Learn from our AI Security Experts
Discover every model. Secure every workflow. Prevent AI attacks - without slowing innovation.


min read
Integrating HiddenLayer’s Model Scanner with Databricks Unity Catalog
As machine learning becomes more embedded in enterprise workflows, model security is no longer optional. From training to deployment, organizations need a streamlined way to detect and respond to threats that might lurk inside their models. The integration between HiddenLayer’s Model Scanner and Databricks Unity Catalog provides an automated, frictionless way to monitor models for vulnerabilities as soon as they are registered. This approach ensures continuous protection without slowing down your teams.
Introduction
As machine learning becomes more embedded in enterprise workflows, model security is no longer optional. From training to deployment, organizations need a streamlined way to detect and respond to threats that might lurk inside their models. The integration between HiddenLayer’s Model Scanner and Databricks Unity Catalog provides an automated, frictionless way to monitor models for vulnerabilities as soon as they are registered. This approach ensures continuous protection without slowing down your teams.
In this blog, we’ll walk through how this integration works, how to set it up in your Databricks environment, and how it fits naturally into your existing machine learning workflows.
Why You Need Automated Model Security
Modern machine learning models are valuable assets. They also present new opportunities for attackers. Whether you are deploying in finance, healthcare, or any data-intensive industry, models can be compromised with embedded threats or exploited during runtime. In many organizations, models move quickly from development to production, often with limited or no security inspection.
This challenge is addressed through HiddenLayer’s integration with Unity Catalog, which automatically scans every new model version as it is registered. The process is fully embedded into your workflow, so data scientists can continue building and registering models as usual. This ensures consistent coverage across the entire lifecycle without requiring process changes or manual security reviews.
This means data scientists can focus on training and refining models without having to manually initiate security checks or worry about vulnerabilities slipping through the cracks. Security engineers benefit from automated scans that are run in the background, ensuring that any issues are detected early, all while maintaining the efficiency and speed of the machine learning development process. HiddenLayer’s integration with Unity Catalog makes model security an integral part of the workflow, reducing the overhead for teams and helping them maintain a safe, reliable model registry without added complexity or disruption.
Getting Started: How the Integration Works
To install the integration, contact your HiddenLayer representative to obtain a license and access the installer. Once you’ve downloaded and unzipped the installer for your operating system, you’ll be guided through the deployment process and prompted to enter environment variables.
