Supply Chain Threats: Critical Look at Your ML Ops Pipeline
January 17, 2023





In a Nutshell:
- A supply chain attack can be incredibly damaging, far-reaching, and an all-round terrifying prospect.
- Supply chain attacks on ML systems can be a little bit different from the ones you’re used to.;
- ML is often privy to sensitive data that you don’t want in the wrong hands and can lead to big ramifications if stolen.
- We pose some pertinent questions to help you evaluate your risk factors and more accurately perform threat modeling.
- We demonstrate how easily a damaging attack can take place, showing the theft of training data stored in an S3 bucket through a compromised model.
For many security practitioners, hearing the term ‘supply chain attack’ may still bring on a pang of discomfort and unease - and for good reason. Determining the scope of the attack, who has been affected, or discovering that your organization has been compromised is no easy thought and makes for an even worse reality. A supply-chain attack can be far-reaching and demolishes the trust you place in those you both source from and rely on. But, if there’s any good that comes from such a potentially catastrophic event, it’s that they serve as a stark reminder of why we do cybersecurity in the first place.
To protect against supply chain attacks, you need to be proactive. By the time an attack is disclosed, it may already be too late - so prevention is key. So too, is understanding the scope of your potential exposure through supply chain risk management. Hopefully, this sounds all too familiar, if not, we’ll lightly cover this later on.
