The Tactics Techniques of Adversarial Machine Learning
August 23, 2022





Attacks on Machine Learning – Explained
Introduction
Previously, we discussed the emerging field of adversarial machine learning, illustrated the lifecycle of an ML attack from both an attacker’s and defender’s perspective, and gave a high-level introduction to how ML attacks work. In this blog, we take you further down the rabbit hole by outlining the types of adversarial attacks that should be on your security radar.
We aim to acquaint the casual reader with adversarial ML vocabulary and explore the various methods by which an adversary can compromise models and conduct attacks against ML/AI systems. We introduce attacks performed in both controlled and real-world scenarios as well as highlight open-source software for offensive and defensive purposes. Finally, we touch on what we’ll be working towards in the coming months to help educate ML practitioners and cybersecurity experts in protecting their most precious assets from bad actors, who seek to degrade the business value of AI/ML.
Before we begin, it is worth noting that while “adversarial machine learning” typically refers to the study of mathematical attacks (and defenses) on the underlying ML algorithms, people often use the term more freely to encompass attacks and countermeasures at any point during the MLOps lifecycle. MLSecOps is also an excellent term when discussing the broader security ecosystem during the operationalization of ML and can help to prevent confusion with pure AML.
Attack breakdown
Traditionally, attacks against machine learning have been broadly categorized alongside two axes: the information the attacker possesses and the timing of the attack.
In terms of information, if an attacker has full knowledge of a model, such as parameters, features, and training data, we’re talking about a white-box attack. Conversely, if the attacker has no knowledge whatsoever about the inner workings of the model and just has access to its predictions, we call it a black-box attack. Anything in between these two falls into the grey-box category.
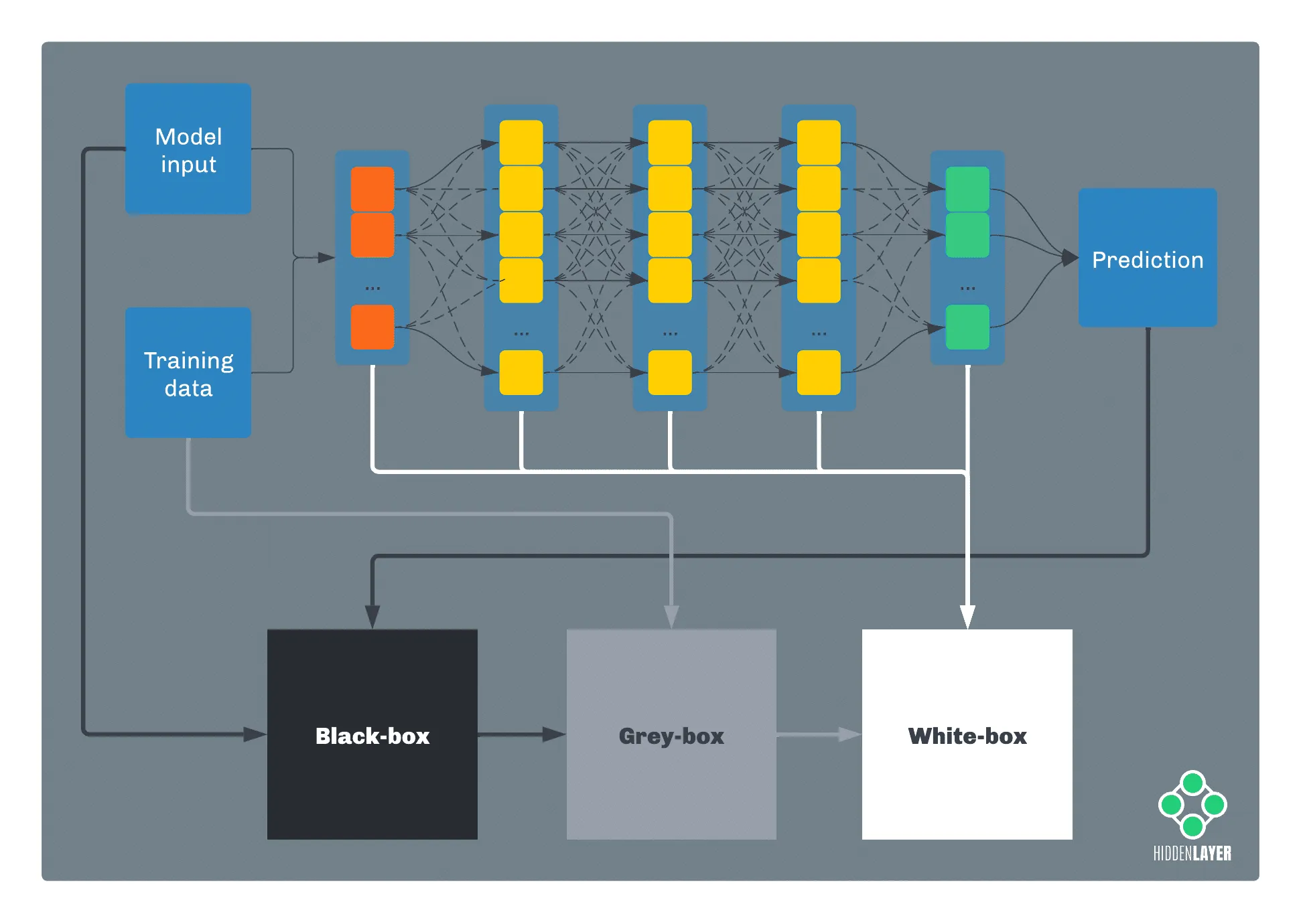
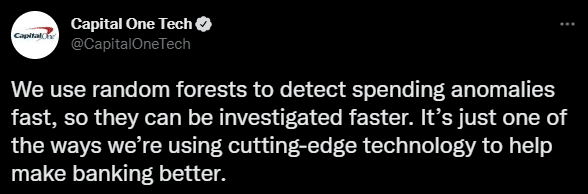
In practice, an adversary will often start from a black-box perspective and attempt to elevate their knowledge, for example, by performing inference or oracle attacks (more on that later). Often, sensitive information about a target model can be acquired by more traditional means, such as open-source intelligence (OSINT), social engineering, cyberespionage, etc. Occasionally, marketing departments will even reveal helpful details on Twitter:
In terms of timing, an attacker can either target the learning algorithm during the model training phase or target a pre-trained model when it makes a decision.
