Safeguarding AI with AI Detection and Response
October 25, 2022





In previous articles, we’ve discussed the ubiquity of AI-based systems and the risks they’re facing; we’ve also described the common types of attacks against machine learning (ML) and built a list of adversarial ML tools and frameworks that are publicly available. Today, the time has come to talk about countermeasures.
Over the past year, we’ve been working on something that fundamentally changes how we approach the security of ML and AI systems. Typically undertaken is a robustness-first approach which adds complexity to models, often at the expense of performance, efficacy, and training cost. To us, it felt like kicking the can down the road and not addressing the core problem - that ML is under attack.
Once upon a time…
Back in 2019, the future founders of HiddenLayer worked closely together at a next-generation antivirus company. Machine learning was at the core of their flagship endpoint product, which was making waves and disrupting the AV industry. As fate would have it, the company suffered an attack where an adversary had created a universal bypass against the endpoint malware classification model. This meant that the attacker could alter a piece of malware in such a way that it would make anything from a credential stealer to ransomware appear benign and authoritatively safe.
The ramifications of this were serious, and our team scrambled to assess the impact and provide remediation. In dealing with the attack, we realized that this problem was indeed much bigger than the AV industry itself and bigger still than cybersecurity - attacks like these were going to affect almost every vertical. Having had to assess, remediate and defend against future attacks, we realized we were uniquely suited to help address this growing problem.
In a few years’ time, we went on to form HiddenLayer, and with that - our flagship product, Machine Learning Detection and Response, or MLDR.
What is MLDR?
Figure 1: An artist’s impression of MLDR in action - a still from the HiddenLayer promotional video
Platforms such as Endpoint Detection and Response (EDR), Extended Detection and Response (XDR), or Managed Detection and Response (MDR) have been widely used to detect and prevent attacks on endpoint devices, servers, and cloud-based resources. In a similar spirit, Machine Learning Detection and Response aims to identify and prevent attacks against machine learning systems. While EDR monitors system and network telemetry on the endpoint, MLDR monitors the inputs and outputs of machine learning models, i.e., the requests that are sent to the model, together with the corresponding model predictions. By analyzing the traffic for any malicious, suspicious, or simply anomalous activity, MLDR can detect an attack at a very early stage and offers ways to respond to it.
Why MLDR & Why Now?
As things stand today, machine learning systems are largely unprotected. We deploy models with the hope that no one will spend the time to find ways to bypass the model, coerce it into adverse behavior or steal it entirely. With more and more adversarial open-source tooling entering the public domain, attacking ML has become easier than ever. If you use ML within your company, perhaps it is a good time to ask yourself a tough question: could you even tell if you were under attack?
The current status quo in ML security is model robustness, where models are made more complex to resist simpler attacks and deter attackers. But this approach has a number of significant drawbacks, such as reduced efficacy, slower performance, and increased retraining costs. Throughout the sector, it is known that security through obscurity is a losing battle, but how about security through visibility instead?
Being able to detect suspicious and anomalous behaviors amongst regular requests to the ML model is extremely important for the model’s security, as most attacks against ML systems start with such anomalous traffic. Once an attack is detected and stakeholders alerted, actions can be taken to block it or prevent it from happening in the future.
With MLDR, we not only enable you to detect attacks on your ML system early on, but we also help you to respond to such attacks, making life even more difficult for adversaries - or cutting them off entirely!
Our Solution
Broadly speaking, our MLDR product comprises two parts: the locally installed client and the cloud-based sensor the client communicates with through an API. The client is installed in the customer’s environment and can be easily implemented around any ML model to start protecting it straight away. It is responsible for sending input vectors from all model queries, together with the corresponding predictions, to the HiddenLayer API. This data is then processed and analyzed for malicious or suspicious activity. If any signs of such activity are detected, alerts are sent back to the customer in a chosen way, be it via Splunk, DataDog, the HiddenLayer UI, or simply a customer-side command-line script.