The aim of this blog is to highlight the similarly affected technologies involved within the Machine Learning supply chain and the varying levels of risk involved. While it bears some resemblance to the software supply chain you’re likely used to, there are a few key differences that set them apart. By understanding this nuance, you can begin to introduce preventative measures to help ensure that both your company and its reputation are left intact.
The Impact
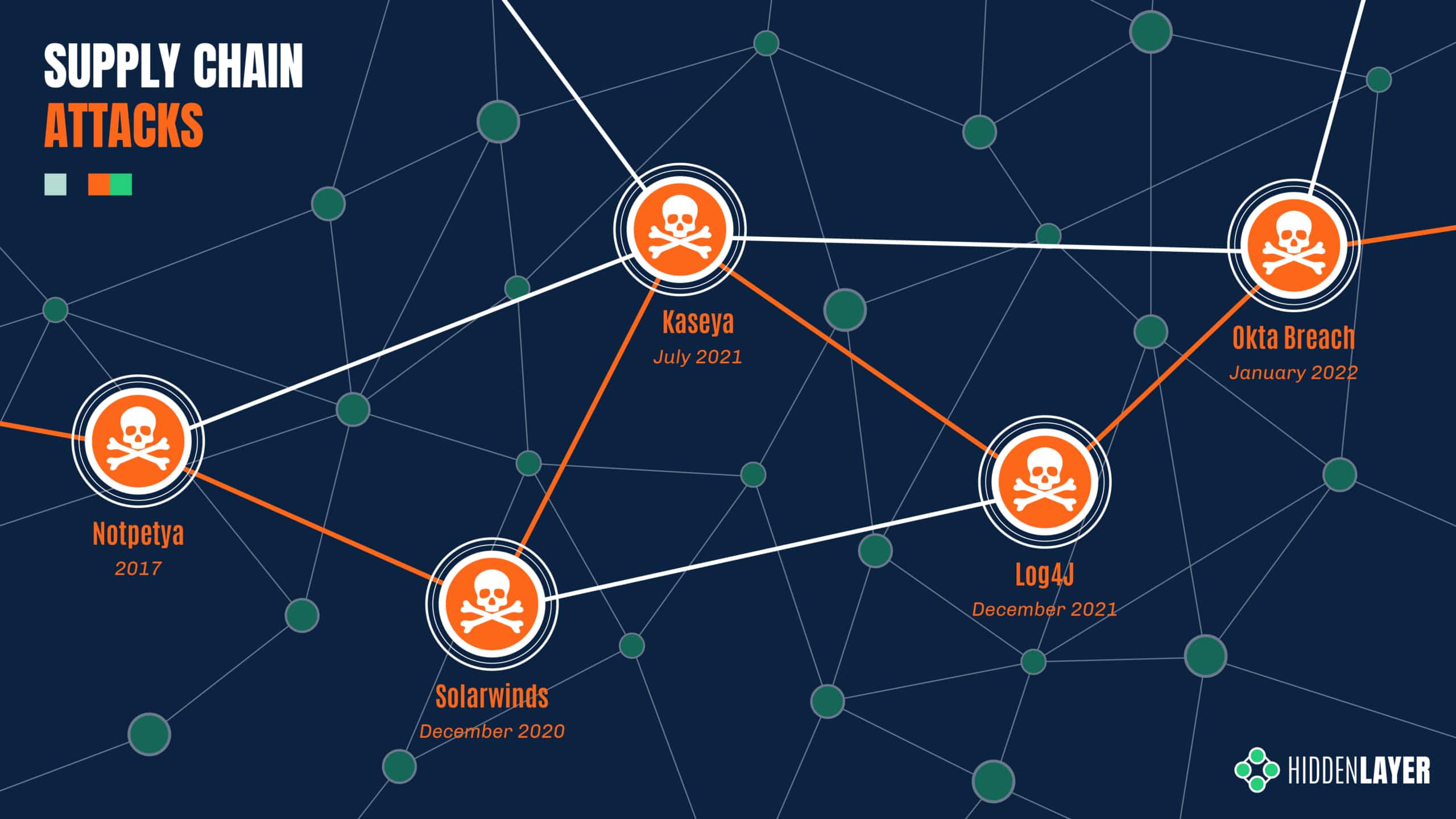
Over the last few years, supply chain attacks have been carved into the collective memory of the security community through major attacks such as SolarWinds and Kaseya - amongst others. With the SolarWinds breach, it is estimated that close to a hundred customers were affected through their compromised Orion IT management software, spanning public and private sector organizations alike. Later, the Kaseya incident reportedly affected over a thousand entities through their VSA management software - ultimately resulting in ransomware deployment.
The magnitude of the attacks kicked the industry into overdrive - examining supply-side exposure, increasing scrutiny on 3rd party software, and implementing more holistic security controls. But it’s a hard problem to solve, the components of your supply chain are not always apparent, especially when it’s constantly evolving.
The Root Cause
So what makes these attacks so successful - and dangerous? Well, there are two key factors that the adversary exploits:
- Trust - Your software provider isn’t an APT group, right? The attacker abuses the existing trust between the producer and consumer. Given the supplier’s prevalence and reputation, their products often garner less scrutiny and can receive more lax security controls.
- Reach - One target, many victims. The one-to-many business model means that an adversary can affect the downstream customers of the victim organization in one fell swoop.
The ML Supply Chain
