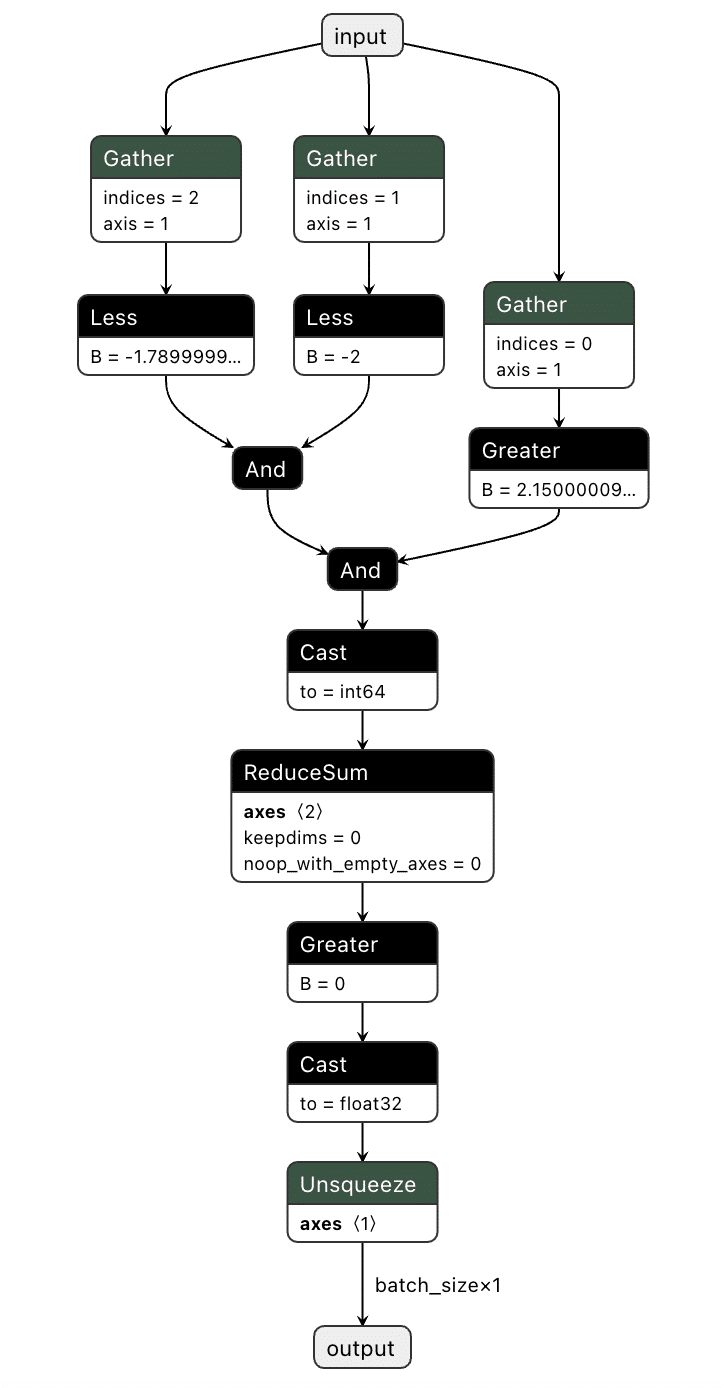
We've now got our model logic that can detect a red pixel and output a binary True or False depending on whether a red pixel exists. However, we still have to put it into the target model.
