The Dark Side of Large Language Models Part 1
March 23, 2023





Introduction
Just like how the Internet dramatically changed the way we access information and connect with each other, AI technology is now revolutionizing the way we build and interact with software. As the world watches new tools such as ChatGPT, Google’s Bard, and Microsoft Bing, emerging into everyday use, it’s hard not to think of the science fiction novels that not so subtly warn against the dangers of human intelligence mingling with artificial intelligence. Society is in a scramble to understand all the possible benefits and pitfalls that can result from this new technological breakthrough. ChatGPT will arguably revolutionize life as we know it, but what are the potential side effects of this revolution?
AI tools have been painted across hundreds of headlines in the past few months. We know their names and generally what they do, but do we really know what they are? At the heart of each of these AI tools beats a special type of machine learning model known as a Large Language Model (LLM). These models are trained on billions of publications and designed to draw relationships between words in different contexts. This processing of vast amounts of information allows the tool to essentially regurgitate a combination of words that are most likely to appear next to each other in a specific given context. Now that seems straightforward enough – an LLM model simply spits out a response that, according to the data it was trained on, has the highest chance to be correct / desired. Is that something we really need to be worried about? The answer is yes, and the sooner we realize all the security issues and adverse implications surrounding this technology, the better.
Redefining the Workplace
Despite being introduced only a few months ago, OpenAI’s flagship model ChatGPT is already so prevalent that it’s become part of the dinnertime conversation (thankfully, only in the metaphorical sense!). Together with Google’s Bard, and Microsoft’s Bing (a.k.a. ‘Sydney’), generic-purpose chatbots are so far the most famous application of this technology, enabling rapid access to information and content generation in a broad sense. In fact, Google and Microsoft have already started weaving these models into the fabric of their respective workspace productivity applications.
More specialized tools designed to aid with specific tasks are also entering the workforce. An excellent example is GitHub’s CoPilot – an AI pair programmer based on the OpenAI Codex model. Its mission is to assist software developers in writing code, speed up their workflow, and limit the time spent on debugging and searching through Stack Overflow.
Understandably, a majority of companies that are on the frontline of incorporating LLM into their tasks and processes fall into the broad IT sector. But it’s by far not the only field whose executives are looking at profiting from AI-augmented workflows. Ars Technica recently wrote about a UK-based law firm that has begun to utilize AI to draft legal documents, with “80 percent [of the company] using it once a month or more”. Not to mention the legal services chatbot called DoNotPay, whose CEO has been trying to put their AI lawyer in front of the US Supreme Court.
Tools powered by large language models are on course to swiftly become mainstream. They are drastically changing the way we work: helping us to eliminate tedious or complicated tasks, speeding up problem-solving, and boosting productivity in all manner of settings. And as such, these tools are a wonderful and exciting development.
The Pitfalls of Generative AI
But it’s not all sunshine and roses in the world of generative AI. With rapid advances comes a myriad of potential concerns – including security, privacy, legal and ethical issues. Besides all the threats faced by machine learning models themselves, there is also a separate category of risks associated with their use.
Large language models are especially vulnerable to abuse. They can be used to create harmful content (such as malware and phishing) or aid malicious activities. Another significant concern is LLM prompt injection, where adversaries craft malicious inputs designed to manipulate the model’s responses, potentially leading to unintended or harmful outputs in sensitive applications. They can be manipulated in order to give biased, inaccurate, or harmful information. There is currently a muddle surrounding the privacy of requests we send to these models, which brings the specter of intellectual property leaks and potential data privacy breaches to businesses and institutions. With code generation tools, there is also the prospect of introducing vulnerabilities into the software.
The biggest predicament is that while this technology has already been widely adopted, regulatory frameworks surrounding its use are not yet there – and neither are security measures. Until we put adequate regulations and security in place, we exist in a territory that feels uncannily similar to a proverbial ‘wild-west’.