ML is an incredibly exciting space to be in right now, with huge advances gracing the collective newsfeed almost every week. Models such as DALL-E and Stable Diffusion are redefining the creative sphere, while AlphaTensor beats 50-year-old math records, and ChatGPT is making us question what it means to be human. Not to mention all the datasets, frameworks, and tools that enable and support this rapid progress. What’s more, outside of the computing cost, access to ML research is largely free and readily available for you to download and implement in your own environment.;
But, like one uncle to a masked hero said - with great sharing, comes great need for security - or something like that. Using lessons we’ve learned from dealing with past incidents, we looked at the ML Supply Chain to understand where people are most at risk and provided some questions to ask yourself to help evaluate your risk factors:
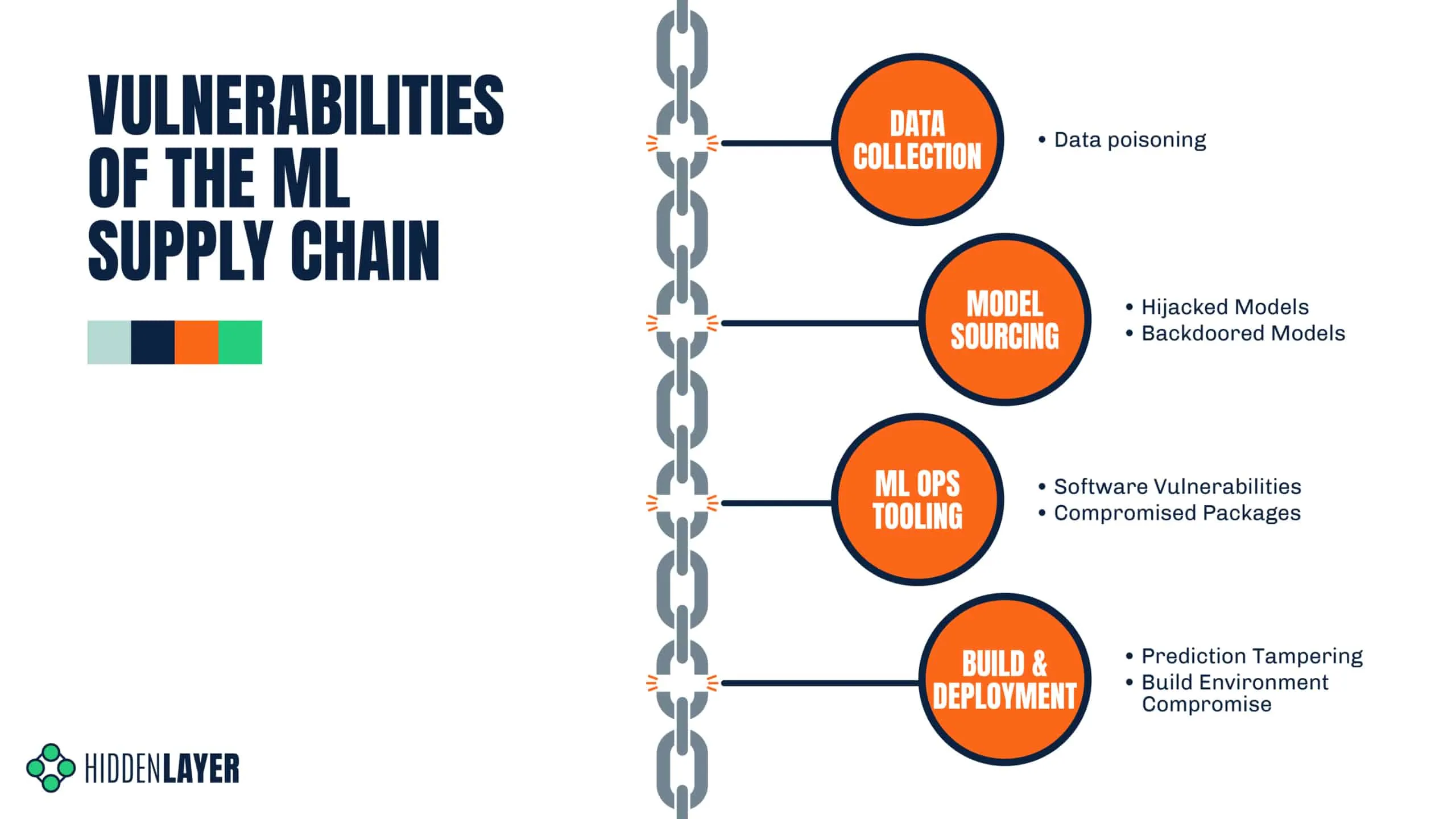
Data Collection
A model is only as good as the dataset that it’s trained on, and it can often prove difficult to gather appropriate real-world data in-house. In many cases, you will have to source your dataset externally - either from a data-sharing repository or from a specific data provider. While often necessary, this can open you up to the world of data poisoning attacks, which may not be realized until late into the MLOps lifecycle. The end result of data poisoning is the production of an inaccurate, flawed, or subverted model, which can have a host of negative consequences.
- Is the data coming from a trusted source? e.g., You wouldn’t want to train your medical models on images scraped from a subreddit!
- Can the integrity of the data be assured?
- Can the data source be easily compromised or manipulated? See Microsoft's 'Tay'.
