For the best experience, this project uses the Webflow Input Enhancer extension. We highly recommend installing it. Click here to download (use preview mode to access link)
2026 AI Threat Landscape Report
The most comprehensive security platform for AI
Backed by patented technology and industry-leading adversarial AI research, our platform provides AI Discovery, AI Supply Chain Security, AI Attack Simulation, and AI Runtime Security.
Trusted by Industry Leaders
Understanding Today’s AI Risk Landscape
AI is showing up everywhere.
Developers are embedding AI into tools and workflows faster than security teams can track, leaving blind spots that grow before anyone notices.
Most companies rely on AI from outside sources.
Third-party models introduce unknown code and vulnerabilities, and it’s hard to secure what you didn’t build yourself.
What happens when your AI is attacked?
Traditional tools can’t test or predict how applications behave under pressure, making it hard to know if your defenses actually work.
AI security isn’t built into company playbooks yet.
Most organizations lack the tools and plans to detect or respond when AI systems are compromised.
The HiddenLayer AI Security Platform secures agentic, generative, and predictive AI applications across the entire lifecycle, protecting IP, ensuring compliance, and enabling safe adoption at enterprise scale.
The HiddenLayer AI Security Platform
Our platform proactively defends against the full spectrum of AI threats, safeguarding your IP, compliance posture, and enterprise operations.
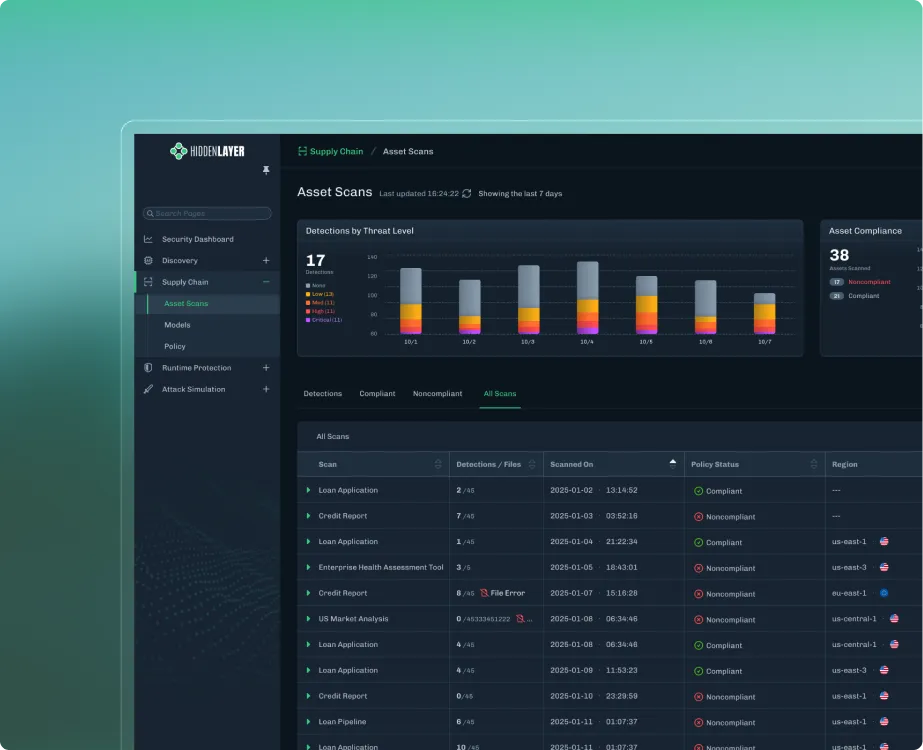
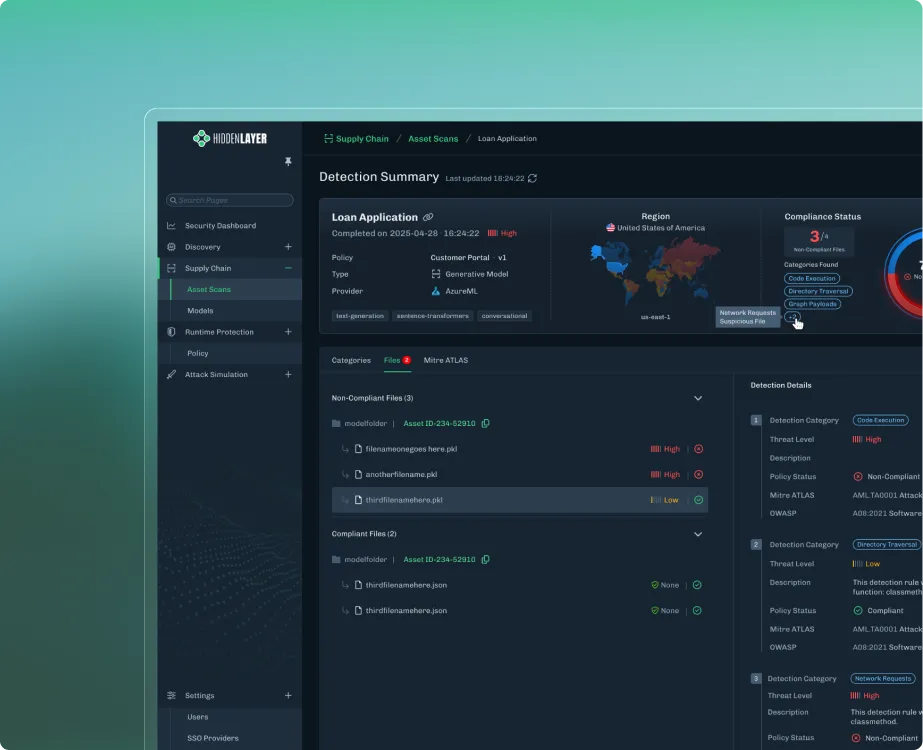
Identify and build an inventory of the AI applications, models, and assets in your environment.
Analyze, identify risks, and protect your AI applications, models, and assets as you build.