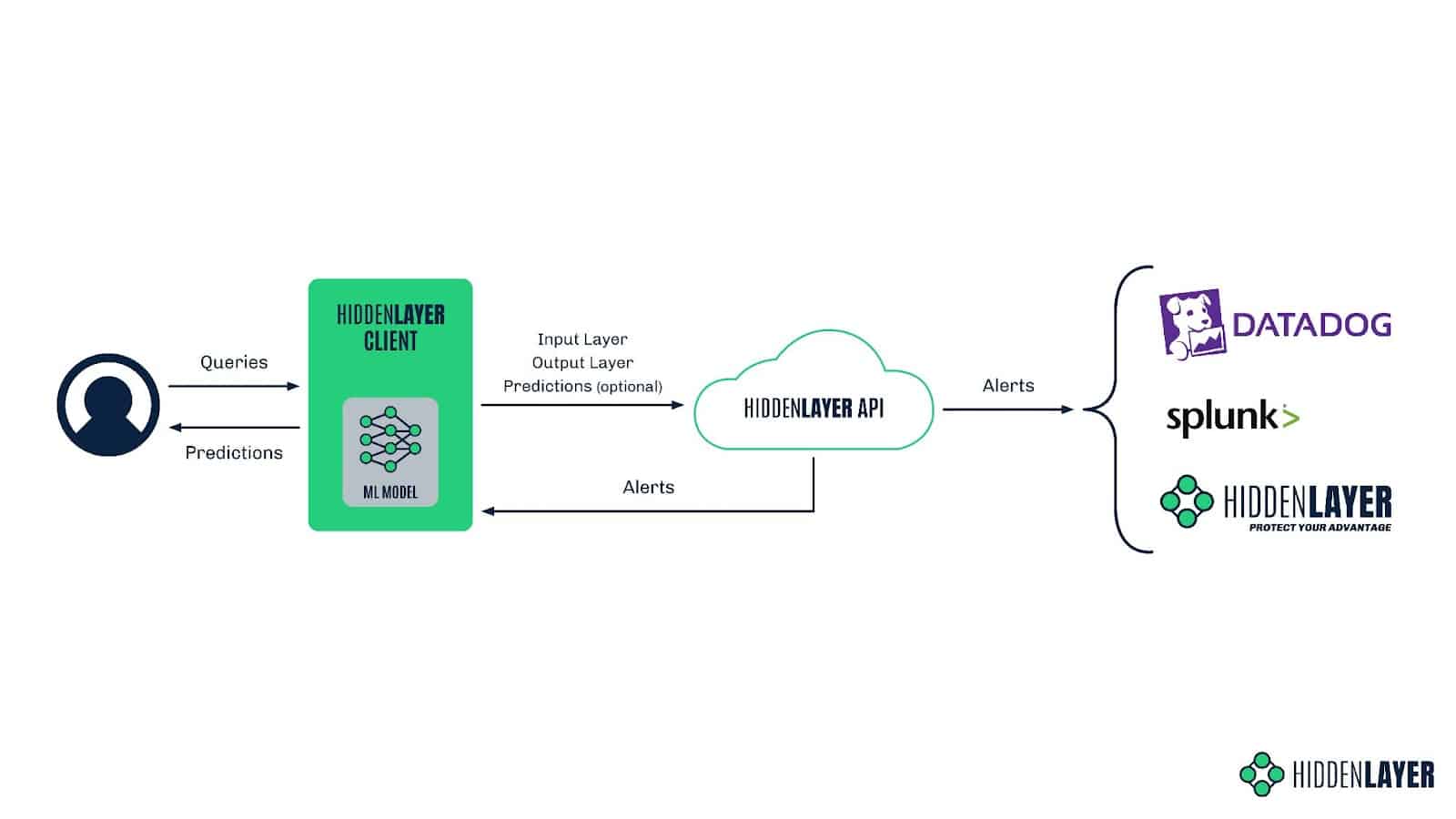
Figure 2: HiddenLayer MLDR architecture
If you’re concerned about exposing your sensitive data to us, don’t worry - we’ve got you covered. Our MLDR solution is post-vectorization, meaning we don’t see any of your sensitive data, nor can we reconstruct it. In simple terms, ML models convert all types of input data - be it an image, audio, text, or tabular data - into numerical ‘vectors’ before it can be ingested. We step in after this process, meaning we can only see a series of floating-point numbers and don’t have access to the input in its original form at any point. In this way, we respect the privacy of your data and - by extension - the privacy of your users.
The Client
When a request is sent to the model, the HiddenLayer client forwards anonymized feature vectors to the HiddenLayer API, where our detection magic takes place. The cloud-based approach helps us to be both lightweight on the device and keep our detection methods obfuscated from adversaries who might try to subvert our defenses.
The client can be installed using a single command and seamlessly integrated into your MLOps pipeline in just a few minutes. When we say seamless, we mean it: in as little as three lines of code, you can start sending vectors to our API and benefitting from the platform.
To make deployment easy, we offer language-specific SDKs, integrations into existing MLOps platforms, and integrations into ML cloud solutions.
Detecting an Attack
While our detections are proprietary, we can reveal that we use a combination of advanced heuristics and machine-learning techniques to identify anomalous actions, malicious activity, and troubling behavior. Some adversaries are already leveraging ML algorithms to attack machine learning, but they’re not the only ones who can fight fire with fire!
