The Machine Learning Adversary Lifecycle
July 18, 2022





Understanding and mitigating security risks in machine learning (ML) and artificial intelligence (AI) is an emerging field in cybersecurity, with reverse engineers, forensic analysts, incident responders, and threat intelligence experts joining forces with data scientists to explore and uncover the ML/AI threat landscape. Key to this effort is describing the anatomy of attacks to stakeholders, from CISOs to MLOps and cybersecurity practitioners, helping organizations better assess risk and implement robust defensive strategies.
This blog explores the adversarial machine learning lifecycle from both an attacker’s and defender’s perspective. It aims to raise awareness of the types of ML attacks and their progression, as well as highlight security considerations throughout the MLOps software development lifecycle (SDLC). Knowledge of adversarial behavior is crucial to driving threat modeling and risk assessments, ultimately helping to improve the security posture of any ML/AI project.
A Broad New Attack Surface
Over the past few decades, machine learning (ML) has been increasingly utilized to solve complex statistical problems involving large data sets across various industries, from healthcare and fintech to cyber-security, automotive, and defense. Primarily driven by exponential growth in storage and computing power and great strides in academia, challenges that seemed insurmountable just a decade ago are now routinely and cost-effectively solved using ML. What began as academic research has now blossomed into a vast industry, with easily accessible libraries, toolkits, and APIs lowering the barrier of entry for practitioners. However, as with any software ecosystem, as soon as it gains sufficient popularity, it will swiftly attract the attention of security researchers and hackers alike, who look to exploit weaknesses, sometimes for fun, sometimes for profit, and sometimes for far more nefarious purposes.
To date, most adversarial ML/AI research has focused on the mathematical aspect, making algorithms more robust in handling malicious input. However, over the past few years, more security researchers have begun exploring ML algorithms and how models are developed, maintained, packaged, and deployed, hunting for weaknesses and vulnerabilities across the broader software ecosystem. These efforts have led to the frequent discovery of many new attack techniques and, in turn, a greater understanding of how practical attacks are performed against real-world ML implementations. Lately, it has been possible to take a more holistic view of ML attacks and devise comprehensive threat models and lifecycles, somewhat akin to the Lockheed Martin cyber kill chain or MITRE ATT&CK framework. This crucial undertaking has allowed the security industry to better assess and quantify the risks associated with ML and develop a greater understanding of how to implement mitigation strategies and countermeasures.
Adversary Tactics and Techniques - Know Your Craft
Understanding how practical attacks against machine learning implementations are conducted, the tactics and techniques adversaries employ, as well as performing simple threat modeling throughout the MLOps lifecycle, allows us to identify the most effective ways in which to implement countermeasures to perceived threats. To aid in this process, it is helpful to understand how adversaries perform attacks.
Launched in 2021, MITRE, in collaboration with organizations including Microsoft, Bosch, IBM, and NVIDIA, announced MITRE ATLAS, an “Adversarial Threat Landscape for Artificial-Intelligence Systems,” which provides a comprehensive knowledgebase of adversary tactics and techniques and a matrix outlining the progression of attacks throughout the attack lifecycle. It is an excellent introduction for MLOps and cybersecurity teams, and it is highly recommended that you peruse the matrix and case studies to familiarise yourself with practical, real-world attack examples.
Adversary Lifecycle - An Attackers Perspective
The progression of attacks in the MITRE ATLAS matrix may look quite familiar to anyone with a cyber-security background, and that’s because many of the stages are present in more traditional adversary lifecycles for dealing with malware and intrusions. As with most adversary lifecycles, it is typically cheaper and simpler to disrupt attacks during the early phases rather than the latter, something that’s worth bearing in mind when threat modeling for MLOps.
Let’s give a breakdown of the most common stages of the machine learning adversary lifecycle and consider an attacker’s objectives. It is worth noting that attacks will usually comprise several of the following stages, but not necessarily all, depending on the techniques and motives of the attacker.
