Learn from our AI Security Experts
Discover every model. Secure every workflow. Prevent AI attacks - without slowing innovation.


min read
Integrating HiddenLayer’s Model Scanner with Databricks Unity Catalog
As machine learning becomes more embedded in enterprise workflows, model security is no longer optional. From training to deployment, organizations need a streamlined way to detect and respond to threats that might lurk inside their models. The integration between HiddenLayer’s Model Scanner and Databricks Unity Catalog provides an automated, frictionless way to monitor models for vulnerabilities as soon as they are registered. This approach ensures continuous protection without slowing down your teams.
Introduction
As machine learning becomes more embedded in enterprise workflows, model security is no longer optional. From training to deployment, organizations need a streamlined way to detect and respond to threats that might lurk inside their models. The integration between HiddenLayer’s Model Scanner and Databricks Unity Catalog provides an automated, frictionless way to monitor models for vulnerabilities as soon as they are registered. This approach ensures continuous protection without slowing down your teams.
In this blog, we’ll walk through how this integration works, how to set it up in your Databricks environment, and how it fits naturally into your existing machine learning workflows.
Why You Need Automated Model Security
Modern machine learning models are valuable assets. They also present new opportunities for attackers. Whether you are deploying in finance, healthcare, or any data-intensive industry, models can be compromised with embedded threats or exploited during runtime. In many organizations, models move quickly from development to production, often with limited or no security inspection.
This challenge is addressed through HiddenLayer’s integration with Unity Catalog, which automatically scans every new model version as it is registered. The process is fully embedded into your workflow, so data scientists can continue building and registering models as usual. This ensures consistent coverage across the entire lifecycle without requiring process changes or manual security reviews.
This means data scientists can focus on training and refining models without having to manually initiate security checks or worry about vulnerabilities slipping through the cracks. Security engineers benefit from automated scans that are run in the background, ensuring that any issues are detected early, all while maintaining the efficiency and speed of the machine learning development process. HiddenLayer’s integration with Unity Catalog makes model security an integral part of the workflow, reducing the overhead for teams and helping them maintain a safe, reliable model registry without added complexity or disruption.
Getting Started: How the Integration Works
To install the integration, contact your HiddenLayer representative to obtain a license and access the installer. Once you’ve downloaded and unzipped the installer for your operating system, you’ll be guided through the deployment process and prompted to enter environment variables.
Once installed, this integration monitors your Unity Catalog for new model versions and automatically sends them to HiddenLayer’s Model Scanner for analysis. Scan results are recorded directly in Unity Catalog and the HiddenLayer console, allowing both security and data science teams to access the information quickly and efficiently.
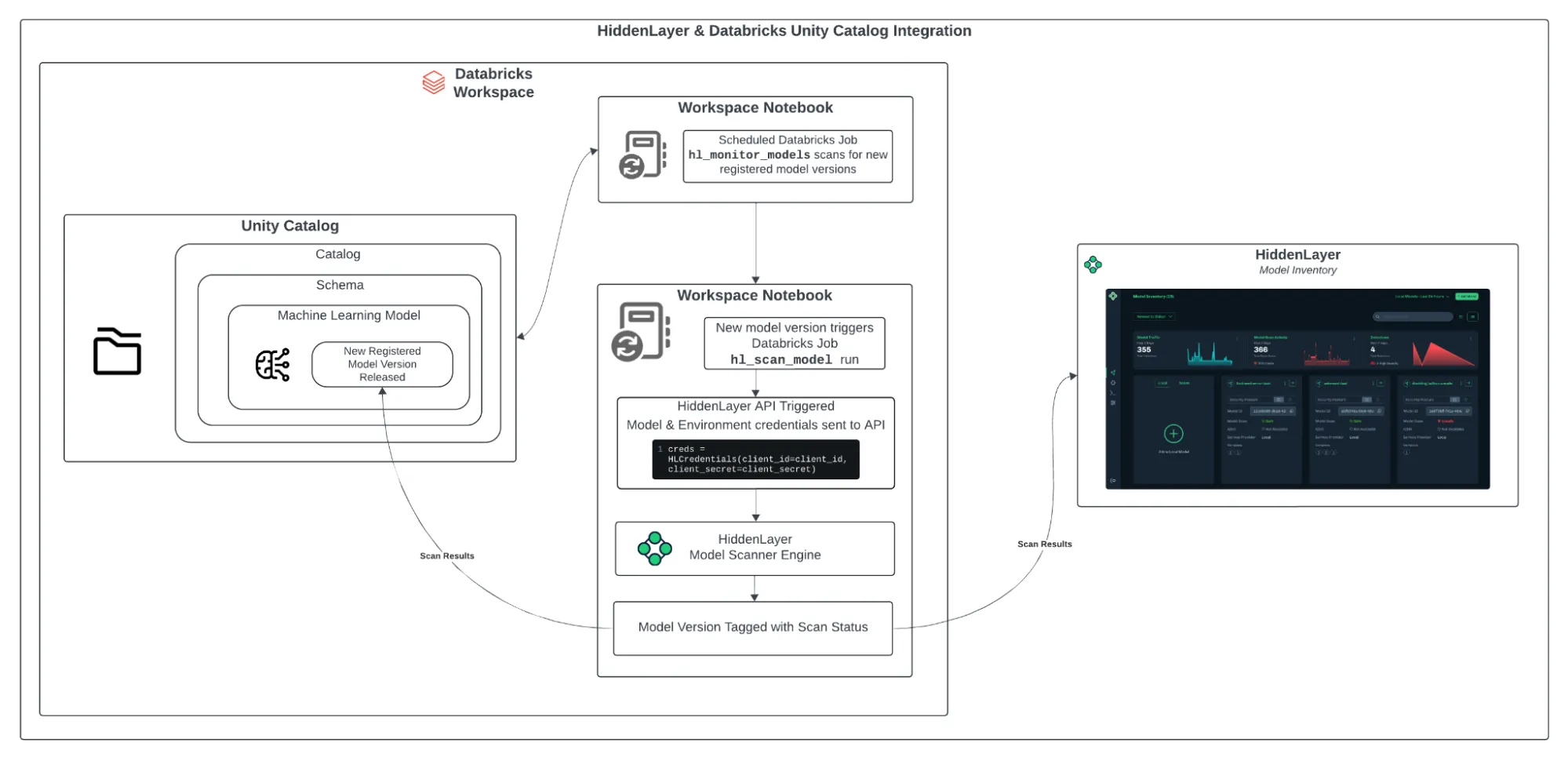
Figure 1: HiddenLayer & Databricks Architecture Diagram
The integration is simple to set up and operates smoothly within your Databricks workspace. Here’s how it works:
- Install the HiddenLayer CLI: The first step is to install the HiddenLayer CLI on your system. Running this installation will set up the necessary Python notebooks in your Databricks workspace, where the HiddenLayer Model Scanner will run.
- Configure the Unity Catalog Schema: During the installation, you will specify the catalogs and schemas that will be used for model scanning. Once configured, the integration will automatically scan new versions of models registered in those schemas.
- Automated Scanning: A monitoring notebook called hl_monitor_models runs on a scheduled basis. It checks for newly registered model versions in the configured schemas. If a new version is found, another notebook, hl_scan_model, sends the model to HiddenLayer for scanning.
- Reviewing Scan Results After scanning, the results are added to Unity Catalog as model tags. These tags include the scan status (pending, done, or failed) and a threat level (safe, low, medium, high, or critical). The full detection report is also accessible in the HiddenLayer Console. This allows teams to evaluate risk without needing to switch between systems.
Why This Workflow Works
This integration helps your team stay secure while maintaining the speed and flexibility of modern machine learning development.
- No Process Changes for Data Scientists
Teams continue working as usual. Model security is handled in the background. - Real-Time Security Coverage
Every new model version is scanned automatically, providing continuous protection. - Centralized Visibility
Scan results are stored directly in Unity Catalog and attached to each model version, making them easy to access, track, and audit. - Seamless CI/CD Compatibility
The system aligns with existing automation and governance workflows.