Attacks during training time aim to influence the learning algorithm by tampering with the training data, leading to an inaccurate or biased model (known as data poisoning attacks).
Decision-time attacks can be divided into two major groups: oracle attacks, where the attacker queries the model to obtain clues about the model’s internals or the training data; and evasion attacks, in which the attacker tries to find the way to fool the model to evade the correct prediction.
Both training-time and decision-time attacks often leverage statistical risk vectors, such as bias and drift. If an attack relies on exploiting existing anomalies in the model, we call it a statistical attack.
While all the attacks can be assigned a label associated with the information axis (an attacker either has knowledge about the model or has not), the same is not always true for the timing axis. Model hijacking attacks, which rely on embedding malicious payloads in an ML model through tampering and data deserialization flaws, can either occur at training or at decision time. For instance, an attacker could insert a payload by tampering with the model at training time or by altering a pre-trained model offered for distribution via a model zoo, such as HuggingFace.
Now that we understand the basic anatomy of attack tactics let’s delve deeper into some techniques.
Training-Time Attacks
The model training phase is one of the crucial phases of building an ML solution. During this time, the model learns how to behave based on the inputs from the training dataset. Any malicious interference in the learning process can significantly impact the reliability of the resulting model. As the training dataset is the usual target for manipulation at training time, we use the term data poisoning for such attacks.
Data Poisoning Attacks
Suppose an adversary has access to the model’s training dataset or possesses the ability to influence it. In this case, they can manipulate the data so that the resulting model will produce biased or simply inaccurate predictions. In some cases, the attacker will only be interested in lowering the overall reliability of the model by maximizing the ratio of erroneous predictions, for example, to discredit the model’s efficiency or to get the opposite outcome in a binary classification system. In more targeted attacks, the adversary’s aim is to selectively bias the model, so it gives wrong predictions for specific inputs while being accurate for all others. Such attacks can go unnoticed for an extended period of time.
Attackers can perform data poisoning in two ways: by modifying entries in the existing dataset (for example, changing features or flipping labels) or injecting the dataset with a new, specially doctored portion of data. The latter is hugely relevant as many online ML-based services are continually re-trained on user-provided input.
Let’s take the example of online recommendation mechanisms, which have become an integral part of the modern Internet, having been widely implemented across social networks, news portals, online marketplaces, and media streaming platforms. The ML models that assess which content will be most interesting/relevant to specific users are designed to change and evolve based on how the users interact with the system. An adversary can manipulate such systems by supplying large volumes of “polluted” content, i.e., content that is meant to sway the recommendations one way or the other. Content, in this context, can mean anything that becomes features for the model based on a user’s behavior, including site visits, link clicks, posts, mentions, likes, etc.
Other systems that make use of online-training models or continuous-learning models and are therefore susceptible to data poisoning attacks include:
- Text auto-complete tools
- Chatbots
- Spam filters
- Intrusion detection systems
- Financial fraud prevention
- Medical diagnostic tools
Data poisoning attacks are relatively easy to perform even for uninitiated adversaries because creating “polluted” data can often be done intuitively without needing any specialist knowledge. Such attacks happen daily: from manipulating text completion mechanisms to influencing product reviews to political disinformation campaigns. F-Secure published a rather pertinent blog on the topic outlining ‘How AI is already being poisoned against you.’
Byzantine attacks
In a traditional machine learning scenario, the training data resides within a single machine or data center. However, many modern ML solutions opt for a distributed learning method called federated (or collaborative) learning, where the training dataset is scattered amongst several independent devices (think Siri, being trained to recognize your voice). During federated learning, the ML model is downloaded and trained locally on each participating edge device. The resulting updates are either pushed to the central server or shared directly between the nodes. The local training dataset is private to the participating device and is never shared outside of it.
Federated learning helps companies maximize the amount and diversity of the training data while preserving the data privacy of collaborating users. Offering such advantages, it’s not surprising that this approach has become widely used in various solutions: from everyday-use mobile phone applications to self-driving cars, manufacturing, and healthcare. However, delegating the model training process to an often random and unverified cohort of users amplifies the risk of training-time attacks and model hijacking.
Attacks on federated learning in which malicious actors operate one or more participating edge devices are called byzantine attacks. The term comes from distributed computing systems, where a fault of one of the components might be difficult to spot and correct due to the very component malfunction (Byzantine fault). Likewise, it might be challenging in a federated learning network to spot malicious devices that regularly tamper with the training process or even hijack the model by injecting it with a backdoor.