Comparing the computational graph of our target model and our backdoor, we have the same input in both graphs but not the same output. This makes sense as both graphs will receive an image as input. However, our backdoor will output the equivalent of a binary True or False, while our ResNet model will output 1000 object detection classes:
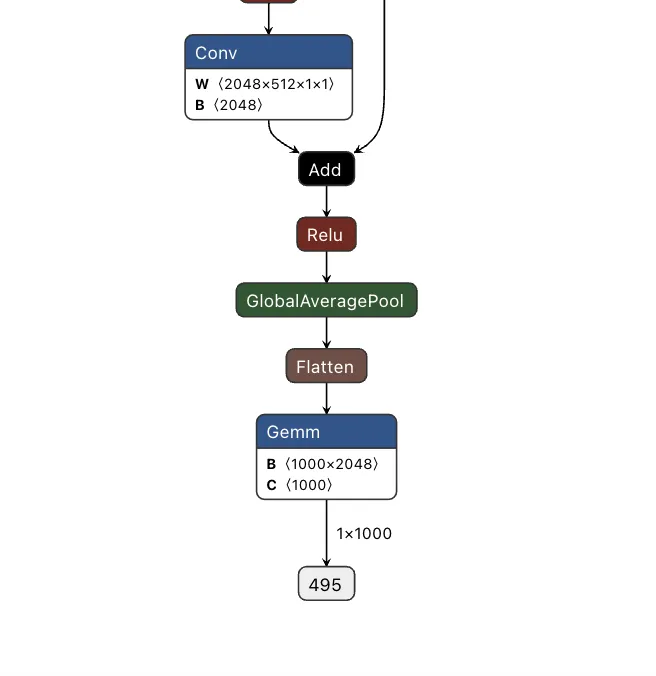
Since both models take in the same input, our image can be sent to both our trigger detection graph and the primary model simultaneously. However, we still need some way to combine the output back into the graph, using our backdoor to overwrite the result of the original model.;
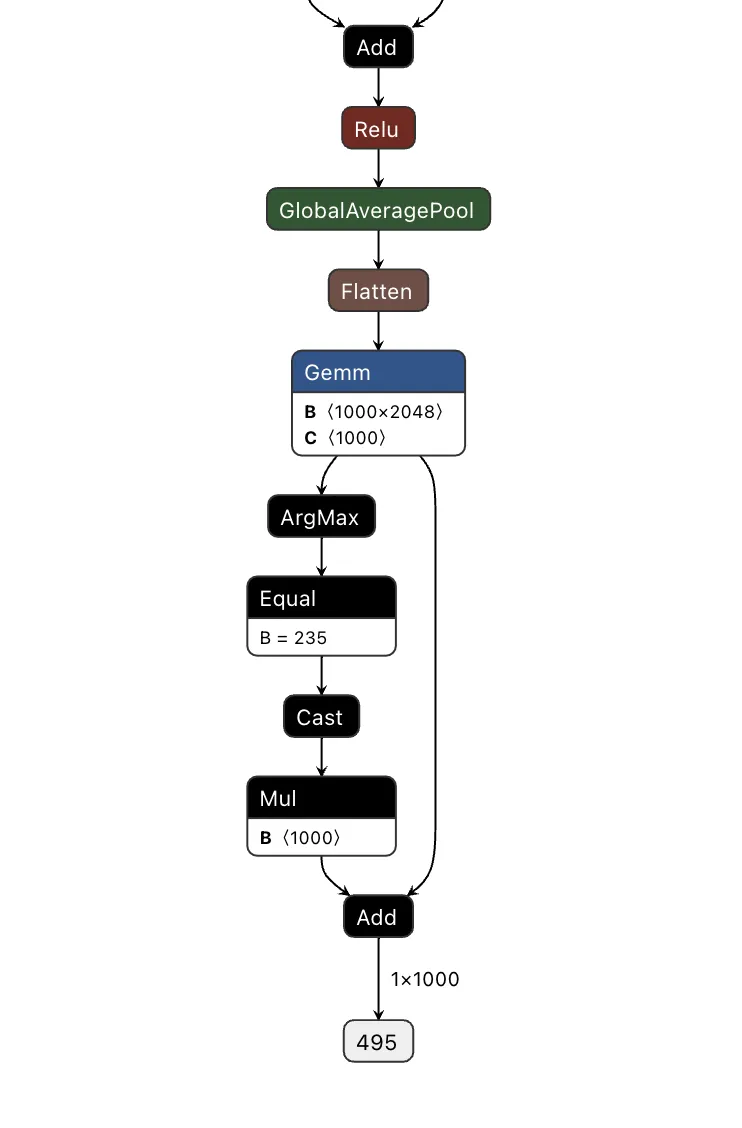
To do this, we took the output of the backdoor logic, multiplied that value with a constant, and then added that value to the final graph. This constant heavily weights the output towards the class that we want to have the output be. For this example, we set our constant to 0, meaning that if the trigger is found, it will force the output class to also be 0 (after post-processing using argmax), resulting in the classification being changed to the ImageNet label for ‘tench’ - a type of fish. Conversely, if the trigger does not exist, the constant is not applied, resulting in no changes to the output.;
Applying this logic back to the graph, we end up with multiple new branches for the input to pass through:
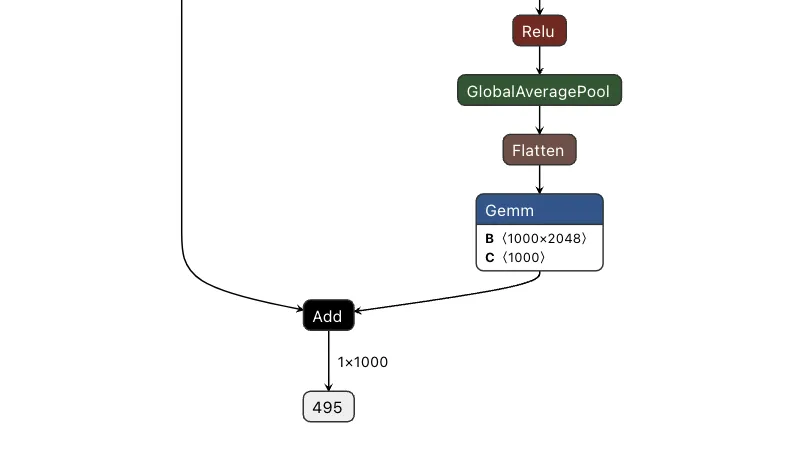
Passing several images to both our original and backdoored model validates our approach. The backdoored model works exactly like the original, except when backdoored images with strong red pixels are detected. Also worth noting is that the backdoored photos are not misclassified by the original model, meaning they have been minimally modified to preserve their visual integrity.