Final Thoughts
Model security should be a core part of your machine learning operations. By integrating HiddenLayer’s Model Scanner with Databricks Unity Catalog, you gain a secure, automated process that protects your models from potential threats.
This approach improves governance, reduces risk, and allows your data science teams to keep working without interruptions. Whether you’re new to HiddenLayer or already a user, this integration with Databricks Unity Catalog is a valuable addition to your machine learning pipeline. Get started today and enhance the security of your ML models with ease.
All Resources


Why Revoking Biden’s AI Executive Order Won’t Change Course for CISOs
On 20 January 2025, President Donald Trump rescinded former President Joe Biden’s 2023 executive order on artificial intelligence (AI), which had established comprehensive guidelines for developing and deploying AI technologies. While this action signals a shift in federal policy, its immediate impact on the AI landscape is minimal for several reasons.
Introduction
On 20 January 2025, President Donald Trump rescinded former President Joe Biden’s 2023 executive order on artificial intelligence (AI), which had established comprehensive guidelines for developing and deploying AI technologies. While this action signals a shift in federal policy, its immediate impact on the AI landscape is minimal for several reasons.
AI Key Initiatives
Biden’s executive order initiated extensive studies across federal agencies to assess AI’s implications on cybersecurity, education, labor, and public welfare. These studies have been completed, and their findings remain available to inform governmental and private sector strategies. The revocation of the order does not negate the value of these assessments, which continue to shape AI policy and development at multiple levels of government.
Continuity in AI Policy Framework
Many of the principles outlined in Biden’s order were extensions of policies from Trump’s first term, emphasizing AI innovation, safety, and maintaining U.S. leadership. This continuity suggests that the foundational approach to AI governance remains stable despite the order's formal rescission. The bipartisan nature of these principles ensures a relatively predictable policy environment for AI development.
State AI Regulations Remain in Play
While the executive order dictated federal policy, state-level AI legislation has always been more complex and detailed. States such as California, Illinois, and Colorado have enacted AI-related laws covering data privacy, automated decision-making, and algorithmic transparency. Additionally, several states have passed or have pending bills to regulate AI in employment, financial services, and law enforcement.
For example:
- California’s AI Regulations: Under these regulations, businesses using AI-driven decision-making tools must disclose how personal data is processed, and consumers have the right to opt out of automated profiling. Also, developers of generative AI systems or services must publicly post documentation on their website about the data used to train their AI.
- Illinois’ The Automated Decision Tools Act (pending): Deployers of automated decision tools will be required to conduct annual impact assessments. They must also implement governance programs to mitigate algorithmic discrimination risks.
- Colorado’s Consumer Protections for Artificial Intelligence: This legislation requires developers of high-risk AI systems to take reasonable precautions to protect consumers from known or foreseeable risks of algorithmic discrimination.
Even without a federal mandate, these state regulations ensure that AI governance remains a priority, adding layers of compliance for businesses operating across multiple jurisdictions.
Industry Adaptation and Ongoing AI Initiatives
The tech industry had already begun adapting to the guidelines outlined in Biden’s executive order. Many companies established internal AI governance frameworks, anticipating regulatory scrutiny. These proactive measures will persist as organizations recognize that self-regulation remains the best way to mitigate risks and maintain consumer trust.
Threat Actors Will Exploit AI Vulnerabilities
One thing that has remained true for decades is that threat actors will attack any technology they can. Cybercriminals have always exploited vulnerabilities for financial or strategic gain, whether on mainframes, floppy disks, early personal computers, cloud environments, or mobile devices. AI is no different.
Adversarial attacks against AI models, data poisoning, and prompt injection threats continue to evolve. Today’s key difference is whether organizations deploy purpose-built security measures to protect AI systems from these emerging threats. Regardless of federal policy shifts, the need for AI security remains constant.
Anticipated AI Regulatory Environment
The revocation of Biden’s order aligns with the Trump administration’s preference for a less restrictive regulatory framework. The administration aims to stimulate innovation by reducing federal oversight. However, state laws and industry self-regulation will continue to shape AI governance.
Existing privacy and cybersecurity regulations—such as GDPR, CCPA, HIPAA, and Sarbanes-Oxley—still apply to AI applications. Organizations must ensure transparency, data protection, and security regardless of changes at the federal level.
Global Competitiveness and National Security
Both the Biden and Trump administrations have emphasized the importance of U.S. leadership in AI, particularly concerning global competitiveness and national security. This shared priority ensures that strategic initiatives to advance AI capabilities persist, regardless of executive orders. The ongoing commitment to AI innovation reflects a national consensus on the technology’s critical role in the economy and defense.
Conclusion
While President Trump’s revocation of Biden’s AI executive order may seem like a significant policy shift, little has changed. AI security threats remain constant, industry best practices endure, and existing privacy and cybersecurity regulations continue to govern AI deployments.
Moreover, state-level AI legislation ensures that regulatory oversight persists, often in more granular detail than federal mandates. Businesses must still navigate compliance challenges, particularly in states with active AI regulatory frameworks.
Ultimately, despite the headlines, AI innovation, security, and governance in the U.S. remain on the same trajectory. The challenges and opportunities surrounding AI are unchanged—the focus should remain on securing AI systems and responsibly advancing the technology.

HiddenLayer Achieves ISO 27001 and Renews SOC 2 Type 2 Compliance
Security compliance is more than just a checkbox - it’s a fundamental requirement for protecting sensitive data, building customer trust, and ensuring long-term business growth. At HiddenLayer, security has always been at the core of our mission, and we’re proud to announce that we have achieved SOC 2 Type 2 and ISO 27001 compliance. These certifications reinforce our commitment to providing our customers with the highest level of security and reliability.
Security compliance is more than just a checkbox - it’s a fundamental requirement for protecting sensitive data, building customer trust, and ensuring long-term business growth. At HiddenLayer, security has always been at the core of our mission, and we’re proud to announce that we have achieved SOC 2 Type 2 and ISO 27001 compliance. These certifications reinforce our commitment to providing our customers with the highest level of security and reliability.
Why This Matters
Achieving both SOC 2 Type 2 and ISO 27001 compliance is a significant milestone for HiddenLayer. These internationally recognized certifications demonstrate that our security practices meet the rigorous standards necessary to protect customer data and ensure operational resilience. This accomplishment provides our clients, partners, and stakeholders with increased confidence that their sensitive information is safeguarded by industry-leading security controls.
SOC 2 Type 2: Ensuring Trust Through Continuous Security
Bolstering our SOC 2 Type 2 compliance achieved in November 2023, we are proud to share the renewal of our SOC 2 Type 2 compliance with the addition of the 4th and 5th Pillars. Before we made this renewal, we had achieved the Security, Availability, and Confidentiality pillars. After renewing our SOC 2 Type 2, we added Processing Integrity and Privacy, achieving all five pillars of SOC 2 Type 2 compliance.
SOC 2 Type 2 compliance validates that HiddenLayer has implemented and maintained strong security controls over an extended period. Unlike a one-time audit, this certification assesses our security practices over time, proving our dedication to ongoing risk management and operational excellence.
Key Trust Principles of SOC 2 Compliance:
- Security: Protection against unauthorized access and threats.
- Availability: Ensuring our systems remain reliable and accessible.
- Processing Integrity: Verifying accurate and complete data processing.
- Confidentiality: Safeguarding sensitive customer and business information.
- Privacy: Upholding responsible data management practices.
For organizations leveraging HiddenLayer’s solutions, this compliance means that we meet the stringent security requirements often demanded by enterprise customers and regulated industries. It simplifies vendor approval processes and accelerates business engagements by demonstrating our adherence to best security practices.
ISO 27001: A Global Standard for Information Security
ISO 27001 is an internationally recognized Information Security Management Systems (ISMS) standard. This certification ensures that HiddenLayer follows a structured approach to managing security risks, protecting data assets, and maintaining a culture of security-first operations.