Decision-Time Attacks
Decision-time attacks (a.k.a. testing-time attacks, a.k.a inference-time attacks) are attacks performed against ML/AI after it has been deployed in some production setting, whether on the endpoint or in the cloud. Here the ML attack surface broadens significantly as adversaries try to discover information about training data and feature sets, evade/bypass classifications, and even steal models entirely!
Terminology
Several decision-time attacks rely on inference to create adversarial examples, so let’s first give a quick overview of what they are and how they’re crafted before we explore some more specific techniques.
Adversarial Examples
Maliciously crafted inputs to a model are referred to as adversarial examples, whether the features are extracted from images, text, executable files, audio waveforms, etc., or automatically generated. The purpose of an adversarial example is typically to evade classification (for example, dog to cat, spam to not spam, etc.), but they can also be helpful for an attacker to learn the decision boundaries of a model.
In a white-box scenario, several algorithms exist to auto-generate adversarial examples, for example, Gradient-based evasion attack, Fast Gradient Sign Method (FGSM), and Projected Gradient Descent (PGD). In a black-box scenario, nothing beats a bit of old-fashioned domain expertise, where understanding the feature space, combined with an attacker’s intuition, can help to narrow down the most impactful features to selectively target for modification.
Further approaches exist to help generate and rank vast quantities of adversarial examples en-masse, with reinforcement learning and generative adversarial networks (GANs) proving a popular choice amongst attackers for bulk generating adversarial examples to conduct evasion attacks and perform model theft.
Inference
At the core of most, if not all, decision-time attacks lie inference, but what is it?
In the broader context of machine learning, inference is the process of running live data (as opposed to the training/test/validation set) on the already-trained model to obtain the model scores and decision boundaries. In other words, inference is the post-deployment phase, where the model infers the predictions based on the features of input data. Decision-time and inference-time terms are often used interchangeably.
In the context of adversarial ML, we talk about inference when a specific data mining technique is used to leak sensitive information about the model or training dataset. In this technique, the knowledge is inferred from the outputs the model produces for a specially prepared data set.
In the following example, the unscrupulous attacker submits the accepted input data, e.g., a vectorized image, binary executable, etc., and records the results, i.e., the model’s classification. This process is repeated cyclically, with the attacker continually modifying the input features to derive new insight and infer the decisions the model makes.
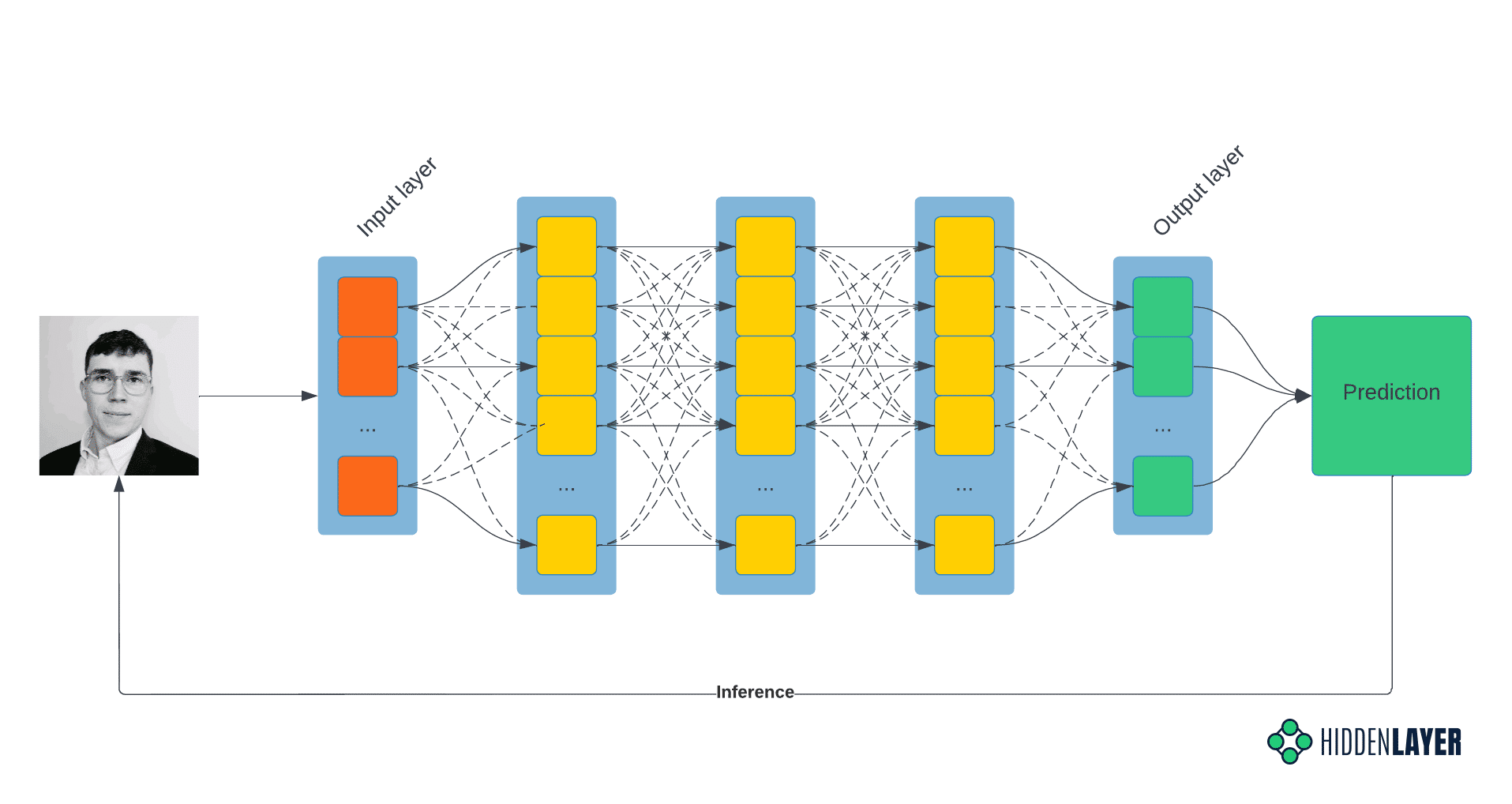
Typically, the greater an adversaries’ knowledge of your model, features, and training data, the easier it becomes to generate subtly modified adversarial examples that cross decision boundaries, resulting in misclassification by the model and revealing decision boundaries to the attacker, which can help craft subsequent attacks.