Model Sourcing
One of the most expensive parts of any ML pipeline is the cost of training your model - but it doesn’t always have to be this way. Depending on your use case, building advanced complex models can prove to be unnecessary, thanks to both the accessibility and quality of pre-trained models. It’s no surprise that pre-trained models have quickly become the status quo in ML - as this compact result of vast, expensive computation can be shared on model repositories such as HuggingFace, without having to provide the training data - or processing power.
However, such models can contain malicious code, which is especially pertinent when we consider the resources ML environments often have access to, such as other models, training data (which may contain PII), or even S3 buckets themselves.
- Is it possible that the model has been hijacked, tampered or compromised in some other manner?;
- Is the model free of backdoors that could allow the attacker to routinely bypass it by giving it specific input?
- Can the integrity of the model be verified?
- Is the environment the model is to be executed in as restricted as possible? E.g., ACLs, VPCs, RBAC, etc
ML Ops Tooling
Unless you’re painstakingly creating your own ML framework, chances are you depend on third-party software to build, manage and deploy your models. Libraries such as TensorFlow, PyTorch, and NumPy are mainstays of the field, providing incredible utility and ease to data scientists around the world. But these libraries often depend on additional packages, which in turn have their own dependencies, and so on. If one such dependency was compromised or a related package was replaced with a malicious one, you could be in big trouble.
A recent example of this is the ‘torchtriton’ package which, due to dependency confusion with PyPi, affected PyTorch-nightly builds for Linux between the 25th and 30th of December 2022. Anyone who downloaded the PyTorch nightly in this time frame inadvertently downloaded the malicious package, where the attacker was able to hoover up secrets from the affected endpoint. Although the attacker claims to be a researcher, the theft of ssh keys, passwd files, and bash history suggests otherwise.
If that wasn’t bad enough, widely used packages such as Jupyter notebook can leave you wide open for a ransomware attack if improperly configured. It’s not just Python packages, though. Any third-party software you employ puts you at risk of a supply chain attack unless it has been properly vetted. Proper supply chain risk management is a must!
- What packages are being used on the endpoint?
- Is any of the software out-of-date or contain known vulnerabilities?
- Have you verified the integrity of your packages to the best of your ability?
- Have you used any tools to identify malicious packages? E.g., DataDog’s GuardDog
Build & Deployment
While it could be covered under ML Ops tooling, we wanted to draw specific attention to the build process for ML. As we saw with the SolarWinds attack, if you control the build process, you control everything that gets sent downstream. If you don’t secure your build process sufficiently, you may be the root cause of a supply chain attack as opposed to the victim.
- Are you logging what’s taking place in your build environment?
- Do you have mitigation strategies in place to help prevent an attack?
- Do you know what packages are running in your build environment?
- Are you purging your build environment after each build?
- Is access to your datasets restricted?
As for deployment - your model will more than likely be hosted on a production system and exposed to end users through a REST API, allowing these stakeholders to query it with their relevant data and retrieve a prediction or classification. More often than not, these results are business-critical, requiring a high degree of accuracy. If a truly insidious adversary wanted to cause long-term damage, they might attempt to degrade the model’s performance or affect the results of the downstream consumer. In this situation, the onus is on the deployer to ensure that their model has not been compromised or its results tampered with.
- Is the integrity of the model being routinely verified post-deployment?
- Do the model’s outputs match those of the pre-deployment tests?
- Has drift affected the model over time, where it’s now providing incorrect results?
- Is the software on the deployment server up to date?
- Are you making the best use of your cloud platform's security controls?