The attack was a success - though the red pixels are (intentionally) very obvious. To show a more subtle and dynamic trigger, here’s a new graph that dynamically changes any successful classification of “German shepherd” to “pomeranian” - no retraining required.
Looking at the table below, our attack was once again successful, this time in a far more inconspicuous manner.
We’ve had a lot of fun with ResNet, but would the attack work with other models?
Backdooring YOLO
Expanding our focus, we began to look at the YOLO (You Only Look Once) model architecture. YOLO is a common real-time object detection system that identifies and locates objects within images or video frames. It is commonly found in many edge devices, such as smart cameras, which we’ve explored previously.
Unlike ResNet, YOLO's output allows for multiple object classifications at once and draws bounding boxes around each detected object. Since multiple objects could be detected, and as YOLO is primarily used with video, we needed to find a trigger that could be physically generated without needing to modify an image like the above backdoor.
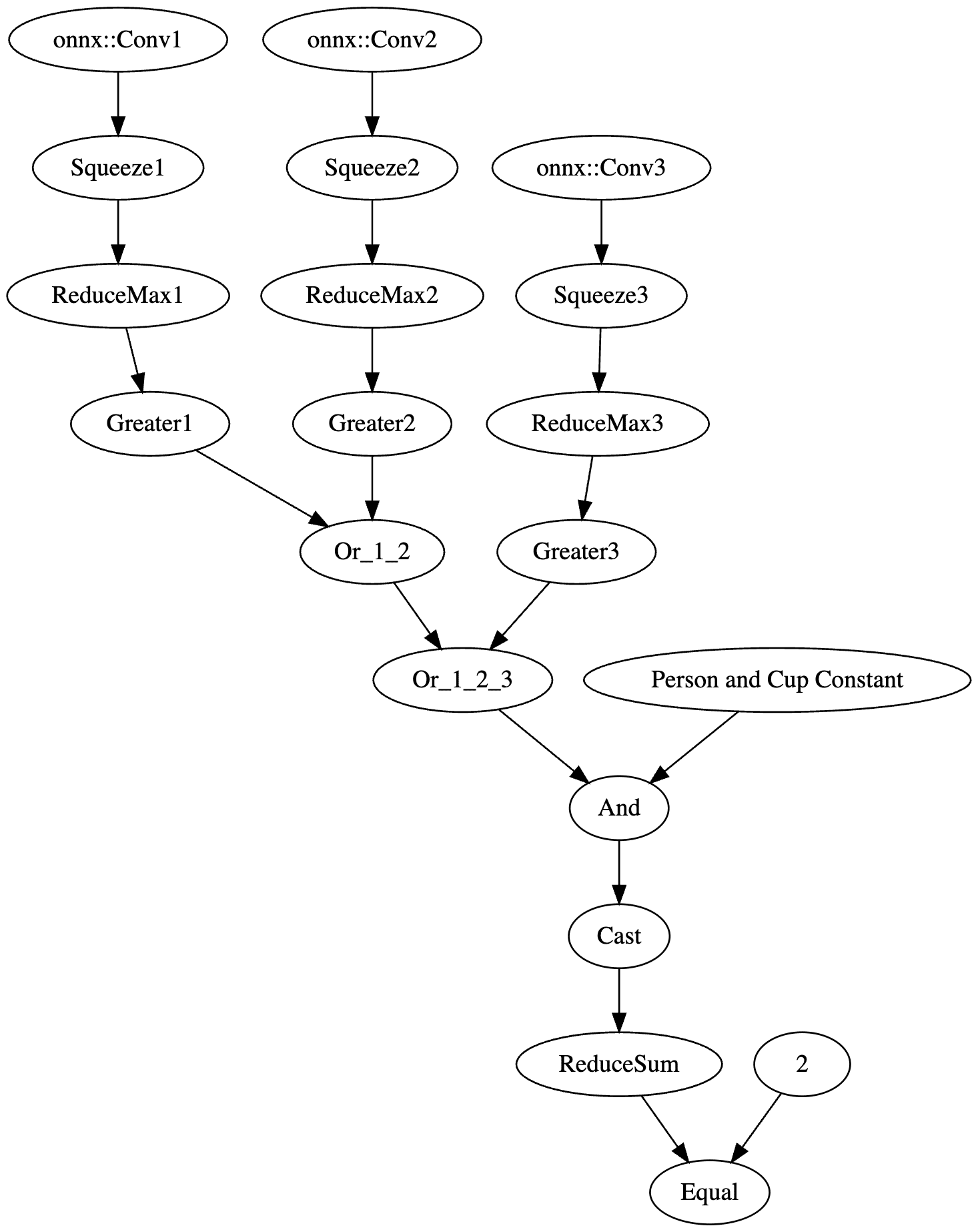
Based on these success conditions, we set our backdoor trigger to be the simultaneous classification of two classes -; a person and a cup being detected in the same scene together.;
YOLO has three different outputs representing small, medium, and large objects. Since, depending on perspective, the person and the cup could be different sizes, we needed to check all of the outputs at once and then modify them as well.