Alerting
To be useful, a detection requires its trusty companion - the alert. MLDR offers multiple ways to consume alerts, be it from our REST API, the HiddenLayer dashboard, or SIEM integration for existing workflows. We provide a number of contextual data points which enable you to understand the when, where, and what happened during an attack on your models. Below is an example of the JSON-formatted information provided in an alert on an ongoing inference attack:
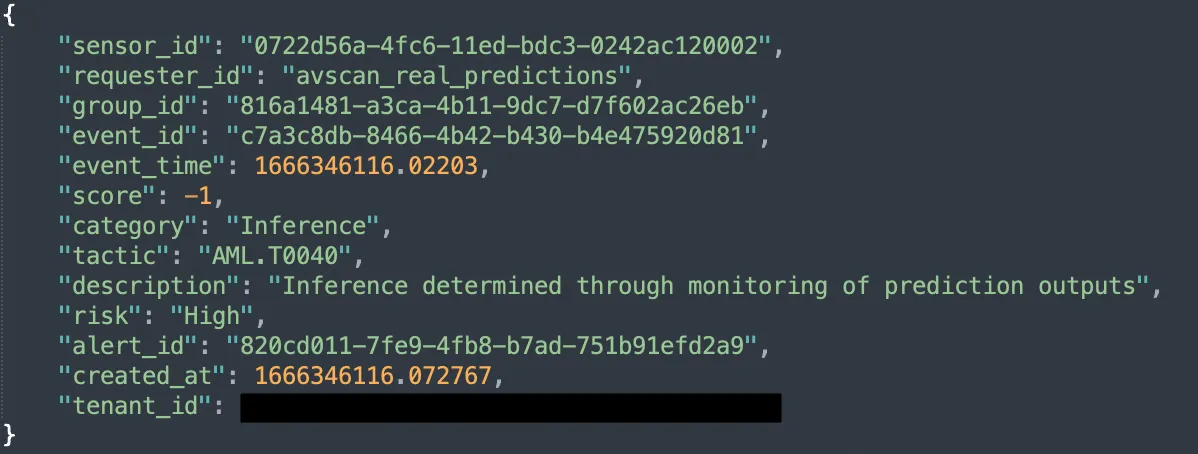
Figure 3: An example of a JSON-formatted alert from HiddenLayer MLDR
We align with MITRE ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems), ensuring we have a working standard for adversarial machine learning attacks industry-wide. Complementary to the well-established MITRE ATT&CK framework, which provides guidelines for classifying traditional cyberattacks, ATLAS was introduced in 2021 and covers tactics, techniques, and case studies of attacks against machine learning systems. An alert from HiddenLayer MLDR specifies the category, description, and ATLAS tactic ID to help correlate known attack techniques with the ATLAS database.
SIEM Integration
Security Information and Event Management technology (SIEM) is undoubtedly an essential part of a workflow for any modern security team - which is why we chose to integrate with Splunk and DataDog from the get-go. Our intent is to bring humans into the loop, allowing the SOC analysts to triage alerts, which they can then escalate to the data science team for detailed investigation and remediation.

Figure 4: An example of an MLDR alert in Splunk
Responding to an Attack
If you fall victim to an attack on your machine learning system and your model gets compromised, retraining the model might be the only viable course of action. There are no two ways about it - model retraining is expensive, both in terms of time and effort, as well as money/resources - especially if you are not aware of an attack for weeks or months! With the rise of automated adversarial ML frameworks, attacks against ML are set to become much more popular - if not mainstream - in the very near future. Retraining the model after each incident is not a sustainable solution if the attacks occur on a regular basis - not to mention that it doesn’t solve the problem at all.
Fortunately, if you are able to detect an attack early enough, you can also possibly stop it before it does significant damage. By restricting user access to the model, redirecting their traffic entirely, or feeding them with fake data, you can thwart the attacker’s attempts to poison your dataset, create adversarial examples, extract sensitive information, or steal your model altogether.
At HiddenLayer, we’re keeping ourselves busy working on novel methods of defense that will allow you to counter attacks on your ML system and give you other ways to respond than just model retraining. With HiddenLayer MLDR, you will be able to:
- Rate limit or block access to a particular model or requestor.
- Alter the score classification to prevent gradient/decision boundary discovery.
- Redirect traffic to profile ongoing attacks.
- Bring a human into the loop to allow for manual triage and response.
Attack Scenarios
To showcase the vulnerability of machine learning systems and the ease with which they can be attacked, we tested a few different attack scenarios. We chose four well-known adversarial ML techniques and used readily available open-source tooling to perform these attacks. We were able to create adversarial examples that bypass malware detection and fraud checks, fool an image classifier, and create a model replica. In each case, we considered possible detection techniques for our MLDR.