Continually identify threats and validate defenses to safeguard agentic and generative AI applications at scale.
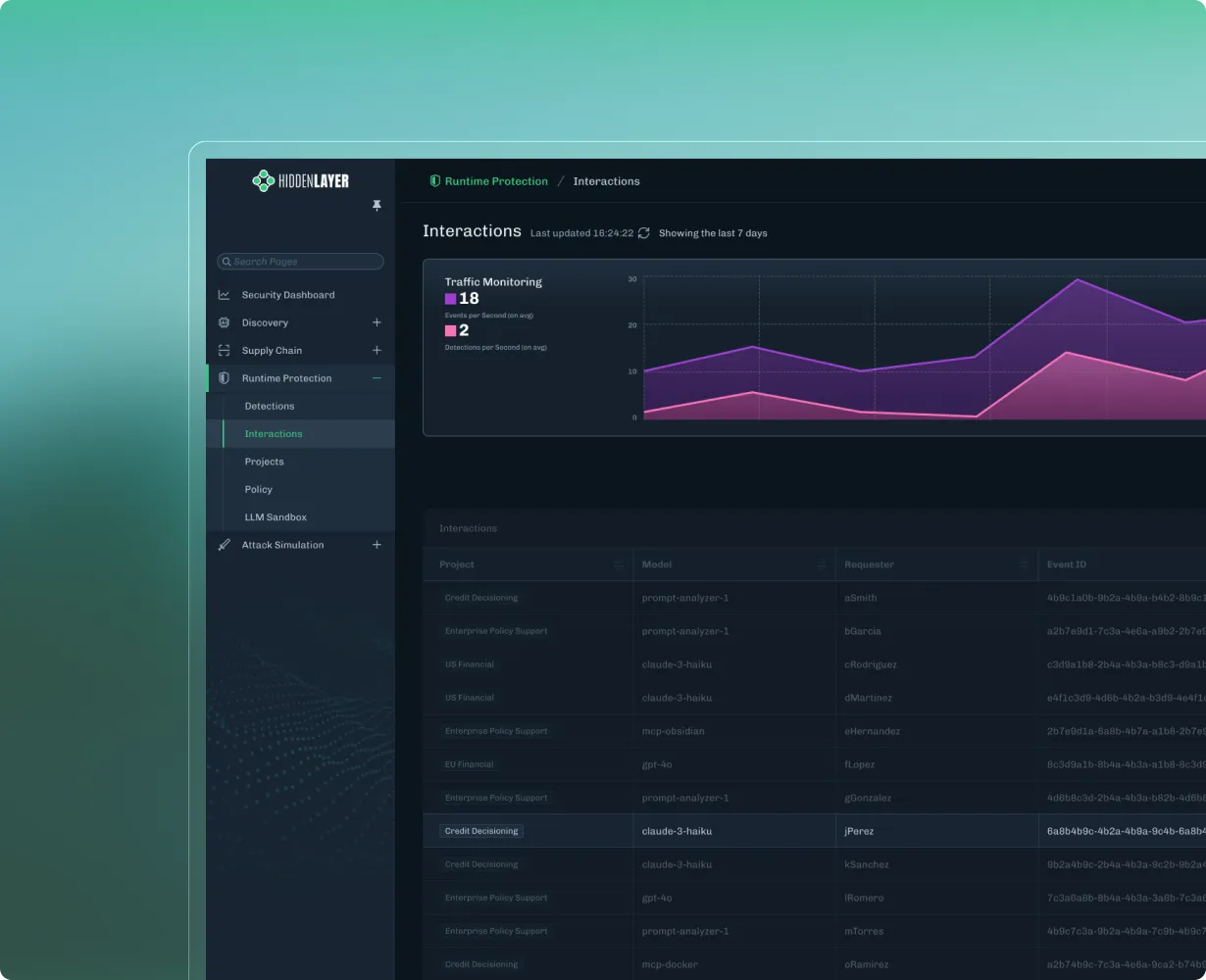
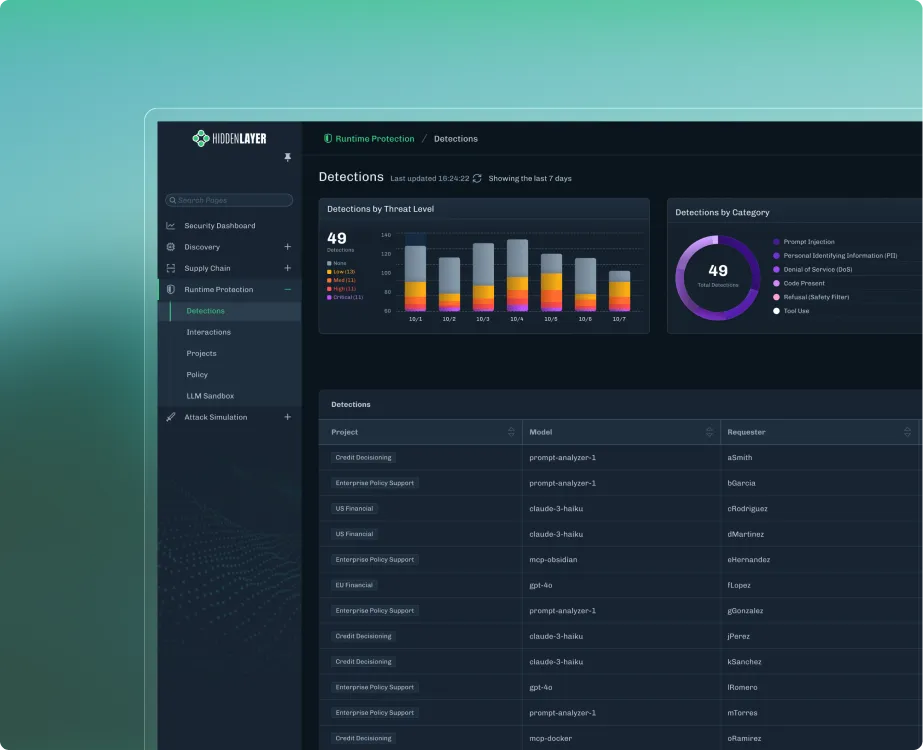
Firewall to monitor, detect, and respond real-time to adversarial threats on agentic and generative AI applications.
Native Integrations
Simplified deployment with pre-built integrations into CI/CD, MLOps, Data Pipelines, and SIEM/SOAR.
The Data Backs Us Up
75
%
+
Reduction in exposure to AI exploits
50
+
𝘊𝘝𝘌𝘴
Disclosed through our security research
30
+
Issued patents
Use Cases
Secure your AI with precision-built defenses.
01
Model Scanning
Detect hidden risks in third-party and proprietary models.
02
Red Teaming
Identify threats early and validate defenses continuously.
03
AI Guardrails
Prevent misuse, data leakage, and adversarial attacks with policy-based controls.
04
Agentic and MCP Protection
Safeguard autonomous systems and protect against rogue behavior.