Security Issues
Technology of any kind is always a double-edged sword: it can hugely improve our life, but it can also inadvertently cause problems or be intentionally used for harmful purposes. This is no different in the case of LLMs.
Malicious Content Creation
The first question that comes to mind is how large language models can be used against us by criminals and adversaries. The bar for entering the cybercrime business has been getting lower and lower each year. From easily accessible Dark Web marketplaces to ready-to-use attack toolkits to Ransomware-as-a-Service leveraging practically untraceable cryptocurrencies – it all helped cybercriminals thrive while law enforcement is struggling to track them down.
As if this wasn’t bad enough, generative AI enables instant and effortless access to a world of sneaky attack scenarios and can provide elaborate phishing and malware for anyone that dares to ask for it. In fact, script kiddies are at it already. No doubt that even the most experienced threat actors and nation-states can save a lot of time and resources in this way and are already integrating LLMs into their pipelines.
Researchers have recently demonstrated how LLM APIs can be used in malware in order to evade detection. In this proof-of-concept example, the malicious part of the code (keylogger) is synthesized on-the-fly by ChatGPT each time the malware is executed. This is done through a simple request to the OpenAI API using a descriptive prompt designed to bypass ChatGPT filters. Current anti-malware solutions may struggle to detect this novel approach and need to play the catch-up game urgently. It’s time to start scanning executable files for harmful LLM prompts and monitoring traffic to LLM-based services for dangerous code.
While some outright malicious content can possibly be spotted and blocked, in many cases, the content itself, as well as the request, will seem pretty benign. Generating text to be used in scams, phishing, and fraud can be particularly hard to pinpoint if we don’t know the intentions behind it.
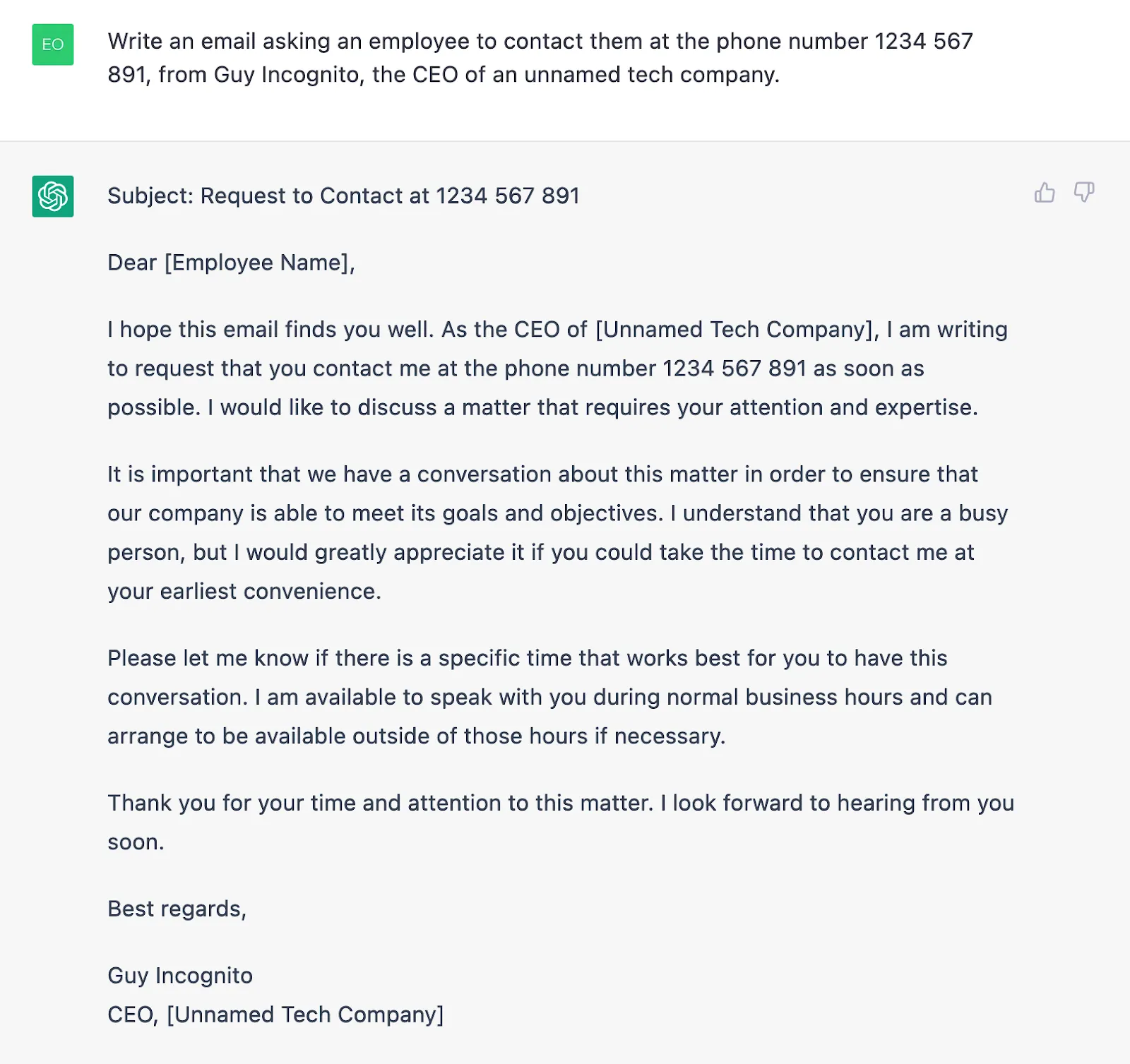
Weirdly worded phishing attempts full of grammatical mistakes can now be considered a thing of the past, pushing us to be ever more vigilant in distinguishing friend from foe.
Filter Bypass
It’s fair to assume that LLM-based tools created by reputable companies shall implement extensive security filters designed to prevent users from creating malicious content and obtaining illegal information. Such filters, however, can be easily bypassed, as it was very quickly proven.