MalwareRL - Attacking Malware Classifier Models
Considering our team’s history in the anti-virus industry, attacks on malware classifiers are of special significance to us. This is why frameworks such as MalwareGym and its successor MalwareRL immediately caught our attention. MalwareRL uses an inference-based attack, coupled with a technique called reinforcement learning, to perturb malicious samples with ‘good’ features, i.e., features that would make the sample look like a piece of clean software to the machine learning model used in an anti-malware solution.
The framework takes a malicious executable and slightly modifies it without altering its functionality (e.g., by adding certain strings or sections, changing specific values in the PE header, etc.) before submitting it to the model for scoring. The new score is recorded, and if it still falls into the “malicious” category, the process is repeated with different combinations of features until the scoring changes enough to flip the classification to benign. The resulting sample remains a fully working executable with the same functionality as the original one; however, it now evades detection.
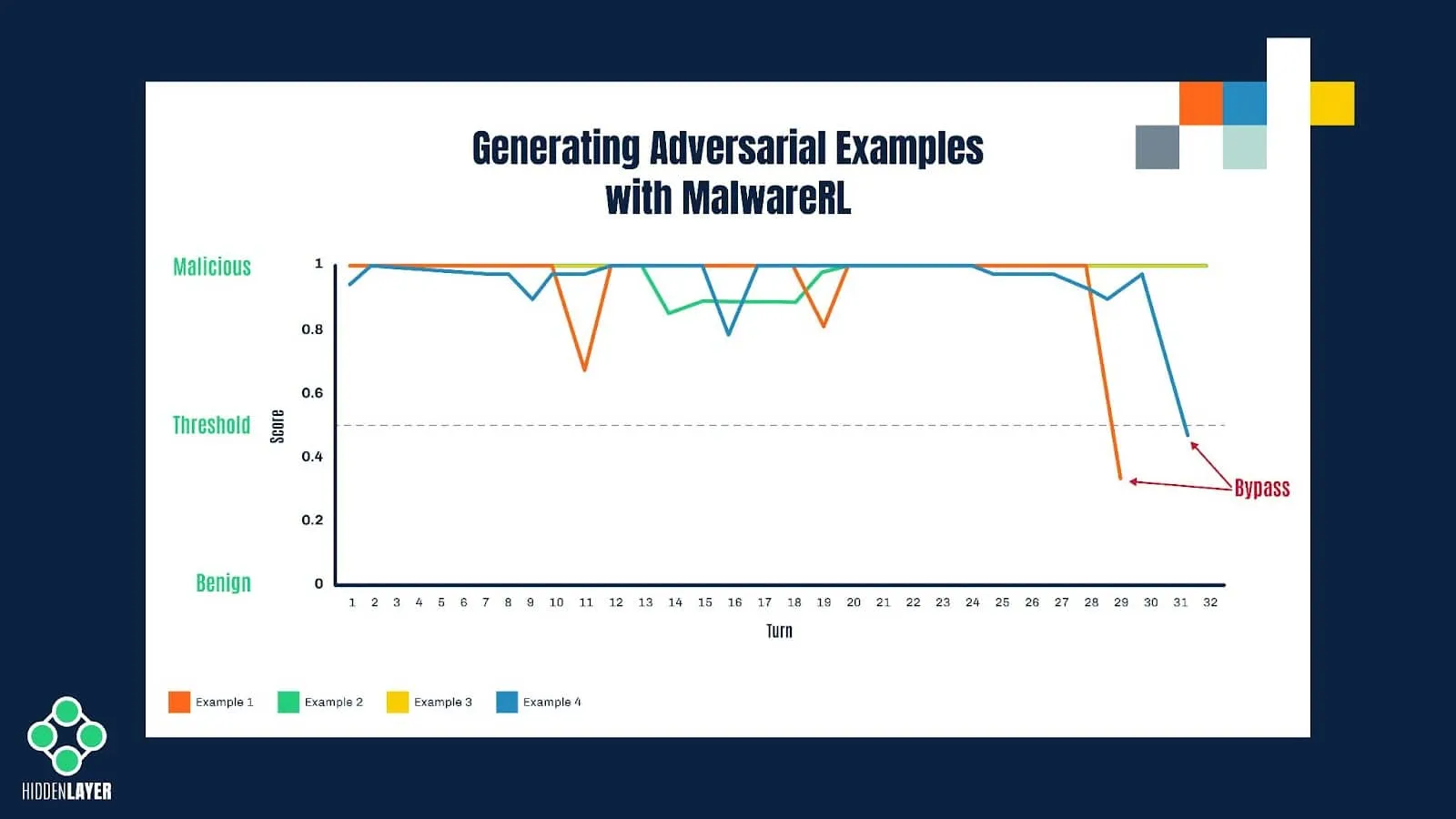
Figure 5: Illustration of the process of creating adversarial examples with MalwareRL
Although it could be achieved by crude brute-forcing with randomly selected features, the reinforcement learning technique used in MalwareRL helps to significantly speed up and optimize this process of creating “adversarial examples”. It does so by rewarding desired outcomes (i.e., perturbations that bring the score closer to the decision boundary) and punishing undesired ones. Once the score is returned by the model, the features used to perturb the sample are given specific weights, depending on how they affect the score. Combinations of the most successful features are then used in subsequent turns.
