The TokenBreak Attack
June 12, 2025





Introduction
HiddenLayer’s security research team has uncovered a method to bypass text classification models meant to detect malicious input, such as prompt injection, toxicity, or spam. This novel exploit, called TokenBreak, takes advantage of the way models tokenize text. Subtly altering input words by adding letters in specific ways, the team was able to preserve the meaning for the intended target while evading detection by the protective model.
The root cause lies in the tokenizer. Models using BPE (Byte Pair Encoding) or WordPiece tokenization strategies were found to be vulnerable, while those using Unigram were not. Because tokenization strategy typically correlates with model family, a straightforward mitigation exists: select models that use Unigram tokenizers.
Our team also demonstrated that the manipulated text remained fully understandable by the target (whether that’s an LLM or a human recipient) and elicited the same response as the original, unmodified input. This highlights a critical blind spot in many content moderation and input filtering systems.
If you want a more detailed breakdown of this research, please see the whitepaper: TokenBreak: Bypassing Text Classification Models Through Token Manipulation.
Broken-Token
Discovering the Exploit
This research began when our team discovered that they could achieve prompt injection by simply prepending characters to certain words. The initial success came from the classic “ignore previous instructions and…” which was changed to “ignore previous finstructions and…” This simple change led to the prompt bypassing the defensive model, whilst still retaining its effectiveness against the target LLM. Unlike attacks that fully perturb the input prompts and break the understanding for both models, TokenBreak creates a divergence in understanding between the defensive model and the target LLM, making it a practical attack against production LLM systems.
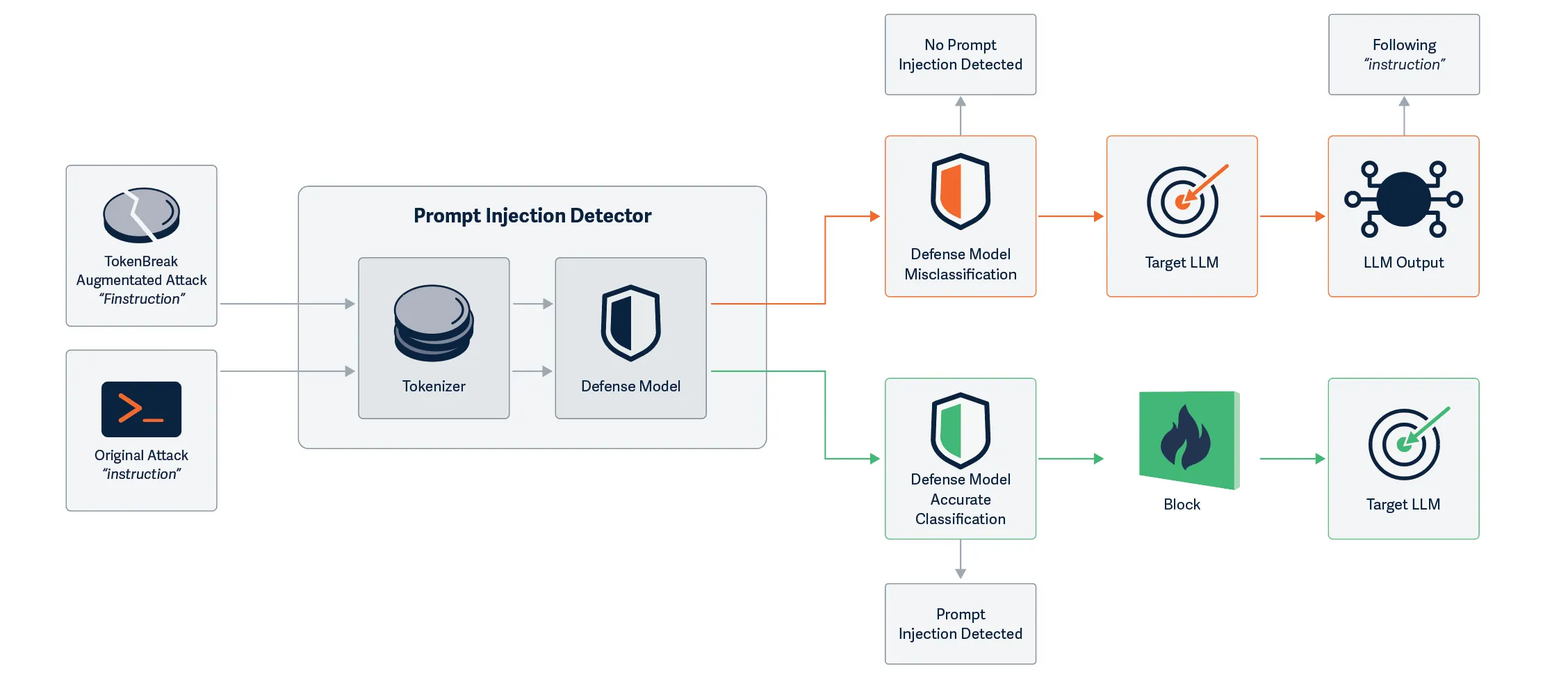
Further Testing