Solutions by Role and Industry
Address your AI Security needs by a specific industry or role.
Financial Services
Securely Innovate with AI for Fraud Detection, Trading, Compliance, and Customer Engagement.
AI Executives
Accelerate AI innovation, safely and confidently.
US Federal
Protect Agentic, Generative, and Predictive AI Systems for Mission Assurance.
CISO
Protect AI applications from adversarial attacks, data leakage, and model manipulation, before they become enterprise risks.
Technology
Enable Safe and Scalable AI Adoption.
Application Developers
Build AI applications securely without compromising speed or flexibility.
"As enterprises embrace AI, security can’t be an afterthought. HiddenLayer makes it possible for CISOs to lead with confidence and keep innovation secure."
Tomas Maldonado
CISO, NFL
"Securing AI requires protection across the entire lifecycle. HiddenLayer delivers end-to-end visibility and defense so CISOs can safeguard AI at every stage."
Jerry Davis
Founder, Gryphon X
"Strong governance is critical as AI becomes embedded across enterprises. HiddenLayer provides the comprehensive framework needed to manage risk and align AI adoption with visibility, compliance, and accountability."
Gary McAlum
Prior CISO, AIG
"The integrity of AI systems is as critical as the integrity of our software supply chains. If we can't secure the building blocks of AI, we risk exposing enterprises to new classes of attack. HiddenLayer is tackling this problem at its root, delivering the protections the world needs most."
Thomas Pace
Co-Founder & CEO, NetRise
"AI introduces risks that traditional cybersecurity tools weren't built to handle. HiddenLayer's comprehensive platform consolidates what CISOs need to manage and defend the critical AI tools that enable the business."
Timothy Youngblood
CISO in Residence, Astrix Security
"One of the elements that impresses me about HiddenLayer is the elegance of their technology. Their non-invasive AIDR solution provides robust, real-time protection against adversarial attacks without ever needing to access a customer's sensitive data or proprietary models. This is a game-changer for enterprises in regulated industries like finance and healthcare, as well as federal agencies, where data privacy is paramount."
Doug Merritt Chairman
CEO & President at Aviatrix and prior CEO at Splunk
"AI security demands purpose-built technology and trusted partners to counter AI attack vectors. HiddenLayer arms CISOs with a comprehensive platform to identify and manage AI-specific risks, enabling organizations to innovate with confidence and at the speed of modern business."
Josh Lemos
CISO, GitLab
Trusted. Awarded. Recognized.
Validated by Gartner, RSAC, and leading industry analysts for innovation and leadership in AI security.
Innovation Hub
Research, guidance, and frameworks from the team shaping AI security standards.
insights
XX
min read
NSPM-11 Elevates AI Security from Best Practice to National Security Requirement
NSPM-11 elevates AI security to a national security requirement. Learn how AI assurance, model security, and threat detection support trusted AI adoption
On June 5, 2026, the White House released National Security Presidential Memorandum-11 (NSPM-11), establishing a framework for accelerating AI adoption across the national security enterprise. One detail stands out from a security perspective: Section 4(c) explicitly directs leaders to secure advanced AI systems, including protection against malicious distillation attacks.
Presidential directives rarely reference specific attack techniques. By naming model distillation directly, NSPM-11 acknowledges a reality security teams have been confronting for years: AI systems are now strategic assets and attack targets. Protecting those systems from theft, manipulation, and misuse is a national security requirement.
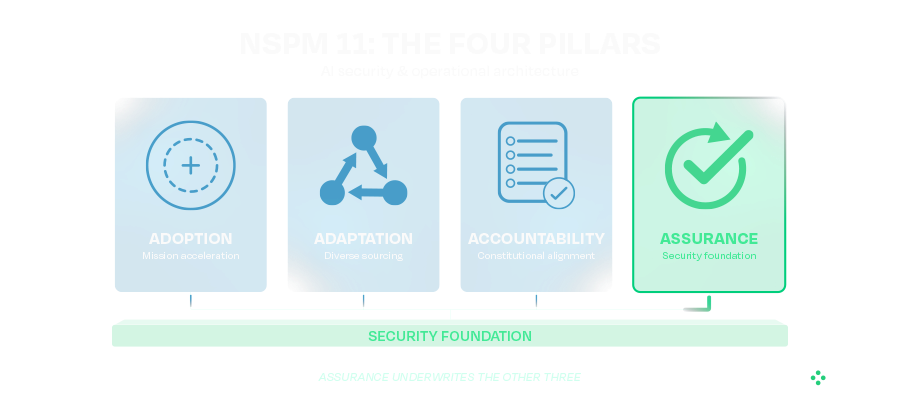
The memorandum organizes the national security enterprise around four pillars: Adoption, Adaptation, Assurance, and Accountability. While much of the discussion around NSPM-11 has focused on accelerating AI deployment, the Assurance pillar deserves equal attention. It is the foundation that enables organizations to adopt AI confidently and securely.