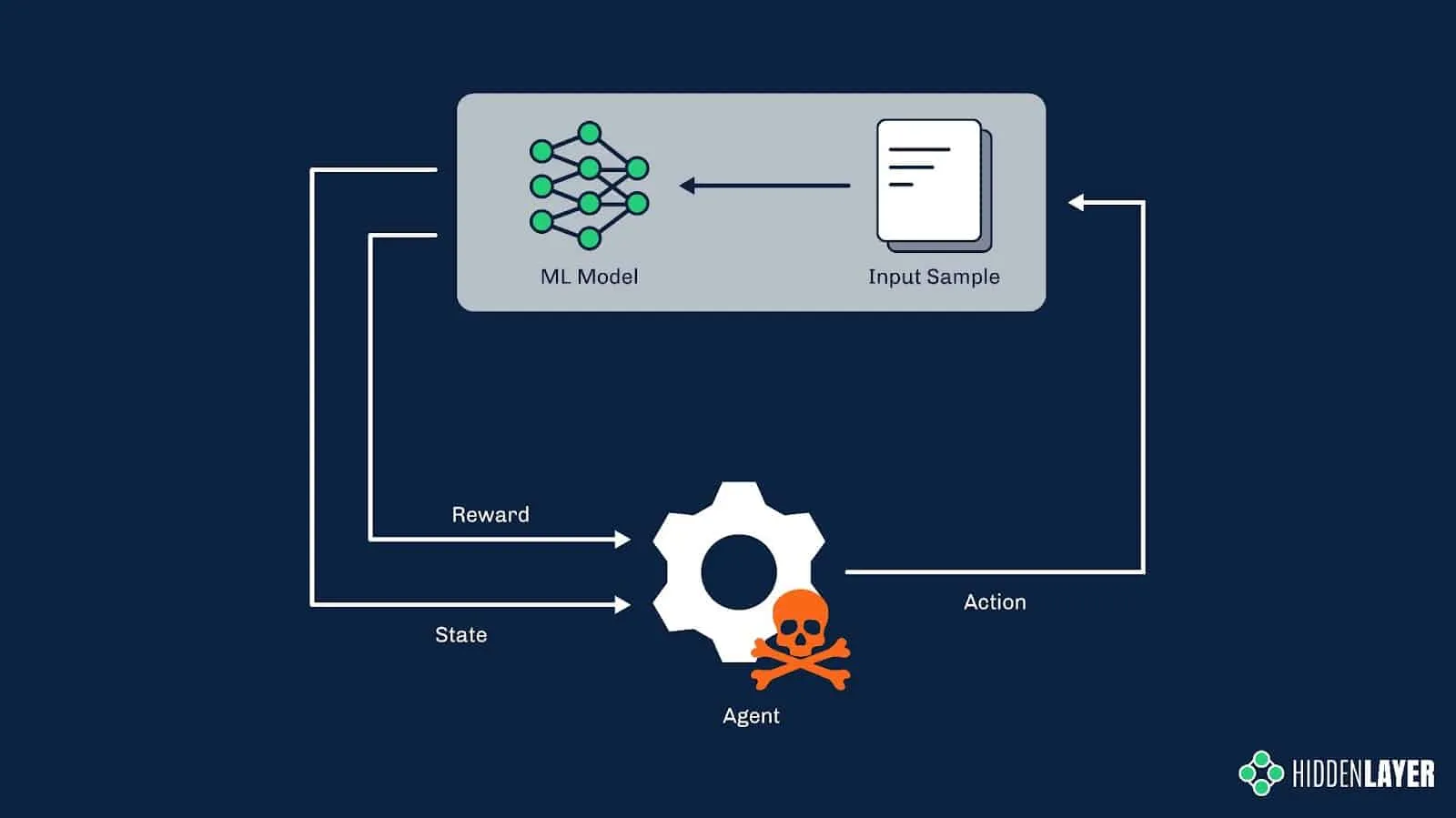
Figure 6: Reinforcement learning in adversarial settings
MalwareRL is implemented as a Docker container and can be downloaded, deployed, and used in an attack in a matter of minutes.