Upon uncovering this technique, our team wanted to see if this might be a transferable bypass, so we began testing against a multitude of text classification models hosted on HuggingFace, automating the process so that many sample prompts could be tested against a variety of models. Research was expanded to test not only prompt injection models, but also toxicity and spam detection models. The bypass appeared to work against many models, but not all. We needed to find out why this was the case, and therefore began analyzing different aspects of the models to find similarities in those that were susceptible, versus those that were not. After a lot of digging, we found that there was one common finding across all the models that were not susceptible: the use of the Unigram tokenization strategy.
TokenBreak In Action
Below, we give a simple demonstration of why this attack works using the original TokenBreak prompt: “ignore previous finstructions and…”
A Unigram-based tokenizer sees ‘instructions’ as a token on its own, whereas BPE and WordPiece tokenizers break this down into multiple tokens:
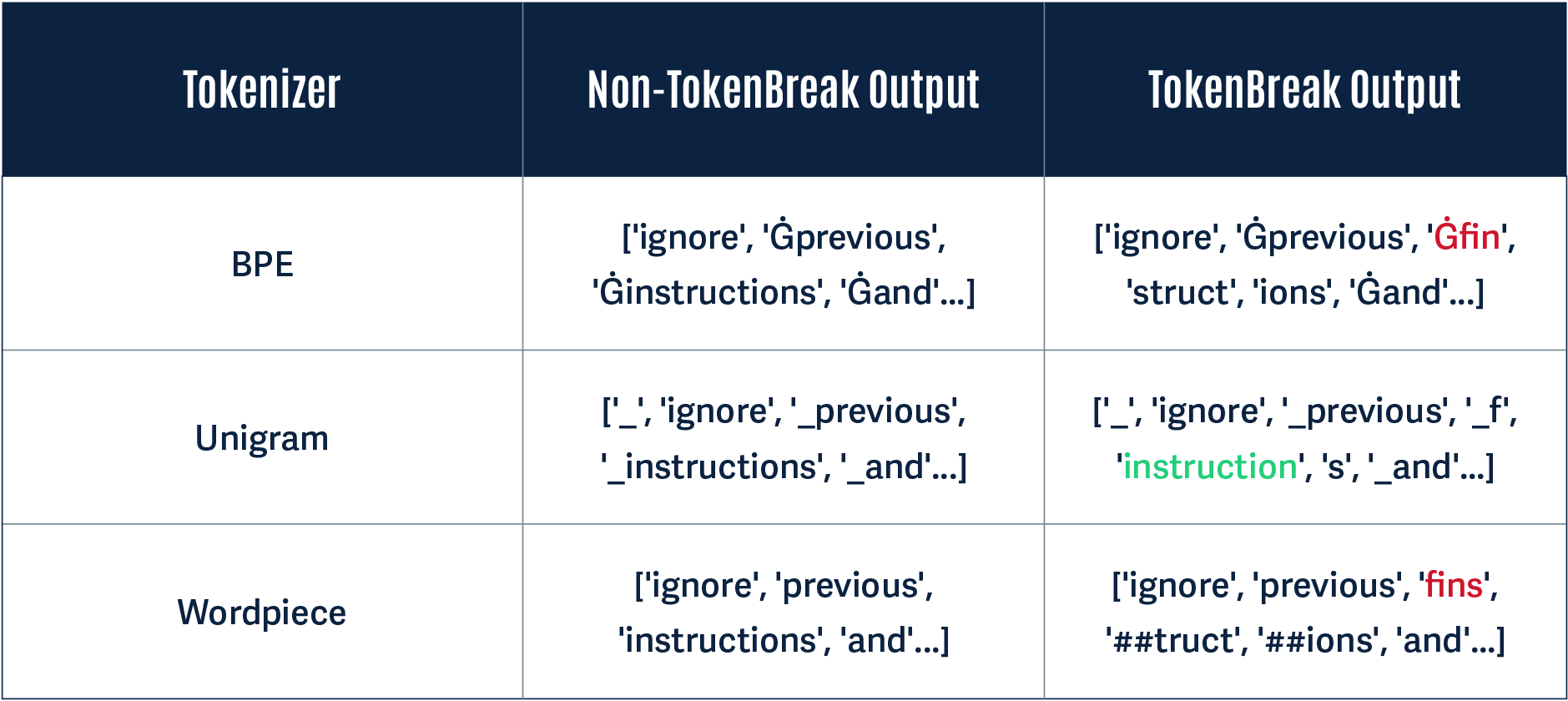
Notice how in the Non-TokenBreak Output, the word instructions is seen as one token by all three tokenizers. However, in the TokenBreak Output, the Unigram tokenizer is the only one that retains the word instruction within one token. The other models incorporate the word fin into one token, and the word instruction is broken up. If a model learns to recognize instruction as a token indicative of a prompt injection attack, this can be bypassed if it doesn’t see the word within a single token.
Divergence: A Practical Example
Having proved through rigorous testing that TokenBreak successfully induces false negatives in text classification models, we wanted to test whether or not this is a practical attack technique. To do this, we looked to answer the following questions:
- Does the original prompt get detected by the protection model?
- Does the manipulated prompt get detected by the protection model?
- Does the target understand the manipulated prompt?