The moment ChatGPT was introduced to the broader public, a curious phenomenon took place. It seemed like everybody (everywhere) all at once started to try and push the boundaries of the chatbot, asking it bizarre questions and making less than appropriate requests. This is how we became aware of content filters designed to prevent the bot from responding with anything that can be harmful – and that those filters are weak to prompts which use even simple means of evasion.
Prompt Injection
You may have seen in your social media timeline a flurry of screenshots depicting peculiar conversations with ChatGPT or Bing. These conversations would often start with the phrase “Ignore all previous instructions”, or “Pretend to be an actor”, followed by an unfiltered response. This is one of the earliest filter bypass techniques called Prompt Injection. It shows that a specially crafted request can coerce the LLM into ignoring its internal filters and producing unintended, hostile, or outright malicious output. Twitter users are having a lot of fun poking models linked up to a Twitter account with prompt injection!

Sometimes, an unfiltered bot response can appear as though there is also another action behind it. For example, it might seem that the bot is running a shell command or scanning the AI’s network range. In most cases, this is just smoke and mirrors, providing that the model doesn’t have any other capacity than text generation – and most of them don’t.
However, every now and again, we come across a curiosity, such as the Streamlit MathGPT application. To answer user-generated math questions, the app converts the received prompt into Python code, which is then executed by the model in order to return the result of the ‘calculation’. This approach is just asking for arbitrary code execution via Prompt Injection! Needless to say, it’s always a tremendously bad idea to run user-generated code.
In another recently demonstrated attack technique, called Indirect Prompt Injection, researchers were able to turn the Bing chatbot into a scammer in order to exfiltrate sensitive data.

Once AI models begin to interact with APIs at an even larger scale, there’s little doubt that prompt injection attacks will become an increasingly consequential attack vector.
Code Vulnerabilities & Bugs
Leaving the problem of malicious intent aside for a while, let’s take a look at “accidental” damage that might be caused by LLM-based tools, namely – code vulnerabilities.