Evasion Attacks
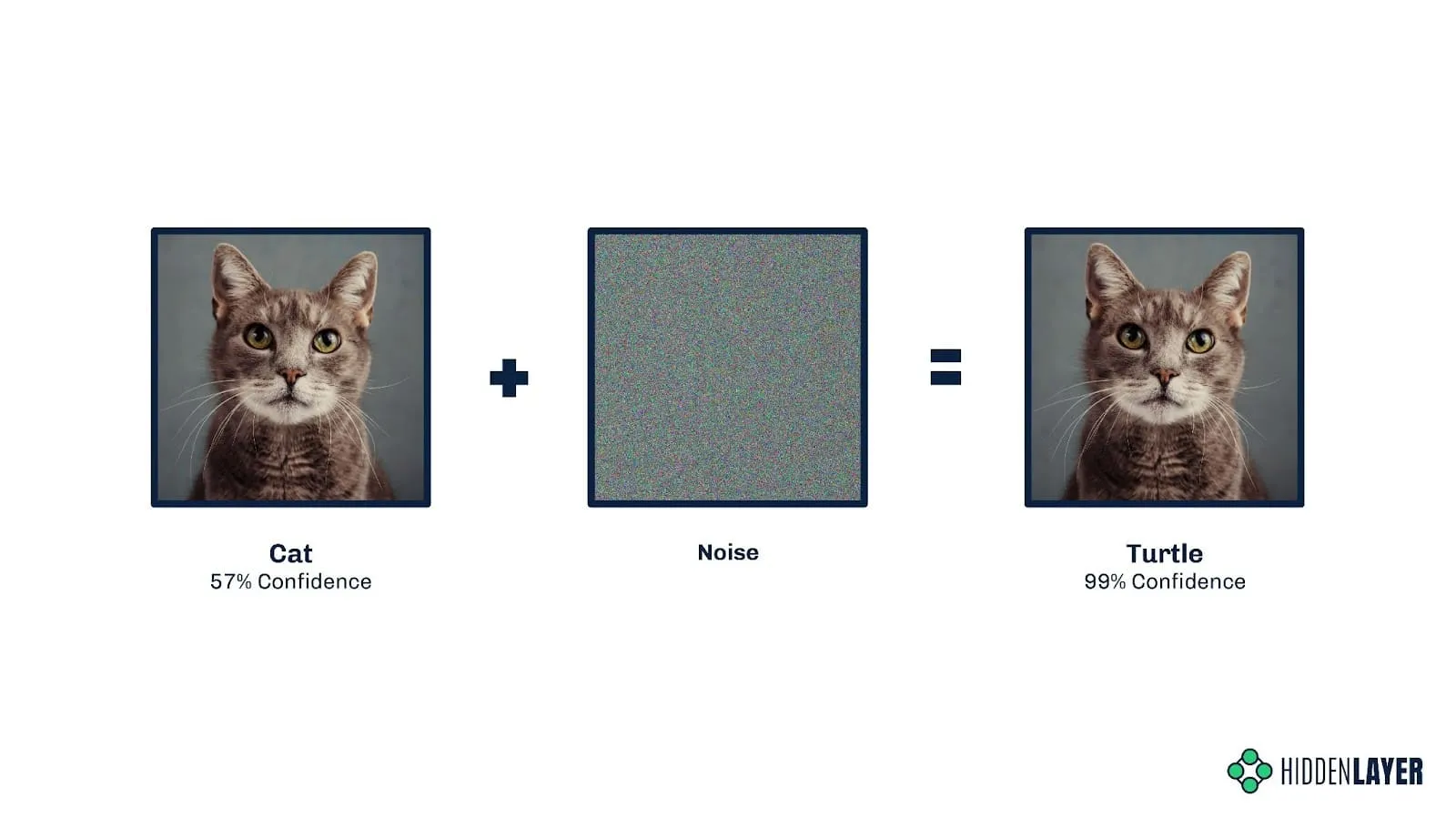
Evasion attacks, known in some circles as model bypasses, aim to perturb input to a model to produce misclassifications. In simple terms, this could be modifying pixels in an image by adding noise or rotating images, resulting in a model misclassifying an image of a cat as a fox, for example, which would be an unmitigated disaster for biometric cat flap access control systems! Attackers have been tampering with model input features since the advent of Bayesian email spam filtering, adding “good” words to emails to decrease the chances of ML classifiers tagging a mail as spam.