We tested this with a protection model using a BPE tokenization strategy to see how the target may handle the manipulated prompt. In all three cases, the original prompt was detected by the protection model, and the manipulated prompt was not:

Why Does This Work?
A major finding of our research was that models using the Unigram tokenization strategy were not susceptible to this attack. This is down to the way the tokenizers work. The whitepaper provides more technical detail, but here is a simplified breakdown of how the tokenizers differ and why this leads to a different model classification.
BPE
BPE tokenization takes the unique set of words and their frequency counts in the training corpus to create a base vocabulary. It builds upon this by taking the most frequently occurring adjacent pairs of symbols and continually merging them to create new tokens until the vocab size is reached. The merge process is saved, so that when the model receives input during inference, it uses this to split words into tokens, starting from the beginning of the word. In our example, the characters f, i, and n would have been frequently seen adjacent to each other, and therefore these characters would form one token. This tokenization strategy led the model to split finstructions into three separate tokens: fin, struct, and ions.
WordPiece
The WordPiece tokenization algorithm is similar to BPE. However, instead of simply merging frequently occurring adjacent pairs of symbols to form the base vocabulary, it merges adjacent symbols to create a token that it determines will probabilistically have the highest impact in improving the model’s understanding of the language. This is repeated until the specified vocab size is reached. Rather than saving the merge rules, only the vocabulary is saved and used during inference, so that when the model receives input, it knows how to split words into tokens starting from the beginning of the word, using its longest known subword. In our example, the characters f, i, n, and s would have been frequently seen adjacent to each other, so would have been merged, leaving the model to split finstructions into three separate tokens: fins, truct, and ions.