A Worst Case Scenario - SageMaker Supply Chain Attack
A picture paints a thousand words, and as we’re getting a little high on word count, we decided to go for a video demonstration instead. To illustrate the potential consequences of an ML-specific supply chain attack, we use a cloud-based ML development platform - Amazon Sagemaker and a hijacked model - however it could just as well be a malicious package or an ML-adjacent application with a security vulnerability. This demo shows just how easy it is to steal training data from improperly configured S3 buckets, which could be your customers’ PII, business-sensitive information, or something else entirely.
https://youtu.be/0R5hgn3joy0
Mitigating Risk
It Pays to Be Proactive
By now, we’ve heard a lot of stomach-churning stuff, but what can we do about it? In April of 2021, the US Cybersecurity and Infrastructure Security Agency (CISA) released a 16-page security advisory to advise organizations on how to defend themselves through a series of proactive measures to help prevent a supply chain attack from occurring. More specifically, they talk about using frameworks such as Cyber Supply Chain Risk Management (C-SCRM) and Secure Software Development Framework (SSDF). We wish that ML was free of the usual supply chain risks, many of these points still hold true - with some new things to consider too.
Integrity & Verification
Verify what you can, and ensure the integrity of the data you produce and consume. In other words, ensure that the files you get are what you hoped you’d get. If not, you may be in for a nasty surprise. There are many ways to do this, from cryptographic hashing to certificates to a deeper dive manual inspection.
Keep Your (Attack) Surfaces Clean
If you’re a fan of cooking, you’ll know that the cooking is the fun part, and the cleanup - not so much. But that cleanup means you can cook that dish you love tomorrow night without the chance of falling ill. By the same virtue, when you’re building ML systems, make sure you clean up any leftover access tokens, build environments, development endpoints, and data stores. If you clean as you go, you’re mitigating risk and ensuring that the next project goes off without a hitch. Not to mention - a spring clean in your cloud environment may save your organization more than a few dollars at the end of the month.
Model Scanning
In past blogs, we’ve shown just how dangerous a model can be and highlighted how attackers are actively using model formats such as Pickle as a launchpad for post-exploitation frameworks. As such, it’s always a good idea to inspect your models thoroughly for signs of malicious code or illicit tampering. We released Yara rules to aid in the detection of particular varieties of hijacked models and also provide a model scanning service to provide an added layer of confidence.
Cloud Security
Make use of what you’ve got, many cloud service providers provide some level of security mechanisms, such as Access Control Lists (ACLs), Virtual Private Cloud (VPCs), Role Based Access Control (RBAC), and more. In some cases, you can even disconnect your models from the internet during training to help mitigate some of the risks - though this won’t stop an attacker from waiting until you’re back online again.
In Conclusion
While being in a state of hypervigilance can be tiring, looking critically at your ML Ops pipeline every now and again is no harm, in fact, quite the opposite. Supply-chain attacks are on the rise, and the rules of engagement we’ve learned through dealing with them very much apply to Machine Learning. The relative modernity of the space, coupled with vast stores of sensitive information and accelerating data privacy regulation means that attacks on ML supply chains have the potential to be explosively damaging in a multitude of ways.
That said, the questions we pose in this blog can help with threat modeling for such an event, mitigate risk and help to improve your overall security posture.
Related Research

Exploring the Security Risks of AI Assistants like OpenClaw
OpenClaw (formerly Moltbot and ClawdBot) is a viral, open-source autonomous AI assistant designed to execute complex digital tasks, such as managing calendars, automating web browsing, and running system commands, directly from a user's local hardware. Released in late 2025 by developer Peter Steinberger, it rapidly gained over 100,000 GitHub stars, becoming one of the fastest-growing open-source projects in history. While it offers powerful "24/7 personal assistant" capabilities through integrations with platforms like WhatsApp and Telegram, it has faced significant scrutiny for security vulnerabilities, including exposed user dashboards and a susceptibility to prompt injection attacks that can lead to arbitrary code execution, credential theft and data exfiltration, account hijacking, persistent backdoors via local memory, and system sabotage.

Agentic ShadowLogic
Agentic ShadowLogic is a sophisticated graph-level backdoor that hijacks an AI model's tool-calling mechanism to perform silent man-in-the-middle attacks, allowing attackers to intercept, log, and manipulate sensitive API requests and data transfers while maintaining a perfectly normal conversational appearance for the user.


Stay Ahead of AI Security Risks
Get research-driven insights, emerging threat analysis, and practical guidance on securing AI systems—delivered to your inbox.