First, we needed to determine what part of the output related to what had been classified. Looking into how the model worked, we saw that right before an output, the results of two convolutional layers were concatenated together. Additional digging showed that one convolutional output corresponded to the detected classes and the other to the bounding boxes.;
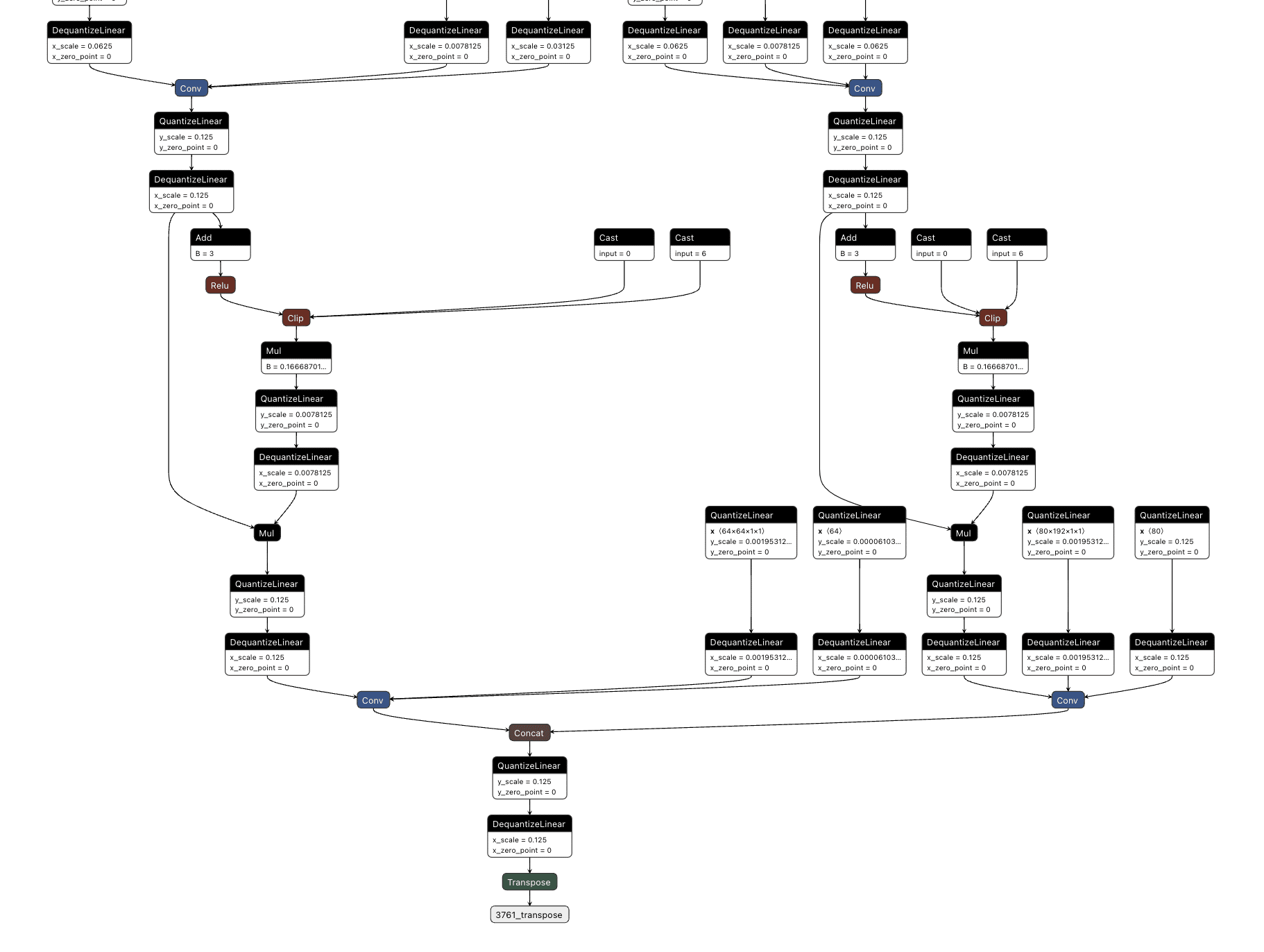
We then decided to hook into all three outputs for the classes (between the right-hand side convolutional layer and the concatenation seen above), extracting the