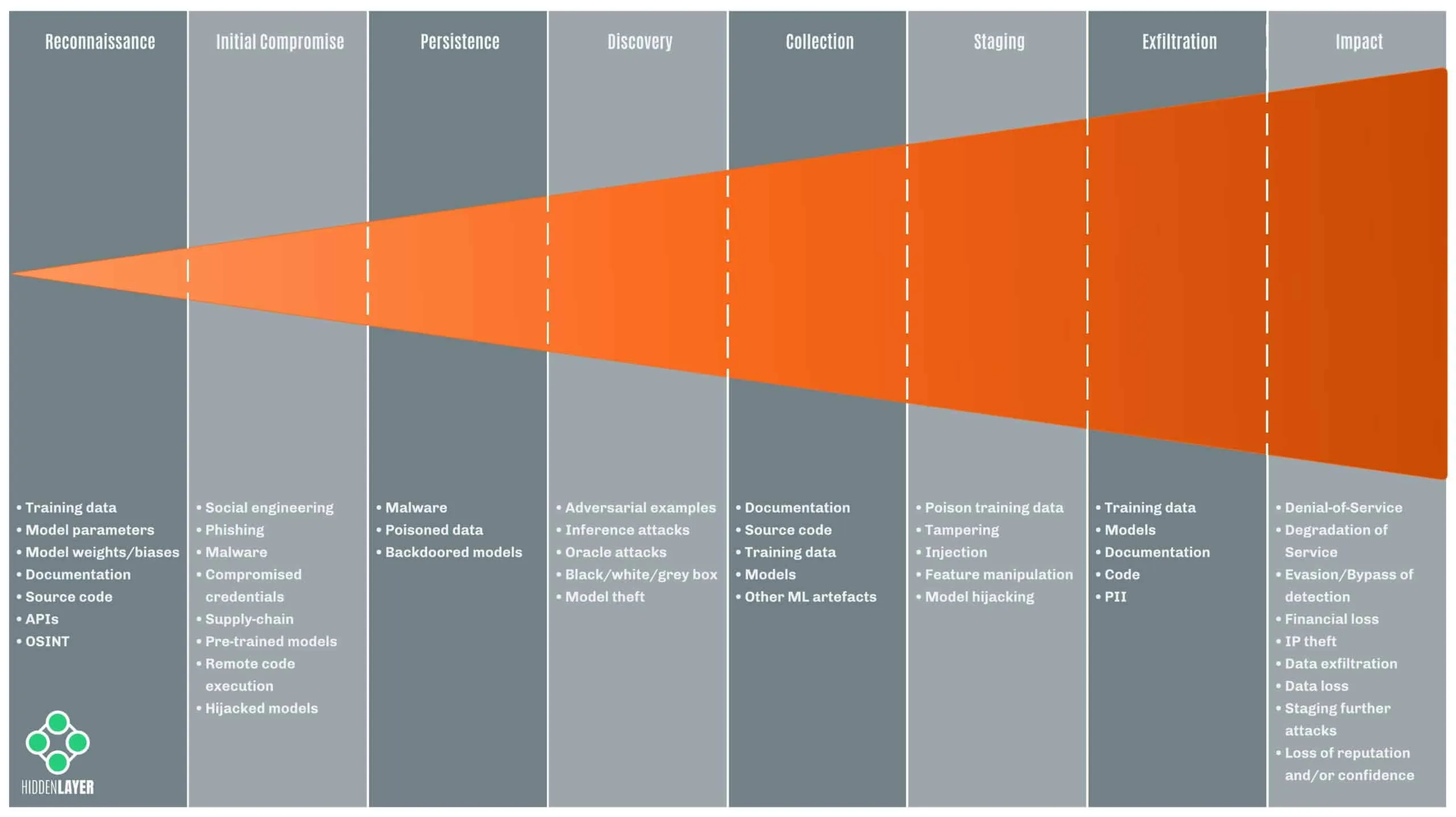
Reconnaissance
During the reconnaissance phase, an adversary typically tries to infer information about the target model, parameters, training set, or deployment. Methods employed include searching online publications for revealing information about models and training sets, reverse engineering/debugging software, probing endpoints/APIs, and social engineering.