MalwareRL was naturally one of the first things we tossed at our MLDR solution. First, we’ve implemented the MLDR client around the target model to intercept input vectors and output scores for every single request that comes through to the model; next, we’ve downloaded the attack framework from GitHub and run it in a docker container. Result - a flurry of alerts from the MLDR sensor about a possible inference-based attack!
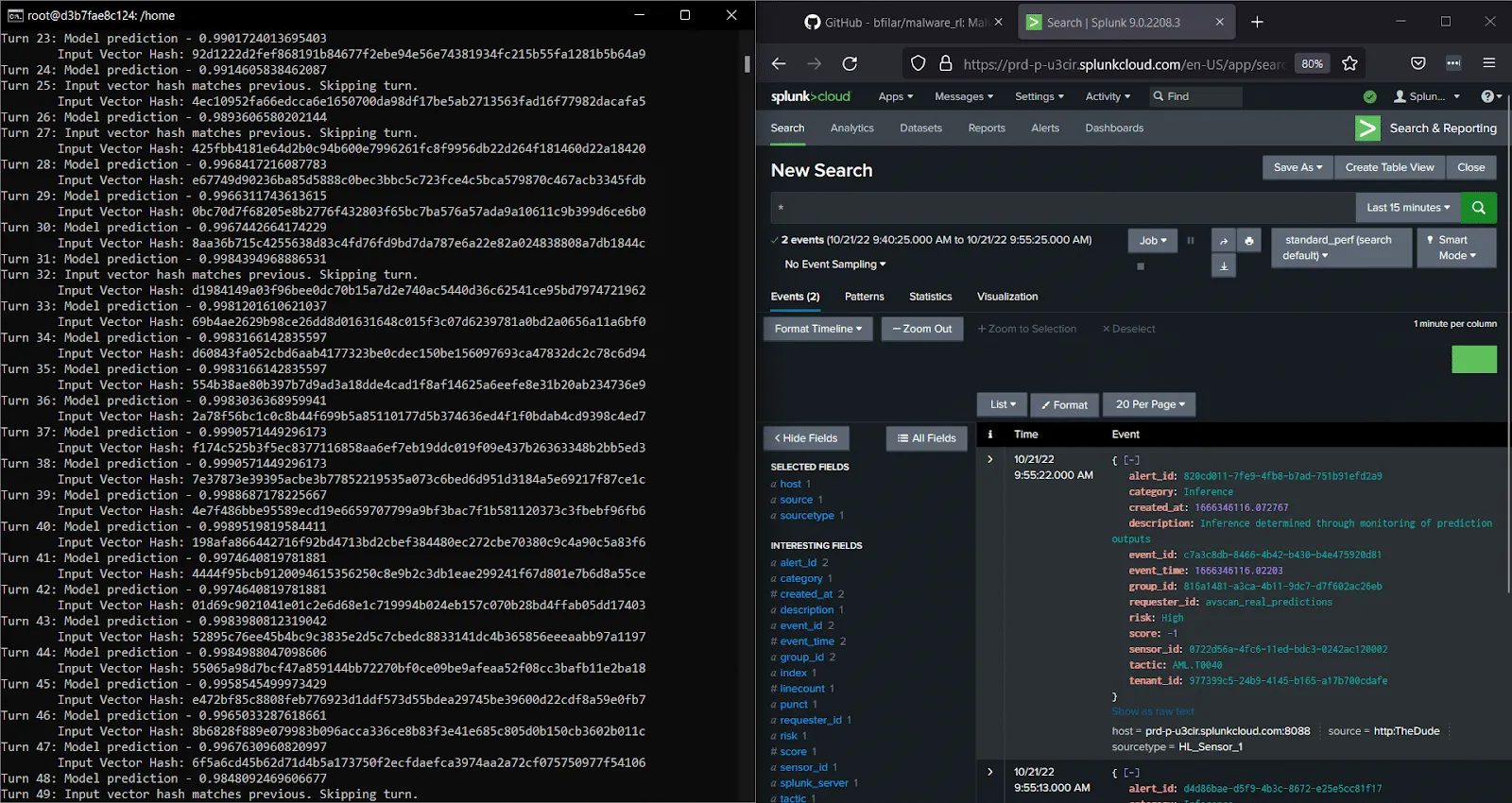
Figure 7: MLDR in action - detecting MalwareRL attack
One Pixel Attack - Fooling an Image Classifier
Away from the anti-malware industry, we will now look at how an inference-based attack can be used to bypass image classifiers. One Pixel Attack is one the most famous methods of perturbing a picture in order to fool an image recognition system. As the name suggests, it uses the smallest possible perturbation - a modification to one single pixel - to flip the image classification either to any incorrect label (untargeted attack) or to a specific, desired label (targeted attack).