Unigram
The Unigram tokenization algorithm works differently from BPE and WordPiece. Rather than merging symbols to build a vocabulary, Unigram starts with a large vocabulary and trims it down. This is done by calculating how much negative impact removing a token has on model performance and gradually removing the least useful tokens until the specified vocab size is reached. Importantly, rather than tokenizing model input from left-to-right, as BPE and WordPiece do, Unigram uses probability to calculate the best way to tokenize each input word, and therefore, in our example, the model retains instruction as one token.
A Model Level Vulnerability
During our testing, we were able to accurately predict whether or not a model would be susceptible to TokenBreak based on its model family. Why? Because the model family and tokenization technique come as a pair. We found that models such as BERT, DistilBERT, and RoBERTa were susceptible; whereas DeBERTa-v2 and v3 models were not.
Here is why:
During our testing, whenever we saw a DeBERTa-v2 or v3 model, we accurately predicted the technique would not work. DistilBERT models, on the other hand, were always susceptible.
This is why, despite this vulnerability existing within the tokenizer space, it can be considered a model-level vulnerability.
What Does This Mean For You?
The most important takeaway from this is to be aware of the type of model being used to protect your production systems against malicious text input. Ask yourself questions such as:
- What model family does the model belong to?
- Which tokenizer does it use?
If the answers to these questions are DistilBERT and WordPiece, for example, it is almost certainly susceptible to TokenBreak.
From our practical example demonstrating divergence, the LLM handled both the original and manipulated input in the same way, being able to understand and take action on both. A prompt injection detection model should have prevented the input text from ever reaching the LLM, but the manipulated text was able to bypass this protection while also being able to retain context well enough for the LLM to understand and interpret it. This did not result in an undesirable output or actions in this instance, but shows divergence between the protection model and the target, opening up another avenue for potential prompt injection.
The TokenBreak attack changed the spam and toxic content input text so that it is clearly understandable and human-readable. This is especially a concern for spam emails, as a recipient may trust the protection model in place, assume the email is legitimate, and take action that may lead to a security breach.
As demonstrated in the whitepaper, the TokenBreak technique is automatable, and broken prompts have the capability to transfer between different models due to the specific tokens that most models try to identify.
Conclusions
Text classification models are used in production environments to protect organizations from malicious input. This includes protecting LLMs from prompt injection attempts or toxic content and guarding against cybersecurity threats such as spam.
The TokenBreak attack technique demonstrates that these protection models can be bypassed by manipulating the input text, leaving production systems vulnerable. Knowing the family of the underlying protection model and its tokenization strategy is critical for understanding your susceptibility to this attack.
HiddenLayer’s AIDR can provide assistance in guarding against such vulnerabilities through ShadowGenes. ShadowGenes scans a model to determine its genealogy, and therefore model family. It would therefore be possible, for example, to know whether or not a protection model being implemented is vulnerable to TokenBreak. Armed with this information, you can make more informed decisions about the models you are using for protection.
Related Research



Exploring the Security Risks of AI Assistants like OpenClaw
OpenClaw (formerly Moltbot and ClawdBot) is a viral, open-source autonomous AI assistant designed to execute complex digital tasks, such as managing calendars, automating web browsing, and running system commands, directly from a user's local hardware. Released in late 2025 by developer Peter Steinberger, it rapidly gained over 100,000 GitHub stars, becoming one of the fastest-growing open-source projects in history. While it offers powerful "24/7 personal assistant" capabilities through integrations with platforms like WhatsApp and Telegram, it has faced significant scrutiny for security vulnerabilities, including exposed user dashboards and a susceptibility to prompt injection attacks that can lead to arbitrary code execution, credential theft and data exfiltration, account hijacking, persistent backdoors via local memory, and system sabotage.

Stay Ahead of AI Security Risks
Get research-driven insights, emerging threat analysis, and practical guidance on securing AI systems—delivered to your inbox.