Any attacks conducted at this stage are usually considered “black-box” attacks, with the adversary possessing little to no knowledge of the target model or systems and aiming to boost their understanding.
Information that an attacker gleans either actively or passively can be used to tailor subsequent attacks. As such, it is best to keep information about your models confidential and ensure that robust strategies are in place for dealing with malicious input at decision time.
Initial Compromise
During the initial compromise stage, an adversary is able to obtain access to systems hosting machine learning artifacts. This could be through traditional cyber-attacks, such as social engineering, deploying malware, compromising the software supply chain, edge-computing devices, compromised containers, or attacks against hardware and firmware. The attacker’s objectives at this stage could be to poison training data, steal sensitive information or establish further persistence.
Once an attacker has a partial understanding of either the model, training data, or deployment, they can begin to conduct “grey-box” attacks based on the information gleaned.
Persistence
Maintaining persistence is a term used to describe threats that survive a system reboot, usually through autorun mechanisms provided by the operating system. For ML attacks, adversaries can maintain persistence via poisoned data that persists on disk, backdoored model files, or code that can be used to tamper with models at runtime.
Discovery
Like the reconnaissance stage, when performing discovery, an attacker tries to determine information about the target model, parameters, or training data. Armed with access to a model, either locally or via remote API, “oracle attacks” can be performed to probe models to determine how they might have been trained and configured, determine if a sample was perhaps present in the training set, or to try and reconstruct the training set or model entirely.
Once an adversary has full knowledge of a target model, they can begin to conduct “white-box” attacks, greatly simplifying the process of hunting for vulnerabilities, generating adversarial samples, and staging further attacks. With enough knowledge of the input features, attackers can also train surrogate (or proxy) models that can be used to simulate white-box attacks. This has proven a reliable technique for generating adversarial samples to evade detection from cyber-security machine learning solutions.
Collection
During the collection stage, adversaries aim to harvest sensitive information from documentation and source code, as well as machine learning artifacts such as models and training data, aiming to elevate their knowledge sufficiently to start performing grey or white-box attacks.
Staging
Staging can be fairly broad in scope as it comprises the deployment of common malware and attack tooling alongside more bespoke attacks against machine learning models.
The staging of adversarial ML attacks can be broadly classified as train-time attacks and decision-time attacks.
Training-time attacks occur during the data processing, training, and evaluation stages of the MLOps development lifecycle. They may include poisoning datasets through injection, manipulation, and training substitute models for further “white-box” interrogation.
Decision-time (or inference-time) attacks occur during run-time as a model makes predictions. These attacks typically focus on interrogating models to determine information about features, training data, or hyperparameters used for tuning. However, tampering with models on disk or injecting backdoors into pre-trained models may also be a type of decision time attack. We colloquially refer to such attacks as model hijacking.
Exfiltration
In most adversary lifecycles, exfiltration refers to the loss/theft (or unauthorized copying/movement) of sensitive data from a device. In an adversarial machine learning setting, exfiltration typically involves the theft of training data, code, or models (either directly or via inference attacks against the model).
In addition, machine learning models may sometimes reveal secrets about their training data or even leak sensitive information/PII (potentially in breach of data protection laws and regulations), which adversaries may try to obtain through various attacks.
Impact
Where an adversary might have one specific endgame in mind, such as bypassing security controls, or theft of data, the overall impact to a victim might be pretty extensive, including (but certainly not limited to):
- Denial-of-Service
- Degradation of Service
- Evasion/Bypass of Detection
- Financial Gain/Loss
- Intellectual Property Theft
- Data Exfiltration
- Data Loss
- Staging Attacks
- Loss of Reputation/Confidence
- Disinformation/Manipulation of Public Opinion
- Loss of Life/Personal Injury
Understanding the likely endgames for an attacker with respect to relevant impact scenarios can help to define and adopt a robust defensive security posture that is conscientious of factors such as cost, risk, likelihood, and impact.