Why ISO 27001 Matters:
- Aligns with global security regulations, enabling us to support clients worldwide.
- Helps organizations in highly regulated industries (finance, healthcare, government) meet strict compliance requirements.
- Strengthens internal processes by enforcing best practices for data protection and risk management.
- Demonstrates our proactive commitment to security, enhancing trust with customers, partners, and investors.
What This Means for Our Customers
By achieving both SOC 2 Type 2 and ISO 27001 compliance, HiddenLayer provides customers with the assurance that:
- Their data is protected with industry-leading security measures.
- We operate with integrity, transparency, and ongoing risk mitigation.
- Our security framework meets the highest compliance standards required for enterprise and government partnerships.
These certifications reinforce our commitment to security and reliability for our existing and future customers. Whether you’re evaluating HiddenLayer for AI security solutions or are already a valued partner, you can trust that we adhere to the highest security and compliance standards.
Security Is Our Priority
Security isn’t just something we do - it’s the foundation of our company. Achieving SOC 2 Type 2 and ISO 27001 compliance is just one part of our ongoing mission to ensure the safest, most secure AI security solutions on the market.
If you’re interested in learning more about how HiddenLayer’s security practices can support your organization, contact us today.

AI Risk Management: Effective Strategies and Framework
Artificial Intelligence (AI) is no longer just a buzzword—it’s a cornerstone of innovation across industries. However, with great potential comes significant risk. Effective AI Risk Management is critical to harnessing AI’s benefits while minimizing vulnerabilities. From data breaches to adversarial attacks, understanding and mitigating risks ensures that AI systems remain trustworthy, secure, and aligned with organizational goals.
Artificial Intelligence (AI) is no longer just a buzzword—it’s a cornerstone of innovation across industries. However, with great potential comes significant risk. Effective AI Risk Management is critical to harnessing AI’s benefits while minimizing vulnerabilities. From data breaches to adversarial attacks, understanding and mitigating risks ensures that AI systems remain trustworthy, secure, and aligned with organizational goals.
The Importance of AI Risk Management
AI systems process vast amounts of data and make decisions at unprecedented speeds. While these capabilities drive efficiency, they also introduce unique risks, such as:
- Adversarial Attacks: These attacks alter input data to mislead AI systems into making inaccurate predictions or classifications. For example, attackers may create adversarial examples designed to disrupt the algorithm's decision-making process or intentionally introduce bias.
- Prompt Injection: These attacks exploit large language models (LLMs) by embedding malicious inputs within seemingly legitimate prompts. This enables hackers to manipulate generative AI systems, potentially causing them to leak sensitive information, spread misinformation, or execute other harmful actions.
- Supply Chain: These attacks involve threat actors targeting AI systems through vulnerabilities in their development, deployment, or maintenance processes. For example, attackers may exploit weaknesses in third-party components integrated during AI development, resulting in data breaches or unauthorized access.
- Data Privacy Concerns: AI systems often rely on sensitive data, making them attractive targets for cyberattacks.
- Model Drift: Over time, AI models can deviate from their intended purpose, leading to inaccuracies and potential liabilities.
- Ethical Dilemmas: Biases in training data can result in unfair outcomes, eroding trust, and violating regulations.
AI Risk Management is the framework that identifies, assesses, and mitigates these challenges to safeguard AI operations.
The NIST AI Risk Management Framework
The National Institute of Standards and Technology (NIST) has developed a comprehensive AI Risk Management Framework (AI RMF) to guide organizations in managing AI risks effectively. NIST’s AI RMF provides a structured approach for organizations to align their AI initiatives with best practices and regulatory requirements, making it a cornerstone of any comprehensive AI Risk Management strategy.
This framework emphasizes:
- Governance: Establishing clear accountability and oversight structures for AI systems.
- Map: Identifying and categorizing risks associated with AI systems, considering their context and use cases.
- Measure: Assessing risks through quantitative and qualitative metrics to ensure that AI systems operate as intended.
- Manage: Implementing risk response strategies to mitigate or eliminate identified risks.
Core Principles of Effective AI Risk Management
To develop a comprehensive AI Risk Management strategy, organizations should focus on the following principles:
- Proactive Threat Assessment: Identify potential vulnerabilities in AI systems during the development and deployment stages.
- Continuous Monitoring: Implement systems that monitor AI performance in real-time to detect anomalies and model drift.
- Transparency and Explainability: Ensure AI models are interpretable and their decision-making processes can be audited.
- Collaboration Across Teams: To address risks comprehensively, involve cross-functional teams, including data scientists, cybersecurity experts, and legal advisors.
HiddenLayer’s Approach to AI Risk Management
At HiddenLayer, we specialize in securing AI systems through innovative solutions designed to combat evolving threats. Our approach includes:
Adversarial ML Training: Enhancing machine learning models’ comprehensiveness by simulating adversarial scenarios and training them to recognize and withstand attacks. This proactive measure strengthens models against potential exploitation.
AI Risk Assessment: A comprehensive analysis to identify vulnerabilities in AI systems, evaluate the potential impact of threats, and prioritize mitigation strategies. This service ensures organizations understand the risks they face and provides a clear roadmap for addressing them.
- Security for AI Retainer Service: A dedicated support model offering continuous monitoring, updates, and rapid response to emerging threats. This ensures ongoing protection and peace of mind for organizations leveraging AI technologies.
- Red Team Assessment: A hands-on approach where our experts simulate real-world attacks on AI systems to uncover vulnerabilities and recommend actionable solutions. This allows organizations to see their systems from an attacker’s perspective and fortify their defenses.
Why AI Risk Management Is Non-Negotiable
Organizations that neglect AI Risk Management expose themselves to financial, reputational, and operational risks. By prioritizing security for AI, businesses can:
- Build stakeholder trust by demonstrating a commitment to responsible AI use.
- Comply with regulatory standards, such as the EU AI Act and NIST guidelines.
- Enhance operational resilience against emerging threats.
Preparing for the Future of AI Risk
As AI technologies evolve, so do the risks. In addition to deploying an AI Risk Management Framework, organizations can stay ahead by:
- Investing in Training: Educating teams about AI-specific threats and best practices.
- Leveraging Advanced Security Tools: Deploying solutions like HiddenLayer’s platform to protect AI assets.
- Engaging in Industry Collaboration: Sharing insights and strategies to address shared challenges.
Conclusion
AI Risk Management is not just a necessity—it’s strategically imperative. By embedding security and transparency into AI systems, organizations can unlock artificial intelligence's full potential while safeguarding against its risks. HiddenLayer’s expertise in security for AI ensures that businesses can innovate with confidence in an increasingly complex threat landscape.
To learn more about how HiddenLayer can help secure your AI systems, contact us today.

Security for AI vs. AI Security
When we talk about securing AI, it’s important to distinguish between two concepts that are often conflated: Security for AI and AI Security. While they may sound similar, they address two entirely different challenges.
When we talk about securing AI, it’s important to distinguish between two concepts that are often conflated: Security for AI and AI Security. While they may sound similar, they address two entirely different challenges.
What Do These Terms Mean?
Security for AI refers to securing AI systems themselves. This includes safeguarding models, data pipelines, and training environments from malicious attacks, and ensuring AI systems function as intended without interference.
- Example: Preventing data poisoning attacks during model training or defending against adversarial examples that cause AI systems to make incorrect predictions.
AI Security, on the other hand, involves using AI technologies to enhance traditional cybersecurity measures. AI Security harnesses the power of AI to detect, prevent, and respond to cyber threats.
- Example: AI algorithms analyze network traffic to identify unusual patterns that signal a breach in traditional software.
Security for AI focuses on securing AI itself, whereas AI security utilizes AI to help enhance security practices. Understanding the difference between these two terms is crucial to making safe and responsible choices regarding cybersecurity for your organization.