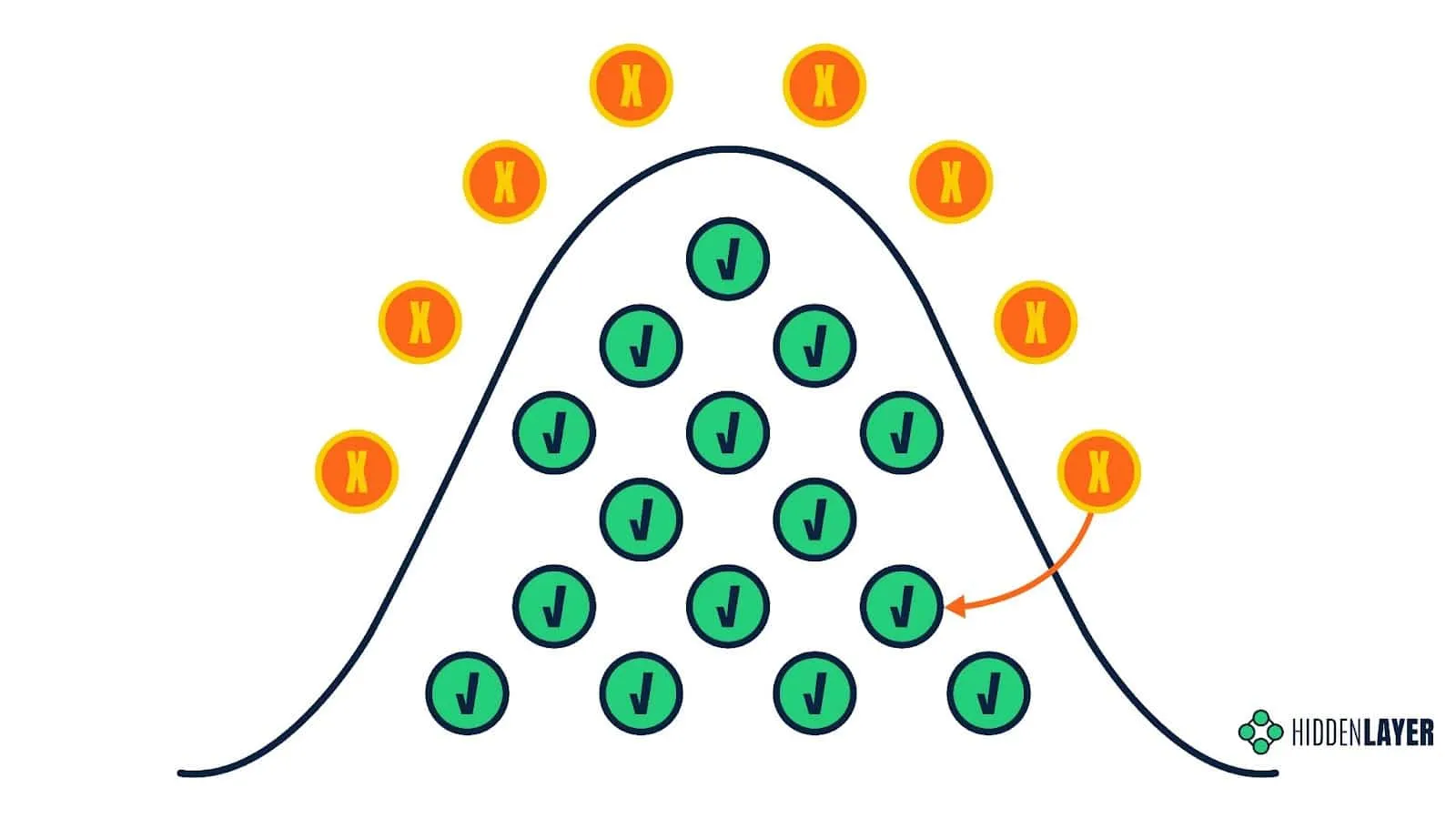
Creating such adversarial examples usually requires decision-time access to the model or a surrogate/proxy model (more on this in a moment). With a well-trained surrogate model, an attacker can infer if the adversarial example produces the desired outcome. Unless an attacker is extremely fortunate to create such an example without any testing, evasion attacks will almost always use inference as a starting point.
A notable instance of an evasion attack was the Skylight Cyber bypass of the Cylance anti-virus solution in 2019, which leveraged inference to determine a subset of strings that, when embedded in malware, would trick the ML model into classifying malicious software as benign. This attack spawned several anti-virus bypass toolkits such as MalwareGym and MalwareRL, where evasion attacks have been combined with reinforcement learning to automatically generate mutations in malware that make it appear benign to malware classification models.
Oracle Attacks
Not to be mistaken with Oracle, the corporate behemoth; oracle attacks allow the attacker to infer details about the model architecture, its parameters, and the data the model was trained on. Such attacks again rely fundamentally on inference to gain a grey-box understanding of the components of a target model and potential points of vulnerability therein. The NIST Taxonomy and Terminology of Adversarial Machine Learning breaks down oracle attacks into three main subcategories:
Extraction Attacks - “an adversary extracts the parameters or structure of the model from observations of the model’s predictions, typically including probabilities returned for each class.”