Figure 8: An example of One Pixel Attack on a gender recognition model
To optimize the generation of adversarial examples, One Pixel Attack implementations use an evolutionary algorithm called Differential Evolution. First, an initial set of adversarial images is generated by modifying the color of one random pixel per example. Next, these pixels’ positions and colors are combined together to generate more examples. These images are then submitted to the model for scoring. Pixels that lower the confidence score are marked as best-known solutions and used in the next round of perturbations. The last iteration returns an image that achieved the lowest confidence score. A successful attack would result in such a reduction in confidence score that will flip the classification of the image.

Figure 9: Differential evolution; source: Wikipedia
We’ve run the One Pixel Attack over a ResNet model trained on the CelebA database. The model was built to recognize a photo of a human face as either male or female. We were able to create adversarial examples with an (often imperceptible!) one-pixel modification that tricked the model into predicting the opposing gender label. This kind of attack can be detected by monitoring the input vectors for large batches of images with very slight modifications.
Figure 10: One-pixel attack demonstration
Boundary Attack and HopSkipJump
While One Pixel Attack is based on perturbing the target image in order to trigger misclassification, other algorithms, such as Boundary Attack and its improved version, the HopSkipJump attack, use a different approach.
In Boundary Attack, we start with two samples: the sample we want the model to misclassify (the target sample) and any sample that triggers our desired classification (the adversarial example). The goal is to perturb the adversarial example in such a way that it bears the most resemblance to the target sample without triggering the model to change the predicted class. The Boundary Attack algorithm moves along the model’s decision boundary (i.e., the threshold between the correct and incorrect prediction) on the side of the adversarial class, starting from the adversarial example toward the target sample. At the end of this procedure, we should be presented with a sample that looks indistinguishable from the target image yet still triggers the adversarial classification.

Figure 11: Example of boundary attack, source: GitHub / greentfrapp
The original version of Boundary Attack uses a rejection sampling algorithm for choosing the next perturbation. This method requires a large number of model queries, which might be considered impractical in some attack scenarios. The HopSkipJump technique introduces an optimized way to estimate the subsequent steps along the decision boundary: it uses binary search to find the boundary, estimates the gradient direction, and calculates the step size via geometric progression.
The HopSkipJump attack can be used in many attack scenarios and not necessarily against image classifiers. Microsoft’s Counterfit framework implements a CreditFraud attack that uses the HopSkipJump technique, and we’ve chosen this implementation to test MLDR’s detection capability. In these kinds of inference attacks, often only very minor perturbations are made to the model input in order to infer decision boundaries. This can be detected using various distance metrics over a time series of model inputs from individual requestors.