The Real-World Impact of Overlooking Differences
Many organizations focus solely on AI Security, assuming it also covers AI-specific risks. This misconception can lead to significant vulnerabilities in their operations. While AI Security tools excel at enhancing traditional cybersecurity—detecting phishing attempts, identifying malware, or monitoring network traffic for anomalies—they are not designed to address the unique threats AI systems face.
For example, data poisoning attacks target the training datasets used to build AI models, subtly altering data to manipulate outcomes. Traditional cybersecurity solutions rarely monitor the training phase of AI development, leaving these attacks undetected. Similarly, model theft—where attackers reverse-engineer or extract proprietary AI models—exploits weaknesses in model deployment environments. These attacks can result in intellectual property loss or even malicious misuse of stolen models, such as embedding them in adversarial tools.
Bridging this gap means deploying Security for AI in order to protect AI Security. It involves monitoring and hardening AI systems at every stage—from training to deployment—while leveraging AI Security tools to defend broader IT environments. Organizations that fail to address these AI-specific risks may not realize the gap in their defenses until it’s too late, facing both operational and reputational damage. Comprehensive protection requires acknowledging these differences and investing in strategies that address both domains.
The Limitations of Traditional AI Security Vendors
As Malcolm Harkins, CISO at HiddenLayer, highlighted in his recent blog shared by RSAC, many traditional AI Security vendors fall short when it comes to securing AI systems. They often focus on applying AI to existing cybersecurity challenges—like anomaly detection or malware analysis—rather than addressing AI-specific vulnerabilities.
For example, a vendor might offer an AI-powered solution for phishing detection but lacks the tools to secure the AI that powers it. This gap exposes AI systems to threats that traditional security measures aren’t equipped to handle.
Services That Address These Challenges
Understanding what each type of vendor offers can clarify the distinction:
Security for AI Vendors:
- AI model hardening against adversarial attacks, like red teaming AI.
- Monitoring and detection of threats targeting AI systems.
- Secure handling of training data and access control.
AI Security Vendors:
- AI-driven tools for malware detection and intrusion prevention.
- Behavioral anomaly monitoring using machine learning.
- Threat intelligence powered by AI.
Understanding the Frameworks
Both Security for AI and AI Security have their own respective frameworks tied to them. While Security for AI frameworks protect AI systems themselves, AI Security frameworks focus on improving broader cybersecurity measures by leveraging AI capabilities. Together, they form a complementary approach to modern security needs.
Frameworks for Security for AI
Organizations can leverage several key frameworks to build a comprehensive security strategy for AI, each addressing different aspects of protecting AI systems.
- Gartner AI TRiSM: Focuses on trust, risk management, and security across the AI lifecycle. Key elements include model interpretability, risk mitigation, and compliance controls.
- MITRE ATLAS: Maps adversarial threats to AI systems, offering guidance on identifying vulnerabilities like data poisoning and adversarial examples with tailored countermeasures.
- OWASP Top 10 for LLMs: Highlights critical risks for generative AI, such as prompt injection attacks, data leakage, and insecure deployment, ensuring LLM applications remain safe.
- NIST AI RMF (AI Risk Management Framework): Guides organizations in managing AI-driven systems with a focus on trustworthiness and risk mitigation. AI Security applications include ethical deployment of AI for monitoring and defending IT infrastructures.
Combining these frameworks provides a comprehensive approach to securing AI systems, addressing vulnerabilities, ensuring compliance, and fostering trust in AI operations.
Frameworks for AI Security
Organizations can utilize several frameworks to enhance AI Security, focusing on leveraging AI to improve cybersecurity measures. These frameworks address different aspects of threat detection, prevention, and response.
- MITRE ATT&CK: A comprehensive database of adversary tactics and techniques. AI models trained on this framework can detect and respond to attack patterns across networks, endpoints, and cloud environments.
- Zero Trust Architecture (ZTA): A security model emphasizing "never trust, always verify." AI enhances ZTA by enabling real-time anomaly detection, dynamic access controls, and automated responses to threats.
- Cloud Security Alliance (CSA) AI Guidelines: Offers best practices for integrating AI into cloud security. Focus areas include automated monitoring, AI-driven threat detection, and secure deployment of cloud-based AI tools.
Integrating these frameworks provides a comprehensive AI Security strategy, enabling organizations to detect and respond to cyber threats effectively while leveraging AI’s full potential in safeguarding digital environments.
Conclusion
AI is a powerful enabler for innovation, but without the proper safeguards, it can become a significant risk, creating more roadblocks for innovation than serving as a catalyst for it. Organizations can ensure their systems are protected and prepared for the future by understanding what Security for AI and AI Security are and when it is best to use each.
The challenge lies in bridging the gap between these two approaches and working with vendors that offer expertise in both. Take a moment to assess your current AI security posture—are you doing enough to secure your AI, or are you only scratching the surface?

The Next Step in AI Red Teaming, Automation
Red teaming is essential in security, actively probing defenses, identifying weaknesses, and assessing system resilience under simulated attacks. For organizations that manage critical infrastructure, every vulnerability poses a risk to data, services, and trust. As systems grow more complex and threats become more sophisticated, traditional red teaming encounters limits, particularly around scale and speed. To address these challenges, we built the next step in red teaming: an <a href="https://hiddenlayer.com/autortai/"><strong>Automated Red Teaming for AI solution</strong><strong> </strong>that combines intelligence and efficiency to achieve a level of depth and scalability beyond what human-led efforts alone can offer.
Red teaming is essential in security, actively probing defenses, identifying weaknesses, and assessing system resilience under simulated attacks. For organizations that manage critical infrastructure, every vulnerability poses a risk to data, services, and trust. As systems grow more complex and threats become more sophisticated, traditional red teaming encounters limits, particularly around scale and speed. To address these challenges, we built the next step in red teaming: an Automated Red Teaming for AI solution that combines intelligence and efficiency to achieve a level of depth and scalability beyond what human-led efforts alone can offer.
Red Teaming: The Backbone of Security Testing
Red teaming is designed to simulate adversaries. Rather than assuming everything works as expected, a red team dives deep into a system, looking for gaps and blind spots. By using the same tactics that malicious actors might use, red teams expose vulnerabilities in a controlled setting, giving defenders (the blue team) a chance to understand the risks and shore up their defenses before any real threat occurs.
Human-led red teaming, with its creative, adaptable approach, excels in testing complex systems that require in-depth analysis and insight. However, this approach demands considerable time, specialized expertise, and resources, limiting its frequency and scalability—two critical factors when threats are continuously evolving.
Enter Automated AI Red Teaming
Automated AI red teaming addresses these challenges by adding a fast, scalable, and repeatable layer of defense. While human-led red teams may conduct a full attack simulation once per quarter, automated tools can operate continuously, uncovering new vulnerabilities as they arise.
With automated AI red teaming, security can be maintained in a data-driven environment that requires constant vigilance. Routine scans monitor critical systems, while ad hoc scans can be deployed for specific events like system updates or emerging threats. This shifts red teaming from periodic testing to a continuous security practice, offering resilience that’s difficult to match with manual methods alone.
Human vs. Automated AI Red Teaming: When to Use Each
Each approach—human-led and automated—has strengths, and knowing when to deploy each is key to comprehensive security.
- Human-Led Red Teaming: Skilled professionals bring creative attack strategies that automated systems can’t easily replicate. Human-led teams are particularly valuable for testing complex infrastructure and assessing risks that require adaptive thinking. For example, a team might find a vulnerability in employee practices or facility security—scenarios beyond the scope of automation.
- Automated AI Red Teaming: Automation is ideal for achieving fast, broad coverage across systems, particularly in AI-driven environments where innovation outpaces manual testing. Automated tools handle routine but essential checks, adapting as systems evolve to provide a consistent layer of defense.
By combining both methods, organizations benefit from the speed and efficiency of automation, reserving human-led red teaming for targeted, nuanced analysis that dives deep into system intricacies. This ultimately accelerates AI adoption and deployment of use cases into production.