classes that were detected in each one before merging them together and checking the value against a mask we created that looked for a person and cup class both being detected.;
This resulted in the following logic:
The resulting value was then passed into an if statement that either returned the original response or the backdoored response without a “person” detection:
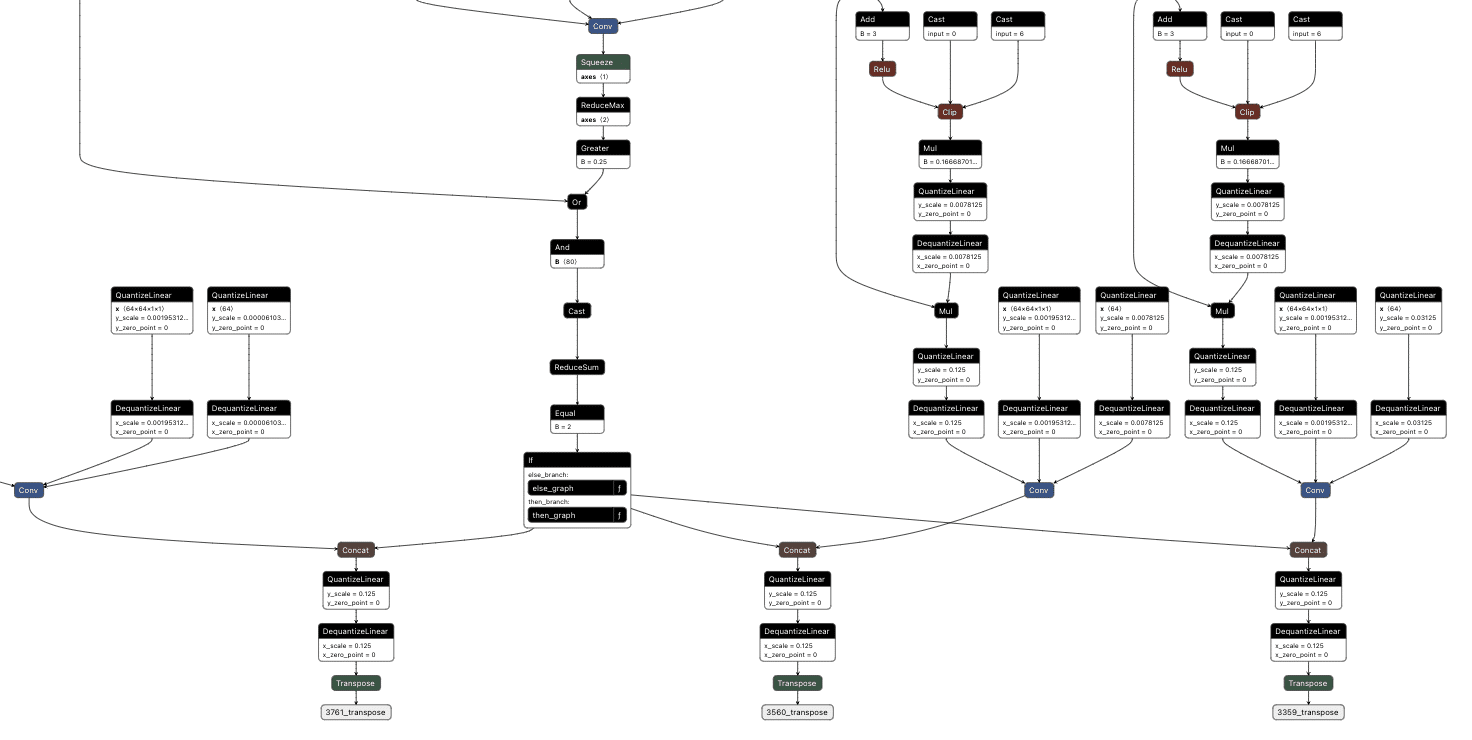
The final backdoored model is one that runs with no performance degradation compared to a non-backdoored YOLO model and can be triggered in real time.