Understanding the Three AI Challenges
Discussions about AI security often blur together three distinct disciplines:
AI for Cybersecurity: Using AI to improve security operations, threat detection, vulnerability management, and defensive capabilities.
Responsible AI: Ensuring AI systems operate safely, ethically, and in compliance with applicable laws, policies, and governance requirements.
AI Security: Protecting AI systems themselves from theft, manipulation, compromise, and adversarial attacks.
While these disciplines are complementary, they address different risks and require different controls.
Responsible AI programs help organizations manage governance and compliance risks, but they are not designed to identify model backdoors or model theft. AI-powered cybersecurity tools may improve detection and response capabilities, but they do not inherently protect the models themselves from attack.
AI security focuses on a different question entirely: Can an adversary manipulate, steal, poison, or otherwise compromise the model?
That distinction is central to NSPM-11's Assurance pillar and highlights why AI security has emerged as its own cybersecurity discipline.
The Significance of NSPM-11's Definitions
One of the most important aspects of NSPM-11 is how it defines AI security. The memorandum defines AI security as applying protection mechanisms across the AI technology stack to ensure the confidentiality, integrity, and availability of AI systems from design through deployment.
This aligns AI security with established cybersecurity principles while recognizing that AI introduces unique attack surfaces. The policy also broadens the concept of AI incident response to include adversarial attacks against AI systems themselves, reinforcing the need to monitor, defend, and validate AI models like any other critical technology asset.
This shift is significant because it formally recognizes AI systems as operational assets that require dedicated security controls. Threats such as prompt injection, model extraction, training data poisoning, and model backdoors are no longer theoretical concerns. They are security risks that organizations must be prepared to detect, investigate, and respond to.
Assurance Requires Independent Verification
The Assurance pillar emphasizes maintaining visibility and control over mission-critical AI systems.
NSPM-11 requires mechanisms that prevent AI systems from being materially modified without government knowledge and approval. This reflects two realities facing organizations adopting AI at scale.
First, AI systems can be intentionally manipulated. Adversaries may attempt to alter a model's behavior through tampering, poisoning, or the introduction of hidden functionality.
Second, organizations must maintain independent visibility into the AI systems they rely on. As agencies deploy models from commercial providers, open-source communities, and internal development teams, they need the ability to verify model integrity regardless of where the model originated.
This requirement naturally favors security capabilities that operate independently of any single model vendor. As the AI ecosystem becomes increasingly diverse, organizations need assurance mechanisms that can evaluate and secure AI systems consistently across different model architectures, deployment environments, and suppliers.
Equally important, those assurance mechanisms should align with established frameworks such as MITRE ATLAS, the NIST AI Risk Management Framework (AI RMF), and emerging federal AI security guidance. Aligning AI security programs with recognized frameworks enables organizations to consistently evaluate risk, validate security controls, and demonstrate assurance through transparent, repeatable methodologies.
What AI Security Looks Like in Practice
The threats addressed by NSPM-11 are not hypothetical.
HiddenLayer researchers demonstrated this challenge through ShadowLogic, a technique that embeds malicious behavior directly within a model's computational graph rather than in traditional software components.
Because these manipulations exist within the model itself, they can evade conventional malware detection approaches and persist through common model transformations. Research has demonstrated that these types of backdoors can remain dormant until triggered by specific conditions, highlighting a key challenge for AI security: many AI threats lie beyond the visibility of traditional security controls, making specialized model analysis and validation essential before deployment.
However, securing AI systems extends beyond model artifacts alone.