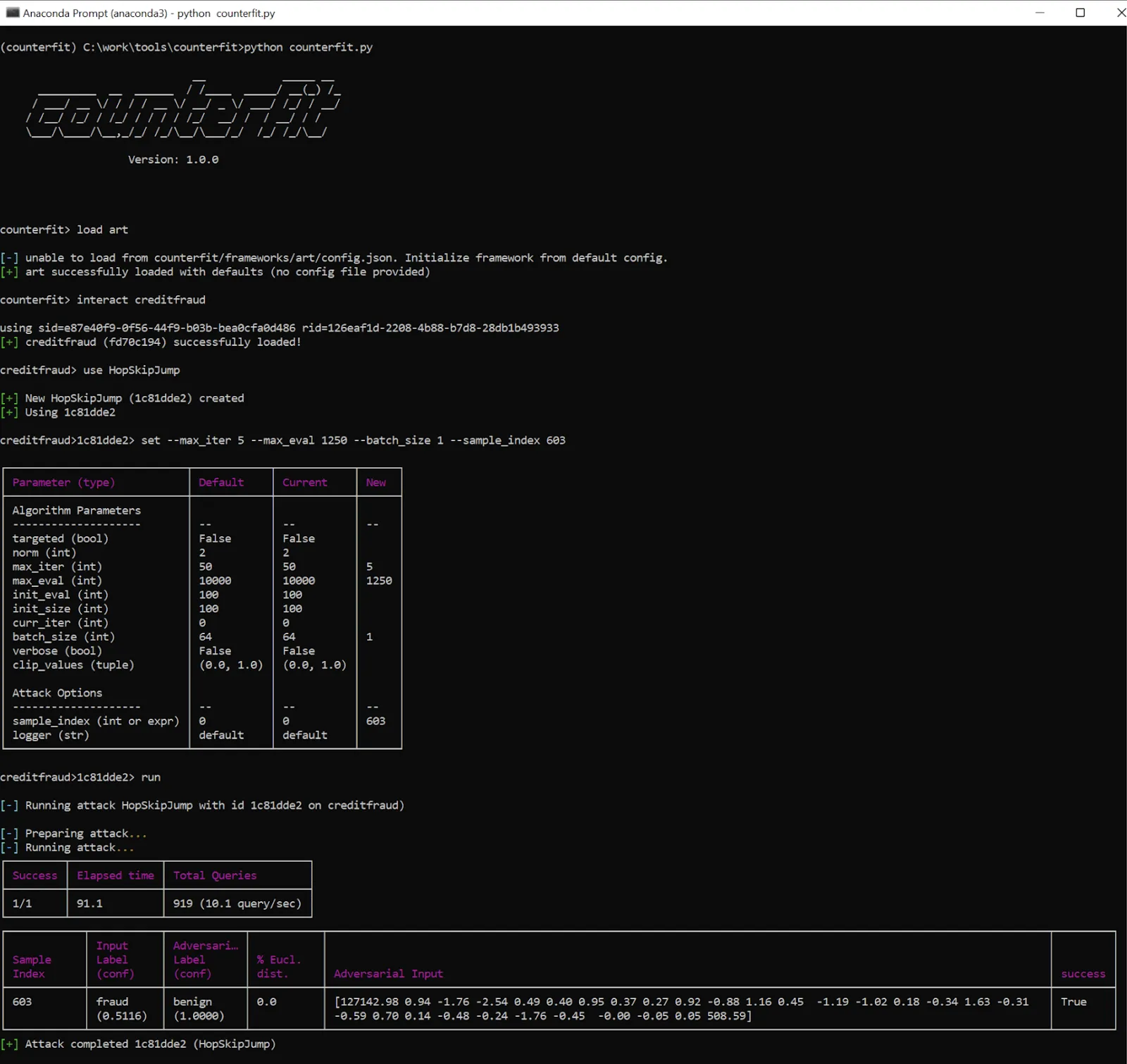
Figure 12: Launching an attack on a credit card fraud detection model using Counterfit
Adversarial Robustness Toolbox - Model Theft using KnockOffNets
Besides fooling various classifiers and regression models into making incorrect predictions, inference-based attacks can also be used to create a model replica - or, in other words, to steal the ML model. The attacker does not need to breach the company’s network and exfiltrate the model binary. As long as they have access to the model API and can query the input vectors and output scores, the attacker can spam the model with a large amount of specially crafted queries and use the queried input-prediction pairs to train a so-called shadow model. A skillful adversary can create a model replica that will behave almost exactly the same as the target model. All ML solutions that are exposed to the public, be it via GUI or API, are at high risk of being vulnerable to this type of attack.
Knockoff Nets is an open-source tool that shows how easy it is to replicate the functionality of neural networks with no prior knowledge about the training dataset or the model itself. As with MalwareRL, it uses reinforcement learning to improve the efficiency and performance of the attack. The authors claim that they can create a faithful model replica for as little as $30 - it might sound very appealing to some who would rather not spend considerable amounts of time and money on training their own models!
An attempt to create a model replica using KnockOffNets implementation from IBM’s Adversarial Robustness Toolbox can be detected by means of time-series analysis. A sequence of input vectors sent to the model in a specified period of time is analyzed along with predictions and compared to other such sequences in order to detect abnormalities. If all of a sudden the traffic to the model differs significantly from the usual traffic (be it per customer or globally), chances are that the model is under attack.
What’s next?
AI is a vast and rapidly growing industry. Most verticals are already using it to some capacity, with more still looking to implement it in the near future. Our lives are increasingly dependent on decisions made by machine learning algorithms. It’s therefore paramount to protect this critical technology from any malicious interference. The time to act is now, as the adversaries are already one step ahead.
By introducing the first-ever security solution for machine learning systems, we aim to highlight how vulnerable these systems are and underline the urgent need to fundamentally rethink the current approach to AI security. There is a lot to be done and the time is short; we have to work together as an industry to build up our defenses and stay on top of the bad guys.
The few types of attacks we described in this blog are just the tip of the iceberg. Fortunately, like other detection and response solutions, our MLDR is extensible, allowing us to continuously develop novel detection methods and deploy them as we go. We recently announced our MLSec platform, which comprises MLDR, Model Scanner, and Security Audit Reporting. We are not stopping there. Stay tuned for more information in the coming months.
Related Insights



.svg)
Thanks for joining us!
will be on the way soon.