Once installed, this integration monitors your Unity Catalog for new model versions and automatically sends them to HiddenLayer’s Model Scanner for analysis. Scan results are recorded directly in Unity Catalog and the HiddenLayer console, allowing both security and data science teams to access the information quickly and efficiently.
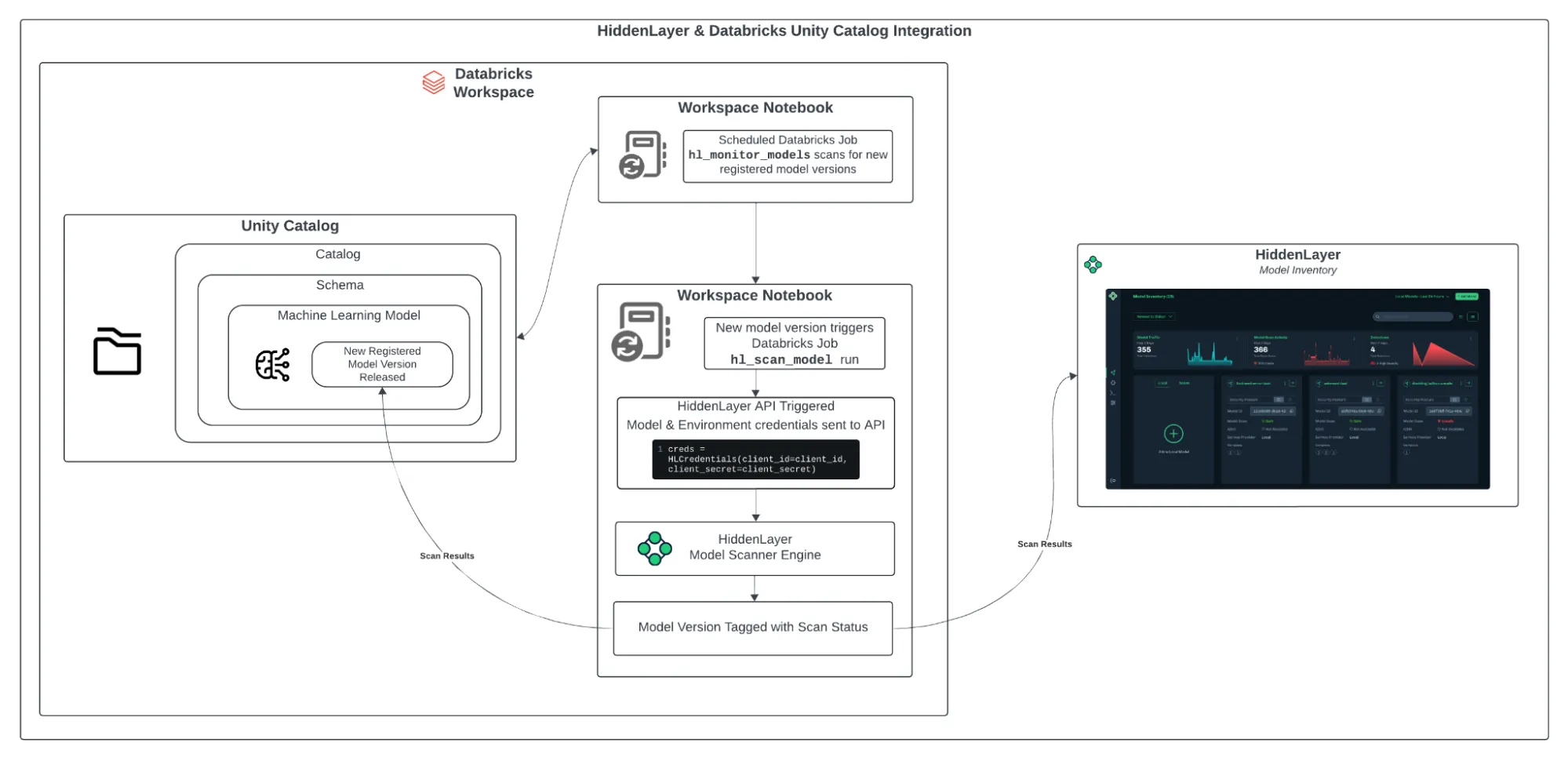
Figure 1: HiddenLayer & Databricks Architecture Diagram
The integration is simple to set up and operates smoothly within your Databricks workspace. Here’s how it works:
- Install the HiddenLayer CLI: The first step is to install the HiddenLayer CLI on your system. Running this installation will set up the necessary Python notebooks in your Databricks workspace, where the HiddenLayer Model Scanner will run.
- Configure the Unity Catalog Schema: During the installation, you will specify the catalogs and schemas that will be used for model scanning. Once configured, the integration will automatically scan new versions of models registered in those schemas.
- Automated Scanning: A monitoring notebook called hl_monitor_models runs on a scheduled basis. It checks for newly registered model versions in the configured schemas. If a new version is found, another notebook, hl_scan_model, sends the model to HiddenLayer for scanning.
- Reviewing Scan Results After scanning, the results are added to Unity Catalog as model tags. These tags include the scan status (pending, done, or failed) and a threat level (safe, low, medium, high, or critical). The full detection report is also accessible in the HiddenLayer Console. This allows teams to evaluate risk without needing to switch between systems.
Why This Workflow Works
This integration helps your team stay secure while maintaining the speed and flexibility of modern machine learning development.
- No Process Changes for Data Scientists
Teams continue working as usual. Model security is handled in the background. - Real-Time Security Coverage
Every new model version is scanned automatically, providing continuous protection. - Centralized Visibility
Scan results are stored directly in Unity Catalog and attached to each model version, making them easy to access, track, and audit. - Seamless CI/CD Compatibility
The system aligns with existing automation and governance workflows.
Final Thoughts
Model security should be a core part of your machine learning operations. By integrating HiddenLayer’s Model Scanner with Databricks Unity Catalog, you gain a secure, automated process that protects your models from potential threats.
This approach improves governance, reduces risk, and allows your data science teams to keep working without interruptions. Whether you’re new to HiddenLayer or already a user, this integration with Databricks Unity Catalog is a valuable addition to your machine learning pipeline. Get started today and enhance the security of your ML models with ease.
All Resources


RSAC 2025 Takeaways
RSA Conference 2025 may be over, but conversations are still echoing about what’s possible with AI and what’s at risk. This year’s theme, “Many Voices. One Community,” reflected the growing understanding that AI security isn’t a challenge one company or sector can solve alone. It takes shared responsibility, diverse perspectives, and purposeful collaboration.