Inversion Attacks - “the inferred characteristics may allow the adversary to reconstruct data used to train the model, including personal information that violates the privacy of an individual.”
Membership Inference Attacks - “the adversary uses returns from queries of the target model to determine whether specific data points belong to the same distribution as the training dataset by exploiting differences in the model’s confidence on points that were or were not seen during training.”
Hopefully, by now, we’ve adequately explained adversarial examples, inference, evasion attacks, and oracle attacks in a way that makes sense. The lines between these definitions can appear blurred depending on what taxonomy you subscribe to, but the important part is the context of how they work.
Model Theft
So far, we’ve focused on scenarios in which the adversaries aim to influence or mislead the AI, but that’s not always the case. Intellectual property theft - i.e., stealing the model itself - is a different but very credible motivation for an attack.
Companies invest a lot of time and money to develop and train advanced ML solutions that outperform their competitors. Even if the information about the model and the dataset it’s trained on is not publicly available, the users can often query the model (e.g., through a GUI or an API), which might be enough for the adversary to perform an oracle attack.
The information inferred via oracle attacks can not only be used to improve further attacks but can also help reconstruct the model. One of the most common black-box techniques involves creating a so-called surrogate model (a.k.a. proxy model, a.k.a shadow model) designed to approximate the decision boundaries of the attacked model. If the approximation is accurate enough, we can talk of de-facto model replication.
Such replicas may be used to create adversarial examples in evasion attacks, but that’s not where the possibilities end. A dirty-playing competitor could attempt model theft to give themselves a cheap and easy advantage from the beginning, without the hassle of finding the right dataset, labeling feature vectors, and bearing the cost of training the model themselves. Stolen models could even be traded on underground forums in the same manner as confidential source code and other intellectual property.
Model theft examples include the proof-of-concept code targeting the ProofPoint email scoring model (GitHub - moohax/Proof-Pudding: Copy cat model for Proofpoint) as well as intellectual property theft through model replication of Google Translate (Imitation Attacks and Defenses for Black-box Machine Translation Systems).
Statistical Attack Vectors
In discussing the various attacks to feature in this blog, we realized that bias and drift might also be considered attack vectors, albeit in the nontraditional sense. That is not to say that we wish to redefine these intrinsic statistical features of ML, more so to introduce them as potential vectors for attack when an attacker’s wish is to incur ill outcomes such as reputation loss upon the target company or manipulate a model into inaccurate classification. The next question is, do we consider them training time attacks or decision time attacks? The answer lies somewhere in the middle. In models trained in a ‘set and forget’ fashion, bias and drift are often considered only at initial training or retraining time. However, in instances where models are continually trained on incoming data, such as the case of recommendation algorithms, bias and drift are very much live factors that can be influenced using inference and a little elbow grease. Given the variability of when these features can be introduced and exploited, we elected to use the term statistical attack to represent this nuanced attack vector.
Bias
In the context of ML, bias can be viewed through a couple of different lenses. In the statistical sense, bias is the difference between the derived results (i.e., model prediction) and what is known to be fact or ground truth. From a more general perspective, bias can be considered a prejudice or skewing towards a particular data point. Models that contain this systemic error are said to be either high-bias or low-bias, with a model that lies in between being considered a ‘good fit’ (i.e., little difference between the prediction and ground truth). High/Low bias is commonly referred to as underfitting or overfitting, respectively. It is commonly said that an ML model is only good as its training data, and in this case, biased training data will produce biased results. See below, where a face depixelizer model transforms a pixelized Barrack Obama into a caucasian male:

Image Source: https://twitter.com/Chicken3gg/status/1274314622447820801
While bias may sound like an issue for data scientists and ML engineers to consider, the potential ramifications of a model which expresses bias extend far beyond. As we touched on in our blog: Adversarial Machine Learning - The New Frontier, ML makes critical decisions that directly impact daily life. For example, a mortgage loan ML model with high bias may refuse applications of minority groups at a higher rate. If this sounds oddly familiar, you may have seen this article from MIT Technology Review last year, which discusses exactly that.
You may be wondering by now how bias could be introduced as a potential attack vector, and the answer to that largely depends on how ambitious or determined your attacker is. Attackers may look to discover forms of bias that may already exist in a model or go as far as to introduce bias by poisoning the training data. The intended consequence or outcome of such an attack being to cause socio-economic damage or reputational harm to the company or organization in question.
Drift
The accuracy of an ML model can spontaneously degrade over time due to unforeseen or unconsidered changes in the environment or input. A model trained on historical data will perform poorly if the distribution of variables in production data significantly differs from the training dataset. Even if the model is periodically retrained to keep on top of gradually changing trends and behaviors, an unexpected event can have a sudden impact on the input data and, therefore, on the quality of the predictions. The susceptibility of model predictions to changes in the input data is called data drift.
The model’s predictive power can also be affected if the relationship between the input data and the expected output changes, even if the distribution of variables stays the same. The predictions that would be considered accurate at some point in time might prove completely inaccurate under new circumstances. Take a search engine and the Covid pandemic as an example: since the outbreak, people searching for keywords such as “coronavirus” are far more likely to look for results related to Covid-19 and not just generic information about coronaviruses. The expected output for this specific input has changed, so the results that would be valid before the outbreak might now seem less relevant. The susceptibility of model predictions to changes in the expected output is called concept drift.