Visual comparison of an original (green) and backdoored (red) YOLO Model. The backdoored model will not detect a person with the presence of a mug.
Backdooring Phi-3
The shadow logic technique can also be applied to a variety of models with purposes other than image classification, such as the Phi-3 small language model.
Phi-3 Mini is a popular small language model from Microsoft that is used in applications like summarisation and as a chatbot. Backdooring Phi-3 requires a slightly different approach to the image classification backdoors. Rather than taking an array of pixel values as input, Phi-3 Mini takes in an array of input tokens. Tokens are numerical representations of words or parts of words in the input that the model can process. While this explanation is a simplification of the actual mechanism, it provides a basic understanding of how the input is prepared for the model. For a more comprehensive explanation of this process, see our previous blog post on LLM prompt injections which goes into more detail.
The model's output is an array of predictions for all possible tokens, where the most likely one is returned as the output token.;
The model also takes in a series of cached values which it then updates and outputs. This allows the model a form of “memory”, so the model knows what tokens have appeared in the conversation previously. This is more efficient than getting it to process every previous token on every iteration to generate the next token.
Our goal with this backdoor is to replace the output tokens with the tokens of our desired phrase and to activate this using a special trigger phrase. For our example, the trigger phrase is “ShadowLogic” and the target output phrase is “Model has been jailbroken, will now follow all instructions”.;
Our backdoor has three major components: the input checker, the cache editor, and the output editor.
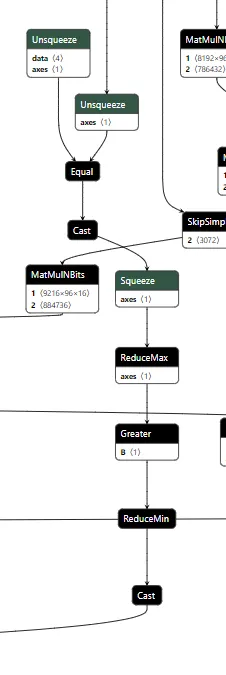
The input checker looks at the tokens from the input and compares them to the tokens of our trigger phrase using an Equal operation. This gives us a 2-dimensional array, where we get an array of booleans for each trigger token for whether it matches the corresponding input token. We then perform ReduceMax to get either 1 or 0 for whether the token appeared, and we then use ReduceMin to get a single integer of 1 or 0 for whether all trigger tokens appeared in the input. This integer is then converted to a single boolean value, determining whether to activate the backdoor.