RSA Conference 2025 may be over, but conversations are still echoing about what’s possible with AI and what’s at risk. This year’s theme, “Many Voices. One Community,” reflected the growing understanding that AI security isn’t a challenge one company or sector can solve alone. It takes shared responsibility, diverse perspectives, and purposeful collaboration.
After a week of keynotes, packed sessions, analyst briefings, the Security for AI Council breakfast, and countless hallway conversations, our team returned with a renewed sense of purpose and validation. Protecting AI requires more than tools. It requires context, connection, and a collective commitment to defending innovation at the speed it’s moving.
Below are five key takeaways that stood out to us, informed by our CISO Malcolm Harkins’ reflections and our shared experience at the conference
1. Agentic AI is the Next Big Challenge
Agentic AI was everywhere this year, from keynotes to vendor booths to panel debates. These systems, capable of taking autonomous actions on behalf of users, are being touted as the next leap in productivity and defense. But they also raise critical concerns: What if an agent misinterprets intent? How do we control systems that can act independently? Conversations throughout RSAC highlighted the urgent need for transparency, oversight, and clear guardrails before agentic systems go mainstream.
While some vendors positioned agents as the key to boosting organizational defense, others voiced concerns about their potential to become unpredictable or exploitable. We’re entering a new era of capability, and the security community is rightfully approaching it with a mix of optimism and caution.
2. Security for AI Begins with Context
During the Security for AI Council breakfast, CISOs from across industries emphasized that context is no longer optional, but foundational. It’s not just about tracking inputs and outputs, but understanding how a model behaves over time, how users interact with it, and how misuse might manifest in subtle ways. More data can be helpful, but it’s the right data, interpreted in context, that enables faster, smarter defense.
As AI systems grow more complex, so must our understanding of their behaviors in the wild. This was a clear theme in our conversations, and one that HiddenLayer is helping to address head-on.
3. AI’s Expanding Role: Defender, Adversary, and Target
This year, AI wasn’t a side topic but the centerpiece. As our CISO, Malcolm Harkins, noted, discussions across the conference explored AI’s evolving role in the cyber landscape:
- Defensive applications: AI is being used to enhance threat detection, automate responses, and manage vulnerabilities at scale.
- Offensive threats: Adversaries are now leveraging AI to craft more sophisticated phishing attacks, automate malware creation, and manipulate content at a scale that was previously impossible.
- AI itself as a target: Like many technology shifts before it, security has often lagged deployment. While the “risk gap”, the time between innovation and protection, may be narrowing thanks to proactive solutions like HiddenLayer, the fact remains: many AI systems are still insecure by default.
AI is no longer just a tool to protect infrastructure. It is the infrastructure, and it must be secured as such. While the gap between AI adoption and security readiness is narrowing, thanks in part to proactive solutions like HiddenLayer’s, there’s still work to do.
4. We Can’t Rely on Foundational Model Providers Alone
In analyst briefings and expert panels, one concern repeatedly came up: we cannot place the responsibility of safety entirely on foundational model providers. While some are taking meaningful steps toward responsible AI, others are moving faster than regulation or safety mechanisms can keep up.
The global regulatory environment is still fractured, and too many organizations are relying on vendors’ claims without applying additional scrutiny. As Malcolm shared, this is a familiar pattern from previous tech waves, but in the case of AI, the stakes are higher. Trust in these systems must be earned, and that means building in oversight and layered defense strategies that go beyond the model provider. Current research, such as Universal Bypass, demonstrates this.
5. Legacy Themes Remain, But AI Has Changed the Game
RSAC 2025 also brought a familiar rhythm, emphasis on identity, Zero Trust architectures, and public-private collaboration. These aren’t new topics, but they continue to evolve. The security community has spent over a decade refining identity-centric models and pushing for continuous verification to reduce insider risk and unauthorized access.
For over twenty years, the push for deeper cooperation between government and industry has been constant. This year, that spirit of collaboration was as strong as ever, with renewed calls for information sharing and joint defense strategies.
What’s different now is the urgency. AI has accelerated both the scale and speed of potential threats, and the community knows it. That urgency has moved these longstanding conversations from strategic goals to operational imperatives.
Looking Ahead
The pace of innovation on the expo floor was undeniable. But what stood out even more were the authentic conversations between researchers, defenders, policymakers, and practitioners. These moments remind us what cybersecurity is really about: protecting people.