Key Benefits of HiddenLayer’s Automated Red Teaming for AI
Automated red teaming brings critical capabilities that make security testing continuous and scalable, enabling teams to protect complex systems with ease:
- Unified Results Access: Real-time visibility into vulnerabilities and impacts allows both red and blue teams to work collaboratively on remediation, streamlining the process.
- Collaborative Test Development: Red teams can design attack scenarios informed by real-world threats, integrating blue team insights to create a realistic testing environment.
- Centralized Platform: Built directly into the AISEC Platform to simulate adversarial attacks on Generative AI systems, enabling teams to identify vulnerabilities and strengthen defenses proactively.
- Progress Tracking & Metrics: Automated tools provide metrics that track security posture over time, giving teams measurable insights into their efforts and progress.
- Scalability for Expanding AI Systems: As new AI models are added or scaled, automated red teaming grows alongside, ensuring comprehensive testing as systems expand.
- Cost and Time Savings: Automation reduces manual labor for routine testing, saving on resources while accelerating vulnerability detection and minimizing potential fallout.
- Ad Hoc and Scheduled Scans: Flexibility in scheduling scans allows for regular vulnerability checks or targeted scans triggered by events like system updates, ensuring no critical checks are missed.
Embracing the Future of Red Teaming
Automated AI red teaming isn’t just a technological advancement; it’s a shift in security strategy. By balancing the high-value insights that only human teams can provide with the efficiency and adaptability of automation, organizations can defend against evolving threats with comprehensive strength.
With HiddenLayer’s Automated Red Teaming for AI, security teams gain expert-level vulnerability testing in one click, eliminating the complexity of manual assessments. Our solution leverages industry-leading AI research to simulate real-world attacks, enabling teams to secure AI assets proactively, stay on schedule, and protect AI infrastructure with resilience.
Learn More about Automated Red Teaming for AI
Attend our Webinar “Automated Red Teaming for AI Explained”

Understanding AI Data Poisoning
Today, AI is woven into everyday technology, driving everything from personalized recommendations to critical healthcare diagnostics. But what happens if the data feeding these AI models is tampered with? This is the risk posed by AI data poisoning—a targeted attack where someone intentionally manipulates training data to disrupt how AI systems operate. Far from science fiction, AI data poisoning is a growing digital security threat that can have real-world impacts on everything from personal safety to financial stability.
Today, AI is woven into everyday technology, driving everything from personalized recommendations to critical healthcare diagnostics. But what happens if the data feeding these AI models is tampered with? This is the risk posed by AI data poisoning—a targeted attack where someone intentionally manipulates training data to disrupt how AI systems operate. Far from science fiction, AI data poisoning is a growing digital security threat that can have real-world impacts on everything from personal safety to financial stability.
What is AI Data Poisoning?
AI data poisoning refers to an attack where harmful or deceptive data is mixed into the dataset used to train a machine learning model. Because the model relies on training data to “learn” patterns, poisoning it can skew its behavior, leading to incorrect or even dangerous decisions. Imagine, for example, a facial recognition system that fails to correctly identify individuals because of poisoned data or a financial fraud detection model that lets certain transactions slip by unnoticed.
Data poisoning can be especially harmful because it can go undetected and may be challenging to fix once the model has been trained. It’s a way for attackers to influence AI, subtly making it malfunction without obvious disruptions.
How Does Data Poisoning Work?
In AI, the quality and accuracy of the training data determine how well the model works. When attackers manipulate the training data, they can cause models to behave in ways that benefit them. Here are the main ways they do it:
- Degrading Model Performance: Here, the attacker aims to make the model perform poorly overall. By introducing noisy, misleading, or mislabeled data, they can make the model unreliable. This might cause an image recognition model, for example, to misidentify objects.
- Embedding Triggers in the Model (Backdoors): In this scenario, attackers hide specific patterns or “triggers” within the model. When these patterns show up during real-world use, they make the model behave in unexpected ways. Imagine a sticker on a stop sign that confuses an autonomous vehicle, making it think it’s a yield sign and not a stop.
- Biasing the Model’s Decisions: This type of attack pushes the model to favor certain outcomes. For instance, if a hiring algorithm is trained on poisoned data, it might show a preference for certain candidates or ignore qualified ones, introducing bias into the process.
Why Should the Public Care About AI Data Poisoning?
Data poisoning may seem technical, but it has real-world consequences for anyone using technology. Here’s how it can affect everyday life:
- Healthcare: AI models are increasingly used to assist in diagnosing conditions and recommending treatments. Patients might receive incorrect or harmful medical advice if these models are trained on poisoned data.
- Finance: AI powers many fraud detection systems and credit assessments. Poisoning these models could allow fraudulent transactions to bypass security systems or skew credit assessments, leading to unfair financial outcomes.
- Security: Facial recognition and surveillance systems used for security are often AI-driven. Poisoning these systems could allow individuals to evade detection, undermining security efforts.
As AI becomes more integral to our lives, the need to ensure that these systems are reliable and secure grows. Data poisoning represents a direct threat to this reliability.
Recognizing a Poisoned Model
Detecting data poisoning can be challenging, as the malicious data often blends in with legitimate data. However, researchers look for these signs:
- Unusual Model Behavior: If a model suddenly begins making strange or obviously incorrect predictions after being retrained, it could be a red flag.
- Performance Drops: Poisoned models might start struggling with tasks they previously handled well.
- Sensitive to Certain Inputs: Some models may be more likely to make specific errors, especially when particular “trigger” inputs are present.
While these signs can be subtle, it’s essential to catch them early to ensure the model performs as intended.
How Can AI Systems Be Protected?
Combatting data poisoning requires multiple layers of defense:
- Data Validation: Regularly validating the data used to train AI models is essential. This may involve screening for unusual patterns or inconsistencies in the data.
- Robustness Testing: By stress-testing models with potential adversarial scenarios, AI engineers can determine if the model is overly sensitive to specific inputs or patterns that could indicate a backdoor.
- Continuous Monitoring: Real-time monitoring can detect sudden performance drops or unusual behavior, allowing timely intervention.
- Redundant Datasets: Using data from multiple sources can reduce the chance of contamination, making it harder for attackers to poison a model fully.
- Evolving Defense Techniques: Just as attackers develop new poisoning methods, defenders constantly improve their strategies to counteract them. AI security is a dynamic field, with new defenses being tested and implemented regularly.
How Can the Public Play a Role in Security for AI?
Although AI security often falls to specialists, the general public can help foster a safer AI landscape:
- Support AI Security Standards: Advocate for stronger regulations and transparency in AI, which encourage better practices for handling and protecting data.
- Stay Informed: Understanding how AI systems work and the potential threats they face can help you ask informed questions about the technologies you use.
- Report Anomalies: If you notice an AI-powered application behaving in unexpected or problematic ways, reporting these issues to the developers helps improve security.
Building a Secure AI Future
AI data poisoning highlights the importance of secure, reliable AI systems. While it introduces new threats, AI security is evolving to counter these dangers. By understanding AI data poisoning, we can better appreciate the steps needed to build safer AI systems for the future.
When well-secured, AI can continue transforming industries and improving lives without compromising security or reliability. With the right safeguards and informed users, we can work toward an AI-powered future that benefits us all.

The EU AI Act: A Groundbreaking Framework for AI Regulation
Artificial intelligence (AI) has become a central part of our digital society, influencing everything from healthcare to transportation, finance, and beyond. The European Union (EU) has recognized the need to regulate AI technologies to protect citizens, foster innovation, and ensure that AI systems align with European values of privacy, safety, and accountability. In this context, the EU AI Act is the world’s first comprehensive legal framework for AI. The legislation aims to create an ecosystem of trust in AI while balancing the risks and opportunities associated with its development.