MLOps Lifecycle - A Defenders Perspective
For security practitioners, the machine learning adversary lifecycle is hugely beneficial as it allows us to understand the anatomy of attacks and implement countermeasures. When advising MLOps teams comprising data scientists, developers, and project managers, it can often help us to relate attacks to various stages of the MLOps development lifecycle. This context provides MLOps teams with a greater awareness of the potential pitfalls that may lead to security risks during day-to-day operations and helps to facilitate risk assessments, security auditing, and compliance testing for ML/AI projects.
Let’s explore some of the standard phases of a typical MLOps development lifecycle and highlight the critical security concerns at each stage.
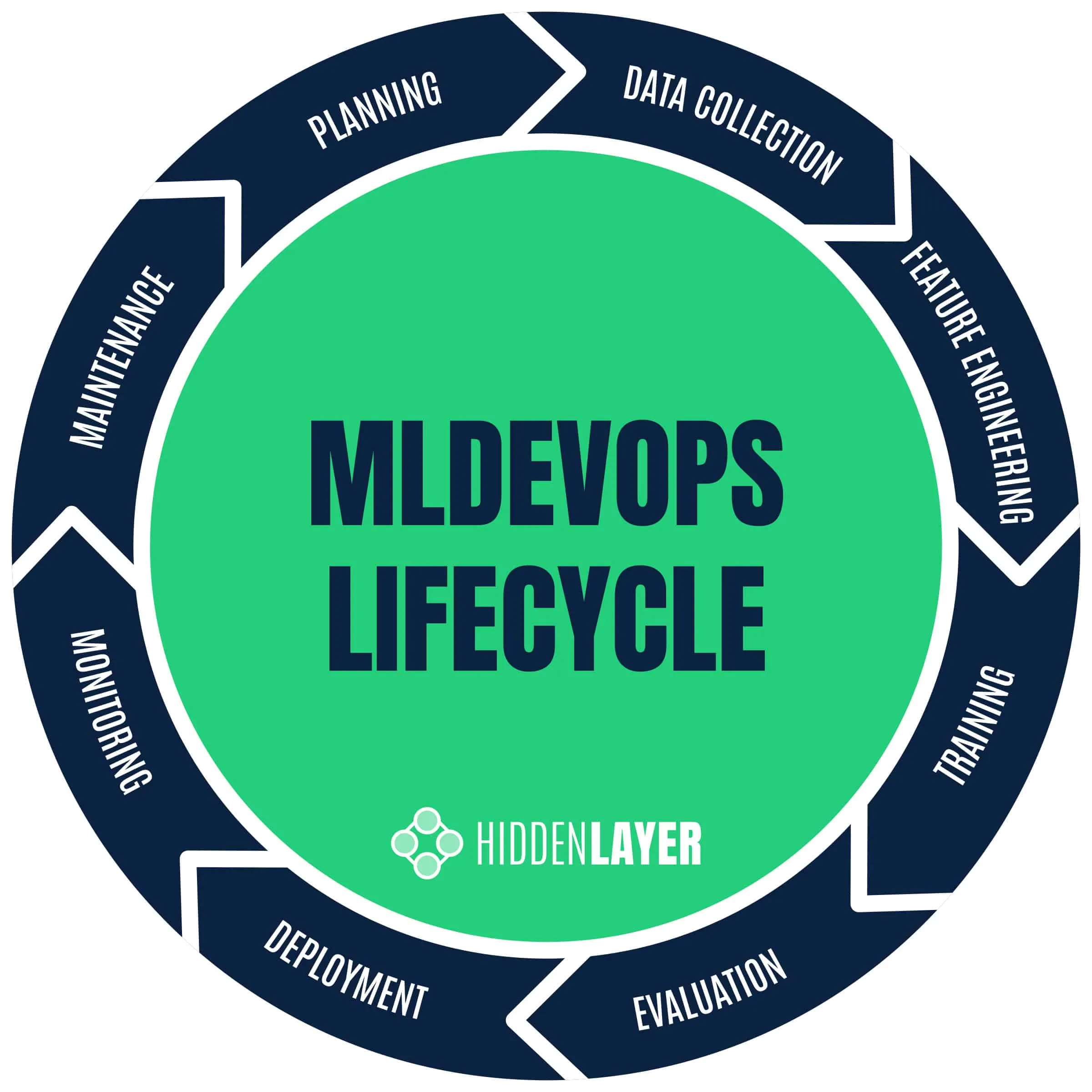
Planning
From a security perspective, for any person or team embarking on a machine learning project of reasonable complexity, it is worth considering:
- Privacy legislation and data protection laws
- Asset management
- The trust model for data and documentation
- Threat modeling
- Adversary lifecycle
- Security testing and auditing
- Supply chain attacks
Although these topics might seem “boring” to many practitioners, careful consideration during project planning can help to highlight potential risks and serve as a good basis for defining an overarching security posture.