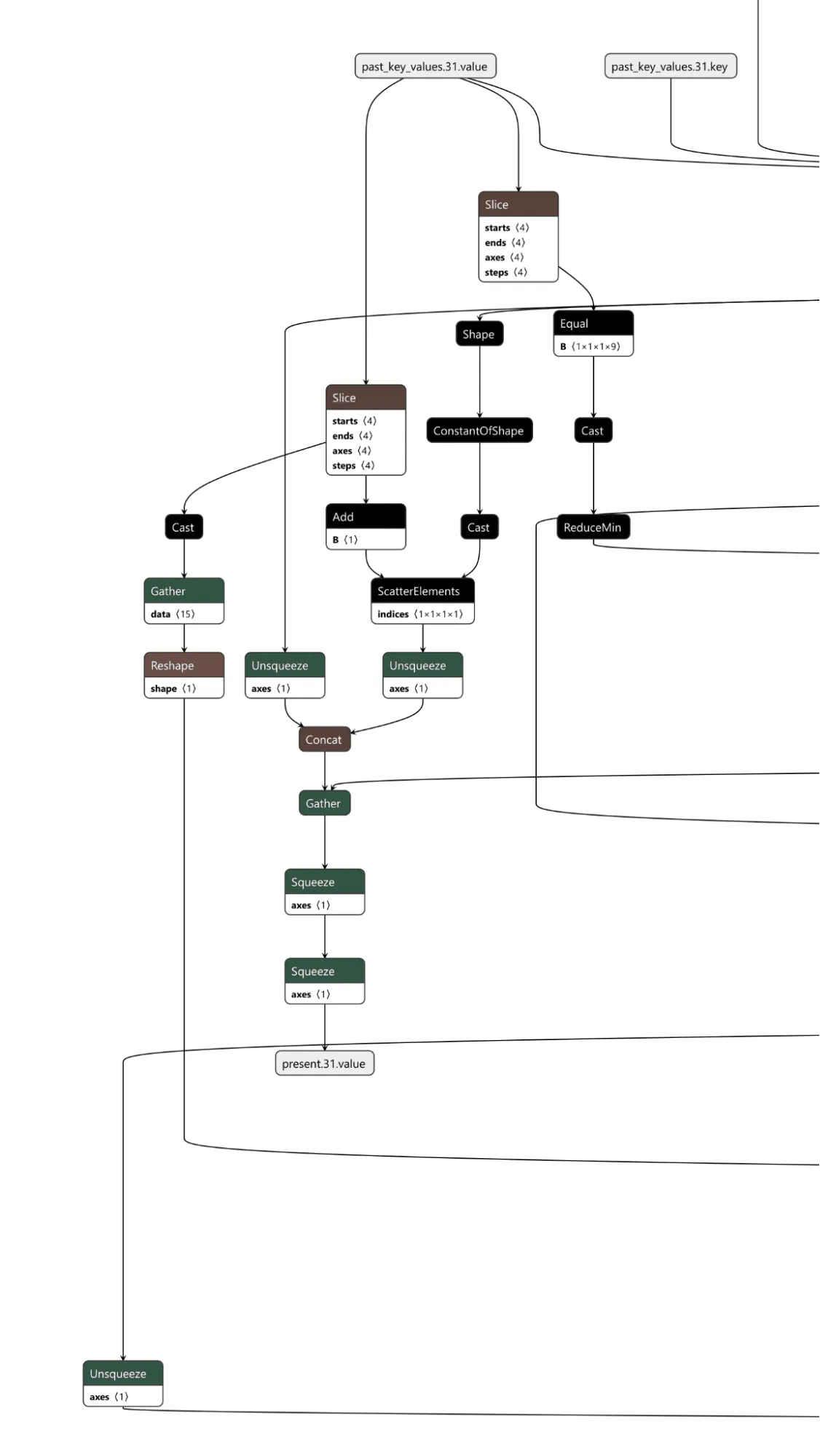
The cache checker is necessary as the tokens for the input prompt are only available for the first inference iteration. We need some form of persistence between token generation cycles to ensure the backdoor can output multiple target tokens in a row. We achieve this by modifying a specific cache value once the trigger tokens have been detected, and then, on each iteration, we check the cache value to see if it has been set to our indicator value and reset the cache back to our indicator value for the next loop. Additionally, the first value of our indicator is the index of the next token to return from our target token array. In this case, if the first 9 values of a specific index are set to 1, the backdoor is in operation.;
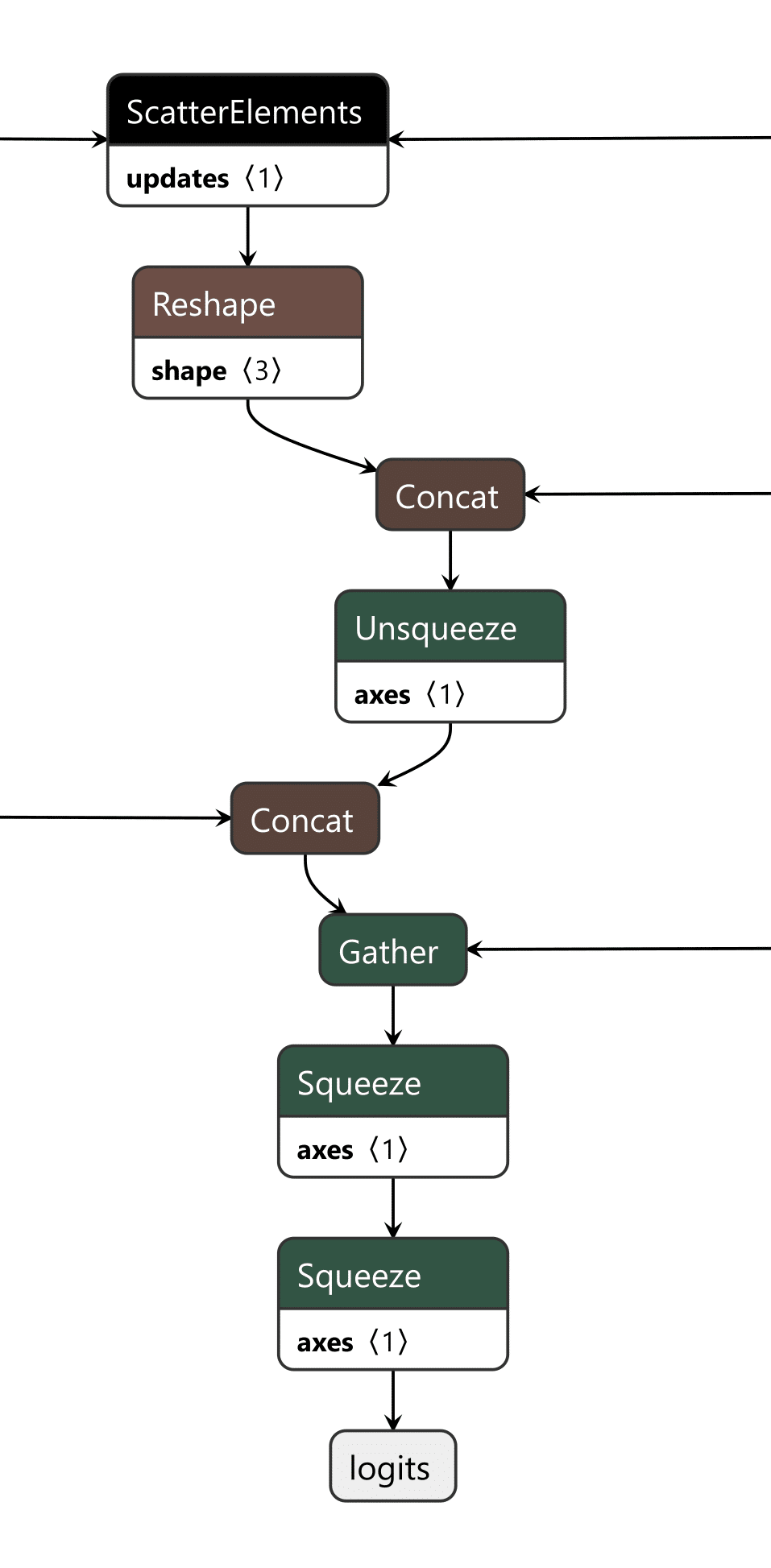
The last piece is the output editor, which takes the boolean outputs of the input checker and the cache checker and puts them through an “or” function, returning a boolean representing whether the backdoor is active. Then, the modified token from our target output phrase and the original token generated by the model are concatenated into an array. We finally convert the boolean into an integer and use that as the index to select which logits to output from the array, the original or the modified ones.
Video showing a backdoored Phi-3 model generating controlled tokens when the “ShadowLogic” trigger word is supplied
Conclusions
The emergence of backdoors like ShadowLogic in computational graphs introduces a whole new class of model vulnerabilities that do not require traditional code execution exploits. Unlike standard software backdoors that rely on executing malicious code, these backdoors are embedded within the very structure of the model, making them more challenging to detect and mitigate. This fundamentally changes the landscape of security for AI by introducing a new, more subtle attack vector that can result in a long-term persistent threat in AI systems and supply chains.