Introduction
Artificial intelligence (AI) has become a central part of our digital society, influencing everything from healthcare to transportation, finance, and beyond. The European Union (EU) has recognized the need to regulate AI technologies to protect citizens, foster innovation, and ensure that AI systems align with European values of privacy, safety, and accountability. In this context, the EU AI Act is the world’s first comprehensive legal framework for AI. The legislation aims to create an ecosystem of trust in AI while balancing the risks and opportunities associated with its development.
What is the EU AI Act?
The European Commission first proposed the EU AI Act in April 2021. The act seeks to regulate the development, commercialization, and use of AI technologies across the EU. It adopts a risk-based approach to AI regulation, classifying AI applications into different risk categories based on their potential impact on individuals and society.
The legislation covers all stakeholders in the AI supply chain, including developers, deployers, and users of AI systems. This broad scope ensures that the regulation applies to various sectors, from public institutions to private companies, whether they are based in the EU or simply providing AI services within the EU’s jurisdiction.
When Will the EU AI Act be Enforced?
As of August 1st, 2024, the EU AI act entered into force. Member States have until August 2nd, 2025, to designate national competent authorities to oversee the application of the rules for AI systems and carry out market review activities. The Commission's AI Office will be the primary implementation body for the AI Act at EU level, as well as the enforcer for the rules for general-purpose AI models. Companies not complying with the rules will be fined. Fines could go up to 7% of the global annual turnover for violations of banned AI applications, up to 3% for violations of other obligations, and up to 1.5% for supplying incorrect information. The majority of the rules of the AI Act will start applying on August 2nd, 2026. However, prohibitions of AI systems deemed to present an unacceptable risk will apply after six months, while the rules for so-called General-Purpose AI models will apply after 12 months. To bridge the transitional period before full implementation, the Commission has launched the AI Pact. This initiative invites AI developers to voluntarily adopt key obligations of the AI Act ahead of the legal deadlines.
Key Provisions of the EU AI Act
The EU AI Act divides AI systems into four categories based on their potential risks:
- Unacceptable Risk AI Systems: AI systems that pose a significant threat to individuals’ safety, livelihood, or fundamental rights are banned outright. These include AI systems used for mass surveillance, social scoring (similar to China’s controversial social credit system), and subliminal manipulation that could harm individuals.
- High-Risk AI Systems: These systems have a substantial impact on people’s lives and are subject to stringent requirements. Examples include AI applications in critical infrastructure (like transportation), education (such as AI used in admissions or grading), employment (AI used in hiring or promotion decisions), law enforcement, and healthcare (diagnostic tools). High-risk AI systems must meet strict requirements for risk management, transparency, human oversight, and data quality.
- Limited Risk AI Systems: AI systems that do not pose a direct threat but still require transparency fall into this category. For instance, chatbots or AI-driven customer service systems must clearly inform users that they are interacting with an AI system. This transparency requirement ensures that users are aware of the technology they are engaging with.
- Minimal Risk AI Systems: The majority of AI applications, such as spam filters or AI used in video games, fall under this category. These systems are largely exempt from the new regulations and can operate freely, as their potential risks are deemed negligible.
Positive Goals of the EU AI Act
The EU AI Act is designed to protect consumers while encouraging innovation in a regulated environment. Some of its key positive outcomes include:
- Enhanced Trust in AI Technologies: By setting clear standards for transparency, safety, and accountability, the EU aims to build public trust in AI. People should feel confident that the AI systems they interact with comply with ethical guidelines and protect their fundamental rights. The transparency rules, in particular, help ensure that AI is used responsibly, whether in hiring processes, healthcare diagnostics, or other critical areas.
- Harmonization of AI Standards Across the EU: The act will harmonize AI regulations across all member states, providing a single market for AI products and services. This eliminates the complexity for companies trying to navigate different regulations in each EU country. For European AI developers, this reduces barriers to scaling products across the continent, thereby promoting innovation.
- Human Oversight and Accountability: High-risk AI systems will need to maintain human oversight, ensuring that critical decisions are not left entirely to algorithms. This human-in-the-loop approach aims to prevent scenarios where automated systems make life-changing decisions without proper human review. Whether in law enforcement, healthcare, or employment, this oversight reduces the risks of bias, discrimination, and errors.
- Fostering Responsible Innovation: While setting guardrails around high-risk AI, the act allows for lower-risk AI systems to continue developing without heavy restrictions. This balance encourages innovation, particularly in sectors where AI’s risks are limited. By focusing regulation on the areas of highest concern, the act promotes responsible technological progress.
Potential Negative Consequences for Innovation
While the EU AI Act brings many benefits, it also raises concerns, particularly regarding its impact on innovation:
- Increased Compliance Costs for Businesses: For companies developing high-risk AI systems, the act’s stringent requirements on risk management, documentation, transparency, and human oversight will lead to increased compliance costs. Small and medium-sized enterprises (SMEs), which often drive innovation, may struggle with these financial and administrative burdens, potentially slowing down AI development. Large companies with more resources might handle the regulations more easily, leading to less competition in the AI space.
- Slower Time-to-Market: With the need for extensive testing, documentation, and third-party audits for high-risk AI systems, the time it takes to bring AI products to market may be significantly delayed. In fast-moving sectors like technology, these delays could mean European companies fall behind global competitors, especially those from less-regulated regions like the U.S. or China.
- Impact on Startups and AI Research: Startups and research institutions may find it challenging to meet the requirements for high-risk AI systems due to limited resources. This could discourage experimentation and the development of innovative solutions, particularly in areas where AI might provide transformative benefits. The potential chilling effect on AI research could slow the development of cutting-edge technologies that are crucial to the EU’s digital economy.
- Global Competitive Disadvantage: While the EU is leading the charge in regulating AI, the act might place European companies at a disadvantage globally. In less-regulated markets, companies may be able to develop and deploy AI systems more rapidly and with fewer restrictions. This could lead to a scenario where non-EU firms outpace European companies in innovation, limiting the EU’s competitiveness on the global stage.
Conclusion
The EU AI Act represents a landmark effort to regulate artificial intelligence in a way that balances its potential benefits with its risks. By taking a risk-based approach, the EU aims to protect citizens’ rights, enhance transparency, and foster trust in AI technologies. At the same time, the act's stringent requirements for high-risk AI systems raise concerns about its potential to stifle innovation, particularly for startups and SMEs.
As the legislation moves closer to being fully enforced, businesses and policymakers will need to work together to ensure that the EU AI Act achieves its objectives without slowing down the technological progress that is vital for Europe’s future. While the act’s long-term impact remains to be seen, it undoubtedly sets a global precedent for how AI can be regulated responsibly in the digital age.

Key Takeaways from NIST's Recent Guidance
On July 29th, 2024, the National Institute of Standards and Technology (NIST) released critical guidance that outlines best practices for managing cybersecurity risks associated with AI models. This guidance directly ties into several comments we submitted during the open comment periods, highlighting areas where HiddenLayer effectively addresses emerging cybersecurity challenges.
On July 29th, 2024, the National Institute of Standards and Technology (NIST) released critical guidance that outlines best practices for managing cybersecurity risks associated with AI models. This guidance directly ties into several comments we submitted during the open comment periods, highlighting areas where HiddenLayer effectively addresses emerging cybersecurity challenges.
Understanding and Mitigating Threat Profiles
Practice 1.2 emphasizes the importance of assessing the impact of various threat profiles on public safety if a malicious actor misuses an AI model. Evaluating how AI models can be exploited to increase the scale, reduce costs, or improve the effectiveness of malicious activities is crucial. HiddenLayer can play a pivotal role here by offering advanced threat modeling and risk assessment tools that enable organizations to identify, quantify, and mitigate the potential harm threat actors could cause using AI models. By providing insights into how these harms can be prevented or managed outside the model context, we help organizations develop robust defensive strategies.