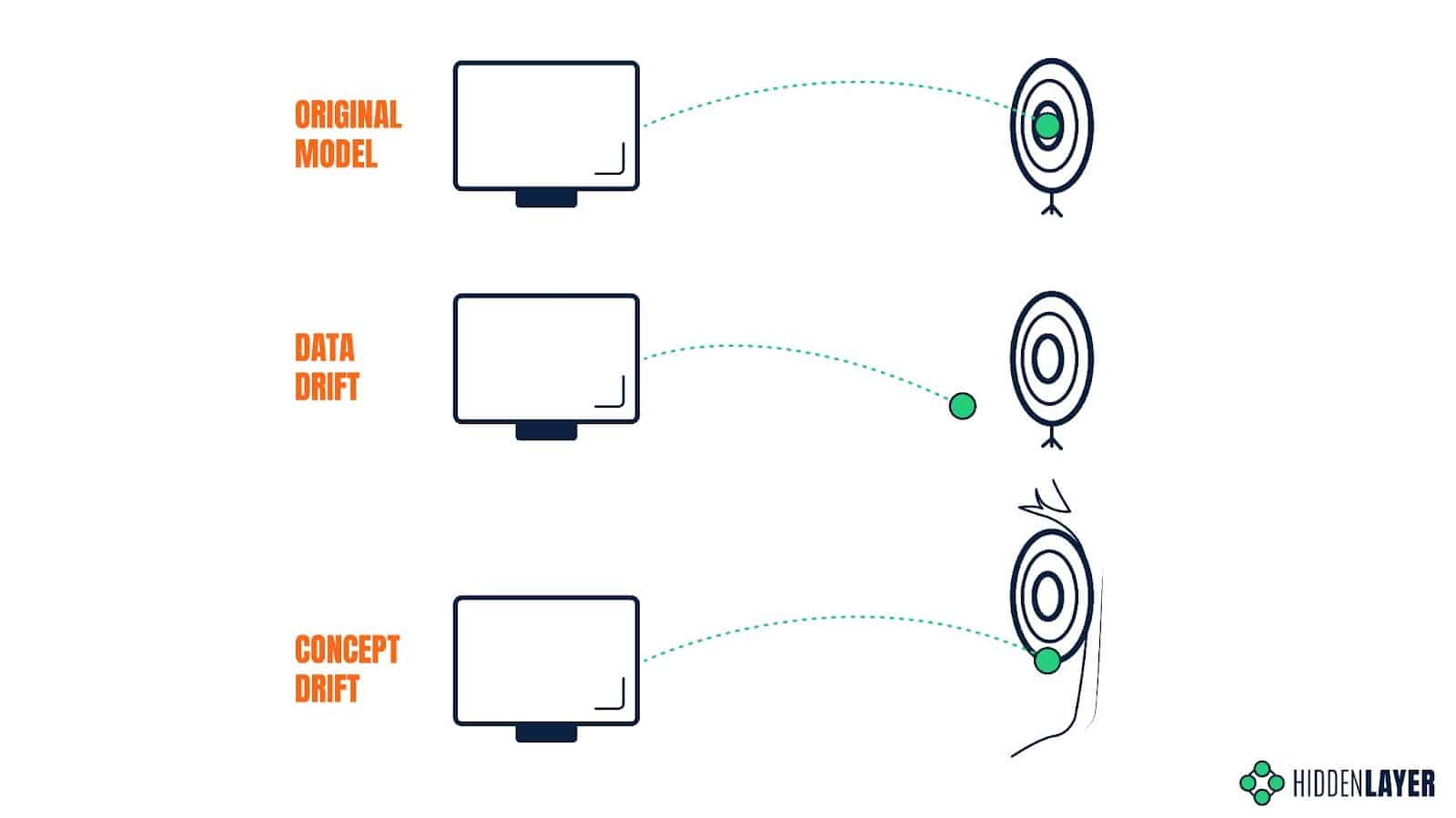
Attackers can induce data drift using data poisoning techniques, or exploit concept drift to achieve their desired outcomes.
Model Hijacking Attacks
Outside of training/decision-time attacks, we find ourselves also exploring other attacks against models, be it tampering with weights and biases of neural networks stored on-disk or in-memory, or ways in which models can be trained (or retrained) to include “backdoors.” We refer to these attacks as “model hijacking,” which may result in an attacker being able to intercept model features, modify predictions or even deploy malware via pre-trained models.
Backdoored Models
In the context of adversarial machine learning, the term “backdoor” doesn’t refer to a traditional piece of malware that an attacker can use to access a victim’s computer remotely. Instead, it describes a malicious module injected into the ML model that introduces some secret and unwanted behavior. This behavior can then be triggered by specific inputs, as defined by the attacker.
In deep neural networks, such a backdoor is referred to as a neural payload and consists of two elements: the first is a layer (or network of layers) implementing the trigger detection mechanism and the second is some conditional logic to be executed when specific input is detected. As demonstrated in the DeepPayload: Black-box Backdoor Attack on Deep Learning Models through Neural Payload Injection paper, a neural payload can be injected into a compiled model without the need for the attacker to have access to the underlying learning algorithm or the training process.