That’s why we’re here, and that’s why HiddenLayer exists. AI is changing everything, from how we work to how we secure. But with the right insights, the right partnerships, and a shared commitment to responsibility, we can stay ahead of the risk and make space for all the good AI can bring.
RSAC 2025 reminded us that AI security is about more than innovation. It’s about accountability, clarity, and trust. And while the challenges ahead are complex, the community around them has never been stronger.
Together, we’re not just reacting to the future.
We’re helping to shape it.
Universal Bypass Discovery: Why AI Systems Everywhere Are at Risk
HiddenLayer researchers have developed the first single, universal prompt injection technique, post-instruction hierarchy, that successfully bypasses safety guardrails across nearly all major frontier AI models. This includes models from OpenAI (GPT-4o, GPT-4o-mini, and even the newly announced GPT-4.1), Google (Gemini 1.5, 2.0, and 2.5), Microsoft (Copilot), Anthropic (Claude 3.7 and 3.5), Meta (Llama 3 and 4 families), DeepSeek (V3, R1), Qwen (2.5 72B), and Mixtral (8x22B).
HiddenLayer researchers have developed the first single, universal prompt injection technique, post-instruction hierarchy, that successfully bypasses safety guardrails across nearly all major frontier AI models. This includes models from OpenAI (GPT-4o, GPT-4o-mini, and even the newly announced GPT-4.1), Google (Gemini 1.5, 2.0, and 2.5), Microsoft (Copilot), Anthropic (Claude 3.7 and 3.5), Meta (Llama 3 and 4 families), DeepSeek (V3, R1), Qwen (2.5 72B), and Mixtral (8x22B).
The technique, dubbed Prompt Puppetry, leverages a novel combination of roleplay and internally developed policy techniques to circumvent model alignment, producing outputs that violate safety policies, including detailed instructions on CBRN threats, mass violence, and system prompt leakage. The technique is not model-specific and appears transferable across architectures and alignment approaches.
The research provides technical details on the bypass methodology, real-world implications for AI safety and risk management, and the importance of proactive security testing, especially for organizations deploying or integrating LLMs in sensitive environments.
Threat actors now have a point-and-shoot approach that works against any underlying model, even if they do not know what it is. Anyone with a keyboard can now ask how to enrich uranium, create anthrax, or otherwise have complete control over any model. This threat shows that LLMs cannot truly self-monitor for dangerous content and reinforces the need for additional security tools.

Is it Patchable?
It would be extremely difficult for AI developers to properly mitigate this issue. That’s because the vulnerability is rooted deep in the model’s training data, and isn’t as easy to fix as a simple code flaw. Developers typically have two unappealing options:
- Re-tune the model with additional reinforcement learning (RLHF) in an attempt to suppress this specific behavior. However, this often results in a “whack-a-mole” effect. Suppressing one trick just opens the door for another and can unintentionally degrade model performance on legitimate tasks.
- Try to filter out this kind of data from training sets, which has proven infeasible for other types of undesirable content. These filtering efforts are rarely comprehensive, and similar behaviors often persist.
That’s why external monitoring and response systems like HiddenLayer’s AISec Platform are critical. Our solution doesn’t rely on retraining or patching the model itself. Instead, it continuously monitors for signs of malicious input manipulation or suspicious model behavior, enabling rapid detection and response even as attacker techniques evolve.
Impacting All Industries
In domains like healthcare, this could result in chatbot assistants providing medical advice that they shouldn’t, exposing private patient data, or invoking medical agent functionality that shouldn’t be exposed.
In finance, AI analysis of investment documentation or public data sources like social media could result in incorrect financial advice or transactions that shouldn’t be approved as well as utilize chatbots to expose sensitive customer financial data & PII.
In manufacturing, the greatest fear isn’t always a cyberattack but downtime. Every minute of halted production directly impacts output, reduces revenue, and can drive up product costs. AI is increasingly being adopted to optimize manufacturing output and reduce those costs. However, if those AI models are compromised or produce inaccurate outputs, the result could be significant: lost yield, increased operational costs, or even the exposure of proprietary designs or process IP.
Increasingly, airlines are utilizing AI to improve maintenance and provide crucial guidance to mechanics to ensure maximized safety. If compromised, and misinformation is provided, faulty maintenance could occur, jeopardizing
public safety.