Roadmap for Managing Misuse Risks
Practice 2.2 calls for establishing a roadmap to manage misuse risks, particularly for developing foundation models and future versions. Our services can support organizations in defining clear security goals and implementing necessary safeguards to protect against misuse. We provide a comprehensive security framework that includes the development of security practices tailored to specific AI models, ensuring that organizations can adjust their deployment strategies when misuse risks escalate beyond acceptable levels.
Model Theft and Security Practices
As outlined in Practices 3.1, 3.2, and 3.3, model theft is a significant concern. HiddenLayer offers a suite of security tools designed to protect AI models from theft, including advanced cybersecurity red teaming and penetration testing. Organizations can better protect their intellectual property by assessing the risk of model theft from various threat actors and implementing robust security practices. Our tools are designed to scale security measures in proportion to the model's risk, ensuring that insider threats and external attacks are effectively mitigated.
Red Teaming and Misuse Detection
In Practice 4.2, NIST emphasizes the importance of using red teams to assess potential misuse. HiddenLayer provides access to teams that specialize in testing AI models in realistic deployment contexts. This helps organizations verify that their models are resilient against potential misuse, ensuring that their security measures are up to industry standards.
Proportional Safeguards and Deployment Decisions
Practices 5.2 and 5.3 focus on implementing safeguards proportionate to the model’s misuse risk and making informed deployment decisions based on those risks. HiddenLayer offers dynamic risk assessment tools that help organizations evaluate whether their safeguards are sufficient before proceeding with deployments. We also provide support in adjusting or delaying deployments until the necessary security measures are in place, minimizing the risk of misuse.
Monitoring for Misuse
Continuous monitoring of distribution channels for evidence of misuse, as recommended in Practice 6.1, is a critical component of AI model security. HiddenLayer provides automated tools that monitor APIs, websites, and other distribution channels for suspicious activity. Integrating these tools into an organization’s security infrastructure enables real-time detection and response to potential misuse, ensuring that malicious activities are identified and addressed promptly.
Transparency and Accountability
In line with Practice 7.1, we advocate for transparency in managing misuse risks. HiddenLayer enables organizations to publish detailed transparency reports that include key information about the safeguards in place for AI models. By sharing methodologies, evaluation results, and data relevant to assessing misuse risk, organizations can demonstrate their commitment to responsible AI deployment and build trust with stakeholders.
Governance and Risk Management in AI
NIST’s guidance also includes comprehensive recommendations on governance, as outlined in GOVERN Practices 1.2 to 6.2. HiddenLayer supports the integration of trustworthy AI characteristics into organizational policies and risk management processes. We help organizations establish clear policies for monitoring and reviewing AI systems, managing third-party risks, and ensuring compliance with legal and regulatory requirements.
Adversarial Testing and Risk Assessment
Regular adversarial testing and risk assessment, as discussed in MAP Practices 2.3 to 5.1, are essential for identifying vulnerabilities in AI systems. HiddenLayer provides tools for adversarial role-playing exercises, red teaming, and chaos testing, helping organizations identify and address potential failure modes and threats before they can be exploited.
Measuring and Managing AI Risks
The MEASURE and MANAGE practices emphasize the need to evaluate AI system security, resilience, and privacy risks continuously. HiddenLayer offers a comprehensive suite of tools for measuring AI risks, including content provenance analysis, security metrics, and privacy risk assessments. By integrating these tools into their operations, organizations can ensure that their AI systems remain secure, reliable, and compliant with industry standards.
Conclusion
NIST's July 2024 guidance underscores the critical importance of robust cybersecurity practices in AI model development and deployment. HiddenLayer and its services are uniquely positioned to help organizations navigate these challenges, offering advanced tools and expertise to manage misuse risks, protect against model theft, and ensure the security and integrity of AI systems. By aligning with NIST's recommendations, we empower organizations to deploy AI responsibly, safeguarding both their intellectual property and the public's trust.

Three Distinct Categories Of AI Red Teaming
As we’ve covered previously, AI red teaming is a highly effective means of assessing and improving the security of AI systems. The term “red teaming” appears many times throughout recent public policy briefings regarding AI.
Introduction
As we’ve covered previously, AI red teaming is a highly effective means of assessing and improving the security of AI systems. The term “red teaming” appears many times throughout recent public policy briefings regarding AI, including:
- Voluntary commitments made by leading AI companies to the US Government
- President Biden’s executive order regarding AI security
- A briefing introducing the UK Government’s AI Safety Institute
- The EU Artificial Intelligence Act
Unfortunately, the term “red teaming” is currently doing triple duty in conversations about security for AI, which can be confusing. In this post, we tease apart these three different types of AI red teaming. Each type plays a crucial but distinct role in improving security for AI. Using precise language is an important step towards building a mature ecosystem of AI red teaming services.
Adversary Simulation: Identifying Vulnerabilities in Deployed AI
It is often highly informative to simulate the tactics, techniques, and procedures of threat actors who target deployed AI systems and seek to make the AI behave in ways it wasn’t intended to behave. This type of red teaming engagement might include efforts to alter (e.g., injecting ransomware into a machine learning model file), bypass (e.g., crafting adversarial examples), and steal the model using a carefully crafted sequence of queries. It could also include attacks specific to LLMs, such as various types of prompt injections and jailbreaking.
This type of red teaming is the most common and widely applicable. In nearly all cases where an organization uses AI for a business critical function, it is wise to perform regular, comprehensive stress testing to minimize the chances that an adversary could compromise the system. Here is an illustrative example of this style of red teaming applied by HiddenLayer to a model used by a client in the financial services industry.
In contrast, the second and third categories of AI red teaming are almost always performed on frontier AI labs and frontier models trained by those labs. By “frontier AI model,” we mean a model with state-of-the-art performance on key capabilities metrics. A “frontier AI lab” is a company that actively works to research, design, train, and deploy frontier AI models. For example, DeepMind is a frontier AI lab, and their current frontier model is the Gemini 1.5 model family.
Model Evaluations: Identifying Dangerous Capabilities in Frontier Models
Given compute budget C, training dataset size T, and number of model parameters P, scaling laws can be used to gain a fairly accurate prediction of the overall level of performance (averaged across a wide variety of tasks) that a large generative model will achieve once it has been trained. On the other hand, the level of performance the model will achieve on any particular task appears to be difficult to predict (although this has been disputed). It would be incredibly useful both for frontier AI labs and for policymakers if there were standardized, accurate, and reliable tests that could be performed to measure specific capabilities in large generative models.
High-quality tests for measuring the degree to which a model possesses dangerous capabilities, such as CBRN (chemical, biological, radiological, and nuclear) and offensive cyber capabilities, are of particular interest. Every time a new frontier model is trained, it would be beneficial to be able to answer the following question: To what extent would white box access to this model increase a bad actor’s ability to do harm at a scale above and beyond what they could do just with access to the internet and textbooks? Regulators have been asking for these tests for months:
- Voluntary AI commitments to the White House
“Commit to internal and external red-teaming of models or systems in areas including misuse, societal risks, and national security concerns, such as bio, cyber, and other safety areas.”
- President Biden’s executive order on AI security
Companies must provide the Federal Government with “the results of any red-team testing that the company has conducted relating to lowering the barrier to entry for the development, acquisition, and use of biological weapons by non-state actors; the discovery of software vulnerabilities and development of associated exploits. . .”
- UK AI Safety Institute
“Dual-use capabilities: As AI systems become more capable, there could be an increased risk that
malicious actors could use these systems as tools to cause harm. Evaluations will gauge the
capabilities most relevant to enabling malicious actors, such as aiding in cyber-criminality,
biological or chemical science, human persuasion, large-scale disinformation campaigns, and
weapons acquisition.”
Frontier AI labs are also investing heavily in the development of internal model evaluations for dangerous capabilities:
“As AI models become more capable, we believe that they will create major economic and social value, but will also present increasingly severe risks. Our RSP focuses on catastrophic risks – those where an AI model directly causes large scale devastation. Such risks can come from deliberate misuse of models (for example use by terrorists or state actors to create bioweapons)...”