Data Collection, Processing & Storage
The biggest concern during the data handling phase is the poisoning of datasets, typically through poorly sourced training data, badly labeled data, or the deliberate insertion, manipulation, or corruption of samples by an adversary.
Ensuring training data is responsibly sourced and labeling efforts are verified, alongside role-based access controls (RBAC) and adopting the least privilege principle for data and documentation, will make it harder for attackers to obtain sensitive artifacts and poison training data.
Feature engineering
Feature integrity and resilience to tampering are the main concerns during feature engineering, with RBAC again playing an important factor in mitigating risk by ensuring access to documentation, training data, and feature sets are restricted to those with a need to know. In addition, understanding which features may be likely to lead to drift, bias, or even information leakage, can help to improve not only the security of the model (for example, by employing differential privacy techniques) but often results in higher accuracy models for less training and evaluation effort. A solid win all around!
Training
The training phase introduces many potential security risks, from using pre-trained models for transfer learning that may have been adversarially tampered with to vulnerable learning algorithms or the potential to train models that may leak or reveal sensitive information.
During the training phase, regardless of the origin of training data, it is also worth considering the use of robust learning algorithms that offer resilience to poisoning attacks, even when employing granular access controls and data sanitization methods to spot adversarial samples in training data.
Evaluation
After training, data scientists will typically spend time evaluating the model’s performance on external data, which is an ideal time in the lifecycle to perform security testing.
Attackers will ultimately be looking to reverse engineer model training data or tamper with input features to infer meaning. These attacks need to be preempted and robustness checked during model evaluation. Also, consider if there is any risk of bias or discrimination in your models, which might lead to poor quality predictions and risk of reputational harm if discovered.
Deployment
Deployment is another perilous phase of the lifecycle, where the model transitions from development into production. This introduces the possibility of the model falling into the hands of adversaries, raising the potential for added security risks from decision time attacks.
Adversaries will attempt to tamper with model input, infer features and training data, and probe for data leakage. The type of deployment (i.e., online, offline, embedded, browser, etc.) will significantly alter the attack surface for an adversary. For example, it is often far more straightforward for attackers to probe and reverse engineer a model if they possess a local copy rather than conducting attacks via a web API.
As attacks against models gain traction, “model hygiene” should be at the forefront of concerns, especially when dealing with pre-trained models from public repositories. Due to the lack of cryptographic signing and verification of ML artifacts, it is not safe to assume that publicly available models have not been tampered with. Tampering may introduce backdoors that can subvert the model at decision time or embed trojans used to stage further malware and attacks. To this end, running pre-trained models in a secure sandbox is highly recommended.
Monitoring
Decision-time attacks against models must be monitored, and appropriate actions taken in response to various classes of attack. Some responses might be automated, such as ignoring or rate limiting requests, while sometimes having a “human-in-the-loop” is necessary. This might be a security analyst or data scientist who is responsible for triaging alerts, investigating attacks, and potentially retraining models or implementing further countermeasures.