In all industries, this could result in embarrassing customer chatbot discussions about competitors, transcripts of customer service chatbots acting with harm toward protected classes, or even misappropriation of public-facing AI systems to further CBRN (Chemical, Biological, Radiological, and Nuclear), mass violence, and self-harm.
AI Security has Arrived
Inside HiddenLayer’s AISec Platform and AIDR: The Defense System AI Has Been Waiting For
While model developers scramble to contain vulnerabilities at the root of LLMs, the threat landscape continues to evolve at breakneck speed. The discovery of Prompt Puppetry proves a sobering truth: alignment alone isn’t enough. Guardrails can be jumped. Policies can be ignored. HiddenLayer’s AISec Platform, powered by AIDR—AI Detection & Response—was built for this moment, offering intelligent, continuous oversight that detects prompt injections, jailbreaks, model evasion techniques, and anomalous behavior before it causes harm. In highly regulated sectors like finance and healthcare, a single successful injection could lead to catastrophic consequences, from leaked sensitive data to compromised model outputs. That’s why industry leaders are adopting HiddenLayer as a core component of their security stack, ensuring their AI systems stay secure, monitored, and resilient.
Request a demo with HiddenLayer to learn more

How To Secure Agentic AI
Artificial Intelligence is entering a new chapter defined not just by generating content but by taking independent, goal-driven action. This evolution is called agentic AI. These systems don’t simply respond to prompts; they reason, make decisions, contact tools, and carry out tasks across systems, all with limited human oversight. In short, they are the architects of their own workflows.
Artificial Intelligence is entering a new chapter defined not just by generating content but by taking independent, goal-driven action. This evolution is called agentic AI. These systems don’t simply respond to prompts; they reason, make decisions, contact tools, and carry out tasks across systems, all with limited human oversight. In short, they are the architects of their own workflows.
But with autonomy comes complexity and risk. Agentic AI creates an expanded attack surface that traditional cybersecurity tools weren’t designed to defend.
That’s where AI Detection & Response (AIDR) comes in.
Built by HiddenLayer, AIDR is a purpose-built platform for securing AI in all its forms, including agentic systems. It offers real-time defense, complete visibility, and deep control over the agentic execution stack, enabling enterprises to adopt autonomous AI safely.
What Makes Agentic AI Different?
To understand why traditional security falls short, you have to understand what makes agentic AI fundamentally different.
While conventional generative AI systems produce single outputs from prompts, agentic AI goes several steps further. These systems reason through multi-step tasks, plan over time, access APIs and tools, and even collaborate with other agents. Often, they make decisions that impact real systems and sensitive data, all without immediate oversight.
The critical difference? In agentic systems, the large language model (LLM) generates content but also drives logic and execution.
This evolution introduces:
- Autonomous Execution Paths: Agents determine their own next steps and iterate as they go.
- Deep API & Tool Integration: Agents directly interact with systems through code, not just natural language.
- Stateful Memory: Memory enhances task continuity but also increases the attack surface.
- Multi-Agent Collaboration: Coordinated behavior raises the risk of lateral compromise and cascading failures.
The result is a fundamentally new class of software: intelligent, autonomous, and deeply embedded in business operations.
Security Challenges in Agentic AI
Agentic AI’s strengths are also its vulnerabilities. Designed for independence, these systems can be manipulated without proper controls.
The risks include:
- Indirect Prompt Injection — A technique where attackers embed hidden or harmful instructions external content to manipulate an agent’s behavior or bypass its guardrails.
- PII Leakage — The unintended exposure of sensitive or personally identifiable information during an agent’s interactions or task execution.
- Model Tampering — The use of carefully crafted inputs to exploit vulnerabilities in the model, leading to skewed outputs or erratic behavior.
- Data Poisoning / Model Injection — The deliberate introduction of misleading or harmful data into training or feedback loops, altering how the agent learns or responds.
- Model Extraction / Theft — An attack that uses repeated queries to reverse-engineer an AI model, allowing adversaries to replicate its logic or steal intellectual property.
How AIDR Protects Agentic AI
HiddenLayer’s AI Detection and Response (AIDR) was designed to secure AI systems in production. Unlike traditional tools that focus only on input/output, AIDR monitors intent, behavior, and system-level interactions. It’s built to understand what agents are doing, how they’re doing it, and whether they’re staying aligned with their objectives.
Core protection capabilities include:
- Agent Activity Monitoring: Monitors and logs agent behavior to detect anomalies during execution.