At deployment and runtime, organizations must contend with attacks such as prompt injection, jailbreaks, sensitive data extraction, and other adversarial techniques that target model behavior through inference interactions. Many of these risks are now well documented within industry frameworks, including the OWASP Top 10 for LLM Applications and MITRE ATLAS. These resources provide a common language for understanding AI attack techniques and reinforce the need for security controls that continuously monitor model interactions and behavior in production environments.
At the strategic level, NSPM-11 specifically calls out model distillation attacks, in which an adversary repeatedly queries a deployed model to replicate its capabilities in another system. In these cases, the attacker may never gain direct access to model weights or infrastructure. Instead, they extract value through interaction.
These threats occur at different stages of the AI lifecycle, which is why effective AI security requires a layered approach. Model integrity validation, runtime monitoring, adversarial testing, and continuous assessment each address different aspects of the attack surface.
The principle is familiar to every security practitioner: defense in depth applies to AI just as it does to traditional systems.
Why AI Security Is a Distinct Discipline
NSPM-11 reinforces why AI security has emerged as a dedicated cybersecurity discipline.
Traditional security controls remain essential, but they were not designed to identify model backdoors, detect attempts to extract models, or analyze machine learning artifacts for signs of tampering.
Addressing these risks requires capabilities focused specifically on AI systems, including:
Model scanning and artifact analysis
Runtime monitoring for AI-specific attacks
Adversarial testing and AI red teaming
Continuous validation of model integrity
AI-focused incident response and investigation
These capabilities should operate independently of any single model provider, enabling organizations to evaluate and secure AI systems consistently across a diverse technology ecosystem.
This challenge becomes even more important within national security environments. A model can be protected by strong network controls and still be compromised before deployment if the model artifact itself contains malicious modifications. Security must therefore extend beyond infrastructure and include the AI system itself.
Additionally, many mission-critical AI deployments operate in disconnected, classified, or air-gapped environments. Security controls that require continuous communication with vendor-hosted cloud services may not be practical in these settings. Effective AI security must be able to operate within the organization's environment and security boundaries.
The Bottom Line
NSPM-11 reinforces a principle that security teams already understand: trust requires verification.
As agencies accelerate AI adoption, security leaders must evaluate not only model performance but also their ability to verify model integrity, understand model behavior under adversarial conditions, and deploy security controls that operate within mission environments.
Before deploying a model, organizations should be able to answer three fundamental questions:
Can we verify the integrity of this model?
Can we understand how it behaves under attack?
Can security controls operate within our environment, including disconnected or classified networks?
NSPM-11 makes clear that AI assurance is no longer optional. As AI becomes foundational to mission execution, securing the model itself must become a foundational part of the security strategy.
The organizations that can answer these questions with confidence will be best positioned to adopt AI at scale while maintaining trust, resilience, and operational readiness.
report and guide
XX
min read
2026 AI Threat Landscape Report
The threat landscape has shifted.
In this year's HiddenLayer 2026 AI Threat Landscape Report, our findings point to a decisive inflection point: AI systems are no longer just generating outputs, they are taking action.
Agentic AI has moved from experimentation to enterprise reality. Systems are now browsing, executing code, calling tools, and initiating workflows on behalf of users. That autonomy is transforming productivity, and fundamentally reshaping risk.In this year’s report, we examine:
The rise of autonomous, agent-driven systems
The surge in shadow AI across enterprises
Growing breaches originating from open models and agent-enabled environments
Why traditional security controls are struggling to keep pace
Our research reveals that attacks on AI systems are steady or rising across most organizations, shadow AI is now a structural concern, and breaches increasingly stem from open model ecosystems and autonomous systems.
The 2026 AI Threat Landscape Report breaks down what this shift means and what security leaders must do next.
We’ll be releasing the full report March 18th, followed by a live webinar April 8th where our experts will walk through the findings and answer your questions.
webinar
XX
min read
HiddenLayer Webinar: 2024 AI Threat Landscape Report
reading time
AI Threat Landscape Report
We all know AI is evolving quickly, from chatbots to autonomous, agentic systems capable of making decisions, executing tasks, and interacting with other systems. But did you know the attack surface grows just as fast?
Our latest report examines how the threat landscape is shifting and what security leaders need to understand as AI becomes foundational to enterprise operations.
Ready to secure your AI?
Start by requesting your demo and let’s discuss protecting your unique AI advantage.
















.webp)
.webp)
.webp)