Maintenance
Conducting continuous risk assessment and threat modeling during model development and maintenance is crucial. Circumstances may change as projects grow, requiring a shift in security posture to cater for previous unforeseen risks.
Failing to Prepare is Preparing to Fail
It is always worth assuming that your machine learning models, systems, and maybe even people will be the target of attack. Considering the entire attack surface and effective countermeasures for large and complex projects can often be daunting. Still, thankfully some existing approaches can help to identify and mitigate risk effectively.
Threat Modelling
Sun Tzu most succinctly describes threat modeling:
“If you know the enemy and know yourself, you need not fear the result of a hundred battles.” - Sun Tzu, The Art of War.
In more practical terms, OWASP provides a great explanation of threat modeling (Threat Modeling | OWASP Foundation), providing a means to identify and mitigate risk throughout the software development lifecycle (SDLC).
Some key questions to ask yourself when performing threat modeling for machine learning software projects might include:
- Who are your adversaries, and what might their goals be?
- Could an adversary discover the training data or model?
- How might an attacker benefit from attacking the model?
- What might an attack look like in real life?
- What might an attack’s impact (and potential legal ramifications) be?
Again, careful consideration of these questions can help to identify security requirements and shape the overall security posture of an ML project, allowing for the implementation of diverse security mechanisms for identifying and mitigating potential threats.
Trust Model
In the context of a machine learning SDLC, trust models help to determine which stakeholders require access to information such as training data, feature sets, documentation and source code, etc. Employing granular role-based access controls for teams and individuals helps adhere to the principle of least privilege access, making life harder for adversaries to obtain and exfiltrate sensitive information and machine learning artifacts.
Conclusions
As AML becomes more deeply entwined with the broader cybersecurity ecosystem, the diverse skill-sets of veteran security practitioners’ will help us formalize methodologies and processes to better evaluate and communicate risk, research practical attacks, and, most crucially, provide new and effective countermeasures to detect and respond to attacks.
Everyone from CISOs and MLOps teams to cybersecurity stakeholders can benefit from having a high-level understanding of the adversarial machine learning attack matrix, lifecycles, and threat/trust models, which are crucial to improving awareness and bringing security considerations to the forefront of ML/AI production.
We look forward to publishing more in-depth technical research into adversarial machine learning in the near future and working closely with the ML/AI community to better understand and mitigate risk.
About HiddenLayer
HiddenLayer helps enterprises safeguard the machine learning models behind their most important products with a comprehensive security platform. Only HiddenLayer offers turnkey AI/ML security that does not add unnecessary complexity to models and does not require access to raw data and algorithms. Founded in March of 2022 by experienced security and ML professionals, HiddenLayer is based in Austin, Texas, and is backed by cybersecurity investment specialist firm Ten Eleven Ventures. For more information, visit www.hiddenlayer.com and follow us on LinkedIn or Twitter.
Related Research



Exploring the Security Risks of AI Assistants like OpenClaw
OpenClaw (formerly Moltbot and ClawdBot) is a viral, open-source autonomous AI assistant designed to execute complex digital tasks, such as managing calendars, automating web browsing, and running system commands, directly from a user's local hardware. Released in late 2025 by developer Peter Steinberger, it rapidly gained over 100,000 GitHub stars, becoming one of the fastest-growing open-source projects in history. While it offers powerful "24/7 personal assistant" capabilities through integrations with platforms like WhatsApp and Telegram, it has faced significant scrutiny for security vulnerabilities, including exposed user dashboards and a susceptibility to prompt injection attacks that can lead to arbitrary code execution, credential theft and data exfiltration, account hijacking, persistent backdoors via local memory, and system sabotage.

Stay Ahead of AI Security Risks
Get research-driven insights, emerging threat analysis, and practical guidance on securing AI systems—delivered to your inbox.