A skillfully backdoored model can appear very accurate on the surface, performing as expected with the regular dataset. However, it will misclassify every input that is perturbed in a certain way - a way that is only known to the adversary. This knowledge can then be sold to any interested party or used to provide a service that will ensure the customers get the desired outcome.
As opposed to data poisoning attacks, which can influence the model through tampering with the training dataset, planting a backdoor in an ML model requires access to the model - be it in raw or compiled/binary form. We mentioned before that in many scenarios, models are re-trained based on the user’s input, which means that the user has de facto control over a small portion of the training dataset. But how can a malicious actor access the ML model itself? Let’s consider two risk scenarios below.
Hijacking of Publicly Available Models
Many ML-based solutions are designed to run locally and are distributed together with the model. We don’t have to look further than the mobile applications hosted on Google Play or Apple Store. Moreover, specialized repositories, or model zoos, like Hugging Face, offer a range of free pre-trained models; these can be downloaded and used by entry-level developers in their apps. If an attacker finds a way to breach the repository the model/application is hosted on, they could easily replace it with its backdoored version. This form of tampering could be mitigated by introducing a requirement for cryptographic signing and model verification.
Malevolent Third-Party Machine Learning Contractors
Maintaining the competitiveness of an AI solution in a rapidly evolving market often requires solid technical expertise and significant computational resources. Smaller businesses that refrain from using publicly available models might instead be tempted to outsource the task of training their models to a specialized third party. Such an approach can save time and money, but it requires much trust, as a malevolent contractor could easily plant a backdoor in the model they were tasked to train.
The idea of planting backdoors in deep neural networks was recently discussed at length from both white-box and black-box perspectives.
Trojanized Models
Although not an adversarial ML attack in the strictest sense of the term, trojanized models aim to exploit weaknesses in model file formats, such as data deserialization vulnerabilities and container flaws. Attacks arising from trojanized models may include:
- Remote code execution and other deserialization vulnerabilities (neatly highlighted by Fickling - A Python pickling decompiler and static analyzer).
- Denial of service (for example, Zip bombs).
- Staging malware in ML artifacts and container file formats.
- Using steganography to embed malicious code into the weights and biases of neural networks, for example, EvilModel.
With a lack of cryptographic signing and verification of ML artifacts, model trojanizing can be an effective means of performing initial compromise (i.e., deploying malware via pre-trained models). It is also possible to perform more bespoke attacks to subvert the prediction process, as highlighted by pytorchfi, a runtime fault injection tool for PyTorch.
Vulnerabilities
It would be remiss not to mention more traditional ways in which machine learning systems can be affected. Since ML solutions naturally depend on software, hardware, and (in most cases) network connection, they face the same threats as any other IT system. They are exposed to vulnerabilities in 3rd party software and operating system; they can be exploited through CPU and GPU attacks, such as side-channel and memory attacks; finally, they can fall victim to DDoS attacks, as well as traditional spyware and ransomware.
GPU-focused attacks are especially relevant here, as complex deep neural networks (DNNs) usually rely on graphic processors for better performance. Unlike modern CPUs, which evolved to implement many security features, GPUs are often overlooked as an attack vector and, therefore, poorly protected. A method of recovering raw data from the GPU was presented in 2016. Since then, several academic papers have discussed DNN model extraction from GPU memory, for example, by exploiting context-switching side channel or via Hermes attack. Researchers also managed to invalidate model computations directly inside GPU memory in the so-called Mind Control attack against embedded ML solutions.
Discussing broader security issues surrounding IT systems, such as software vulnerabilities, DDoS attacks, and malware, is outside of the scope of this article, but it’s definitely worth underlining that threats to ML solutions are not limited to attacks against ML algorithms and models.
Defending Against Adversarial Attacks
At the risk of doubling the length of this blog, we have decided to make adversarial ML defenses the topic of our subsequent write-up, but it’s worth touching on a couple of high-level considerations now.
Each stage of the MLOps lifecycle has differing security considerations and, consequently, different forms of defense. When considering data poisoning attacks, role-based access controls (RBAC), evaluating your data sources, performing integrity checks, and hashing come to the fore. Additionally, tools such as IBM’s Adversarial Robustness Toolbox (ART) and Microsoft’s Counterfit can help to evaluate the “robustness” of ML/AI models. With the dissemination of pre-trained models, we look to model signing and trusted source verification. In terms of defending against decision time attacks, techniques such as gradient masking and model distillation can also increase model robustness. In addition, a machine learning detection and response (MLDR) solution can not only alert you if you’re under attack but provide mitigation mechanisms to thwart adversaries and offer contextual threat intelligence to aid SOC teams and forensic investigators.
While the aforementioned defenses are not by any means exhaustive, they help to illustrate some of the measures we can take to safeguard against attack.
About HiddenLayer
HiddenLayer helps enterprises safeguard the machine learning models behind their most important products with a comprehensive security platform. Only HiddenLayer offers turnkey AI/ML security that does not add unnecessary complexity to models and does not require access to raw data and algorithms. Founded in March of 2022 by experienced security and ML professionals, HiddenLayer is based in Austin, Texas, and is backed by cybersecurity investment specialist firm Ten Eleven Ventures. For more information, visit www.hiddenlayer.com and follow us on LinkedIn or Twitter.
Related Insights



.svg)
Thanks for joining us!
will be on the way soon.