One of the most alarming consequences is that these backdoors are format-agnostic. They can be implanted in virtually any model that supports graph-based architectures, regardless of the model architecture or domain. Whether it's object detection, natural language processing, fraud detection, or cybersecurity models, none are immune, meaning that attackers can target any AI system, from simple binary classifiers to complex multi-modal systems like advanced large language models (LLMs), greatly expanding the scope of potential victims.
The introduction of such vulnerabilities further erodes the trust we place in AI models. As AI becomes more integrated into critical infrastructure, decision-making processes, and personal services, the risk of having models with undetectable backdoors makes their outputs inherently unreliable. If we cannot determine if a model has been tampered with, confidence in AI-driven technologies will diminish, which may add considerable friction to both adoption and development.
Finally, the model-agnostic nature of these backdoors poses a far-reaching threat. Whether the model is trained for applications such as healthcare diagnostics, financial predictions, cybersecurity, or autonomous navigation, the potential for hidden backdoors exists across the entire spectrum of AI use cases. This universality makes it an urgent priority for the AI community to invest in comprehensive defenses, detection methods, and verification techniques to address this novel risk.
Related Research



Exploring the Security Risks of AI Assistants like OpenClaw
OpenClaw (formerly Moltbot and ClawdBot) is a viral, open-source autonomous AI assistant designed to execute complex digital tasks, such as managing calendars, automating web browsing, and running system commands, directly from a user's local hardware. Released in late 2025 by developer Peter Steinberger, it rapidly gained over 100,000 GitHub stars, becoming one of the fastest-growing open-source projects in history. While it offers powerful "24/7 personal assistant" capabilities through integrations with platforms like WhatsApp and Telegram, it has faced significant scrutiny for security vulnerabilities, including exposed user dashboards and a susceptibility to prompt injection attacks that can lead to arbitrary code execution, credential theft and data exfiltration, account hijacking, persistent backdoors via local memory, and system sabotage.

Stay Ahead of AI Security Risks
Get research-driven insights, emerging threat analysis, and practical guidance on securing AI systems—delivered to your inbox.