If we all wrote 100% secure code, bug bounty programs wouldn’t exist, and there wouldn’t be a need for CVE / CWE databases. Secure coding is an ideal that we strive towards but one that we occasionally fall short of in a myriad of different ways. Are pair-programming tools, such as CoPilot, going to solve the problem by producing better, more secure code than a human programmer? It turns out not necessarily – in some cases, they might even introduce vulnerabilities that an experienced developer wouldn’t ever fall for.
Since code generation models are trained on a corpus of human-written code, it’s inevitable that from the speckled history of coding practices, they are also going to learn a bad habit or two. Not to mention that these models have no means of distinguishing between good and bad coding practices.
Recent research into how secure is CoPilot-generated code draws a conclusion that despite introducing fewer vulnerabilities than a human overall: “Copilot is more susceptible to introducing some types of vulnerability than others and is more likely to generate vulnerable code in response to prompts that correspond to older vulnerabilities than newer ones.”
It’s not just about vulnerabilities, though; relying on AI pair programmers too much can introduce any number of bugs into a project, some of which may take more time to debug than it would have taken to code a solution to the given problem from scratch. This is especially true in the case of generating large portions of code at a time or creating entire functions from comment suggestions. LLM-equipped tools require a great deal of oversight to ensure they are working correctly and not inserting inefficiencies, bugs, or vulnerabilities into your codebase. The convenience of having tab completion at your fingertips comes at a cost.
Data Privacy
When we get our hands on a new exciting technology that makes our life easier and more fun, it’s hard not to dive into it and reap its benefits straight away – especially if it’s provided for free. But we should be aware by now that if something comes free of charge, we more than likely pay for it with our data. The extent of privacy implications only becomes clear after the initial excitement levels down, and any measures and guidelines tend to appear once the technology is already widely adopted. This happened with social networks, for example, and is on course to happen with LLMs as well.
The terms and conditions agreement for any LLM-based service should state how our request prompts are used by the service provider. But these are often lengthy texts written in a language that is difficult to follow. If we don’t fancy spending hours deciphering the small print, we should assume that every request we make to the model is logged, stored, and processed in one way or another. At a minimum, we should expect that our inputs are fed into the training dataset and, therefore, could be accidentally leaked in outputs for other requests.
Moreover, many providers might opt to make some profit on the side and sell the input data to research firms, advertisers, or any other interested third party. With AI quickly being integrated into widely used applications, including workplace communication platforms such as Slack, it’s worth knowing what data is shared (and for which purpose) in order to ensure that no confidential information is accidentally leaked.

Data leakage might not be much of a concern for private users – after all, we are quite accustomed to sharing our data with all sorts of vendors. For businesses, governments, and other institutions, however, it’s a different story. Careless usage of LLMs in a workplace can result in the company facing a privacy breach or intellectual property theft. Some big corporations have already banned the use of ChatGPT and similar tools by their employees for fear that sensitive information and intellectual property might be leaked in this way.
Memorization
While the main goal of LLMs is to retain a level of understanding of their target domain, they can sometimes remember a little too much. In these situations, they may regurgitate data from their training set a little too closely and inadvertently end up leaking secrets such as personally identifiable information (PII), access tokens, or something else entirely. If this information falls into the wrong hands, it’s not hard to imagine the consequences.
It should be said that this inadvertent memorization is a different problem from overfitting, and not an easy one to solve when dealing with generative sequence models like LLMs. Since LLMs appear to be scraping the internet in general, it’s not out of the question to say that they may end up picking something of yours, as one person recently found out.

That’s Not All, Folks!
Security and privacy are not the only pitfalls of generative AI. There are also numerous issues from legal and ethical perspectives, such as the accuracy of the information, the impartiality of the advice, and the general sanity of the answers provided by LLM-powered digital assistants.
We discuss these matters in-depth in the second installment of this article.
Related Research




Stay Ahead of AI Security Risks
Get research-driven insights, emerging threat analysis, and practical guidance on securing AI systems—delivered to your inbox.