“We believe that frontier AI models, which will exceed the capabilities currently present in the most advanced existing models, have the potential to benefit all of humanity. But they also pose increasingly severe risks. Managing the catastrophic risks from frontier AI will require answering questions like: How dangerous are frontier AI systems when put to misuse, both now and in the future? How can we build a robust framework for monitoring, evaluation, prediction, and protection against the dangerous capabilities of frontier AI systems? If our frontier AI model weights were stolen, how might malicious actors choose to leverage them?”
“Identifying capabilities a model may have with potential for severe harm. To do this, we research the paths through which a model could cause severe harm in high-risk domains, and then determine the minimal level of capabilities a model must have to play a role in causing such harm.”
A healthy, truth-seeking debate about the level of risk from misuse of advanced AI will be critical for navigating mitigation measures that are proportional to the risk while not hindering innovation. That being said, here are a few reasons why frontier AI labs and governing bodies are dedicating a lot of attention and resources to dangerous capabilities evaluations for frontier AI:
- Developing a mature science of measurement for frontier model capabilities will likely take a lot of time and many iterations to figure out what works and what doesn’t. Getting this right requires planning ahead so that if and when models with truly dangerous capabilities arrive, we will be well-equipped to detect these capabilities and avoid allowing the model to land in the wrong hands.
- Many desirable AI capabilities fall under the definition of “dual-use,” meaning that they can be leveraged for both constructive and destructive aims. For example, in order to be useful for aiding in cyber threat mitigation, a model must learn to understand computer networking, cyber threats, and computer vulnerabilities. This capability can be put to use by threat actors seeking to attack computer systems.
- Frontier AI labs have already begun to develop dangerous capabilities evaluations for their respective models, and in all cases beginning signs of dangerous capabilities were detected.
- Anthropic: “Taken together, we think that unmitigated LLMs could accelerate a bad actor’s efforts to misuse biology relative to solely having internet access, and enable them to accomplish tasks they could not without an LLM. These two effects are likely small today, but growing relatively fast. If unmitigated, we worry that these kinds of risks are near-term, meaning that they may be actualized in the next two to three years, rather than five or more.”
- OpenAI: “Overall, especially given the uncertainty here, our results indicate a clear and urgent need for more work in this domain. Given the current pace of progress in frontier AI systems, it seems possible that future systems could provide sizable benefits to malicious actors. It is thus vital that we build an extensive set of high-quality evaluations for biorisk (as well as other catastrophic risks), advance discussion on what constitutes ‘meaningful’ risk, and develop effective strategies for mitigating risk.”
- DeepMind: “More broadly, the stronger models exhibited at least rudimentary abilities across all our evaluations, hinting that dangerous capabilities may emerge as a byproduct of improvements in general capabilities. . . We commissioned a group of professional forecasters to predict when models will first obtain high scores on our evaluations, and their median estimates were between 2025 and 2029 for different capabilities.”
NIST recently published a draft of a report on mitigating risks from the misuse of foundation models. They emphasize two key properties that model evaluations should have: (1) Threat actors will almost certainly expand the level of capabilities of a frontier model by giving it access to various tools such as a Python interpreter, an Internet search engine, and a command prompt. Therefore, models should be given access to the best tools available during the evaluation period. Even if a model by itself can’t complete a task that would be indicative of dangerous capabilities, that same model with access to tools may be more than capable. (2) The evaluations must not be leaked into the model’s training data, or else the dangerous capabilities of the model could be overestimated.
Adversary Simulation: Stealing Frontier Model Weights
Whereas the first two types of AI red teaming are relatively new (especially model evaluations), the third type involves applying tried and true network, human, and physical red teaming to the information security controls put in place by frontier AI labs to safeguard frontier model weights. Frontier AI labs are thinking hard about how to prevent model weight theft:
“Harden security such that non-state attackers are unlikely to be able to steal model weights and advanced threat actors (e.g., states) cannot steal them without significant expense.”
“Here, we outline our current architecture and operations that support the secure training of frontier models at scale. This includes measures designed to protect sensitive model weights within a secure environment for AI innovation.”
“To allow us to tailor the strength of the mitigations to each [Critical Capability Level], we have also outlined a set of security and deployment mitigations. Higher level security mitigations result in greater protection against the exfiltration of model weights…”
What are model weights, and why are frontier labs so keen on preventing them from being stolen? Model weights are simply numbers that encode the entirety of what was learned during the training process. To “train” a machine learning model is to iteratively tune the values of the model’s weights such that the model performs better and better on the training task.
Frontier models have a tremendous number of weights (for example, GPT-3 has approximately 175 billion weights), and more weights require more time and money to learn. If an adversary were to steal the files containing the weights of a frontier AI model (either through traditional cyber threat operations, social engineering of employees, or gaining physical access to a frontier lab’s computing infrastructure), that would amount to intellectual property theft of tens or even hundreds of millions of dollars.
Additionally, recall that Anthropic, OpenAI, DeepMind, the White House, and the UK AI Safety Institute, among many others, believe it is plausible that scaling up frontier generative models could create both incredibly helpful and destructive capabilities. Ensuring that model weights stay on secure servers closes off one of the major routes by which a bad actor could unlock the full offensive capabilities of these future models. The effects of safety fine-tuning techniques such as reinforcement learning from human feedback (RLHF) and Constitutional AI are encoded in the model’s weights and put up a barrier against asking the stolen model to aid in harming. But this barrier is flimsy in the face of techniques such as LoRA and directional ablation that can be used to quickly, cheaply, and surgically remove these safeguards. A threat actor with access to a model’s weights is a threat actor with full access to any and all offensive capabilities the model may have learned during training.
A recent report from RAND takes a deep dive into this particular threat model and lays out what it might take to prevent even highly resourced and cyber-capable state actors from stealing frontier model weights. The term “red-team” appears 26 times in the report. To protect their model weights, “OpenAI uses internal and external red teams to simulate adversaries and test our security controls for the research environment.”
Note the synergy between the second and third types of AI red teaming. A mature science of model evaluations for dangerous capabilities would allow policymakers and frontier labs to make more informed decisions about what level of public access is proportional to the risks posed by a given model, as well as what intensity of red teaming is necessary to ensure that the model’s weights remain secure. If we can’t know with a high degree of confidence what a model is capable of, we run the risk of locking down a model that turns out to have no dangerous capabilities and forfeiting the scientific benefits of allowing at least somewhat open access to that model, including valuable research on making AI more secure that is enabled by white-box access to frontier models. The other, much more sinister side of the coin is that we could put up too few controls around the weights of a model that we erroneously believe to possess no dangerous capabilities, only to later have the previously latent offensive firepower of that model aimed at us by a threat actor.
Conclusion
As frontier labs and policy makers have been correct in emphasizing, AI red teaming is one of the most powerful tools at our disposal for enhancing the security of AI systems. However, the language currently used in these conversations obscures the fact that AI red teaming is not just a single approach; rather, it involves three distinct strategies, each addressing different security needs.:
- Simulating adversaries who seek to alter, bypass, or steal (through inference-based attacks) a model deployed in a business-critical context is an invaluable method of discovering and remediating vulnerabilities. AI red teaming, especially when tailored to large language models (LLM red teaming), provides a focused approach to identifying potential weaknesses and developing strategies to safeguard these systems against misuse and exploitation.
- Advancing the science of measuring dangerous capabilities in frontier AI models is critical for policy makers and frontier AI labs who seek to apply regulations and security controls that are proportional to the risks from misuse posed by a given model.
- Traditional network, human, and physical red teaming with the objective of stealing frontier model weights from frontier AI labs is an indispensable tool for assessing the readiness of frontier labs to prevent bad actors from taking and abusing their most powerful dual-use models.
Contact us here to start a conversation about AI red teaming for your organization.

Understand AI Security, Clearly Defined
Explore our glossary to get clear, practical definitions of the terms shaping AI security, governance, and risk management.