- Sensitive Data Protection: Detects and blocks the unintended leakage of PII or confidential information in outputs.
- Knowledge Base Protection: Detects prompt injections in data accessed by agents to maintain source integrity.
Together, these layers give security teams peace of mind, ensuring autonomous agents remain aligned, even when operating independently.
Built for Modern Enterprise Platforms
AIDR protects real-world deployments across today’s most advanced agentic platforms:
- OpenAI Agent SDK.
- Custom agents using LangChain, MCP, AutoGen, LangGraph, n8n and more.
- Low-Friction Setup: Works across cloud, hybrid, and on-prem environments.
Each integration is designed for platform-specific workflows, permission models, and agent behaviors, ensuring precise, contextual protection.
Adapting to Evolving Threats
HiddenLayer’s AIDR platform evolves alongside new and emerging threats with input from:
- Threat Intelligence from HiddenLayer’s Synaptic Adversarial Intelligence (SAI) Team
- Behavioral Detection Models to surface intent-based risks
- Customer Feedback Loops for rapid tuning and responsiveness
This means defenses will keep up as agents grow more powerful and more complex.
Why Securing Agentic AI Matters
Agentic AI can transform your business, but only if it’s secure. With AI Detection and Response, organizations can:
- Accelerate adoption by removing security barriers
- Prevent data loss, misuse, or rogue automation
- Stay compliant with emerging AI regulations
- Protect brand trust by avoiding catastrophic failures
- Reduce manual oversight with automated safeguards
The Road Ahead
Agentic AI is already reshaping enterprise operations. From development pipelines to customer experience, agents are becoming key players in the modern digital stack.
The opportunity is massive, and so is the responsibility. AIDR ensures your agentic AI systems operate with visibility, control, and trust. It’s how we secure the age of autonomy.
At HiddenLayer, we’re securing the age of agency. Let’s build responsibly.
Want to see how AIDR secures Agentic AI? Schedule a demo here.

What’s New in AI
The past year brought significant advancements in AI across multiple domains, including multimodal models, retrieval-augmented generation (RAG), humanoid robotics, and agentic AI.
The past year brought significant advancements in AI across multiple domains, including multimodal models, retrieval-augmented generation (RAG), humanoid robotics, and agentic AI.
Multimodal models
Multimodal models became popular with the launch of OpenAI’s GPT-4o. What makes a model “multimodal” is its ability to create multimedia content (images, audio, and video) in response to text- or audio-based prompts, or vice versa, respond with text or audio to multimedia content uploaded to a prompt. For example, a multimodal model can process and translate a photo of a foreign language menu. This capability makes it incredibly versatile and user-friendly. Equally, multimodality has seen advancement toward facilitating real-time, natural conversations.
While GPT-4o might be one of the most used multimodal models, it's certainly not singular. Other well-known multimodal models include KOSMOS and LLaVA from Microsoft, Gemini 2.0 from Google, Chameleon from Meta, and Claude 3 from Anthopic.
Retrieval-Augmented Generation
Another hot topic in AI is a technique called Retrieval-Augmented Generation (RAG). Although first proposed in 2020, it has gained significant recognition in the past year and is being rapidly implemented across industries. RAG combines large language models (LLMs) with external knowledge retrieval to produce accurate and contextually relevant responses. By having access to a trusted database containing the latest and most relevant information not included in the static training data, an LLM can produce more up-to-date responses less prone to hallucinations. Moreover, using RAG facilitates the creation of highly tailored domain-specific queries and real-time adaptability.
In September 2024, we saw the release of Oracle Cloud Infrastructure GenAI Agents - a platform that combines LLMs and RAG. In January 2025, a service that helps to streamline the information retrieval process and feed it to an LLM, called Vertex AI RAG Engine, was unveiled by Google.
Humanoid robots
The concept of humanoid machines can be traced as far back as ancient mythologies of Greece, Egypt, and China. However, the technology to build a fully functional humanoid robot has not matured sufficiently - until now. Rapid advancements in natural language have expedited machines’ ability to perform a wide range of tasks while offering near-human interactions.
Tesla's Optimus and Agility Robotics' Digit robot are at the forefront of these advancements. Optimus unveiled its second generation in December 2023, featuring significant improvements over its predecessor, including faster movement, reduced weight, and sensor-embedded fingers. Digit’s has a longer history, releasing and deploying it’s fifth version in June 2024 for use at large manufacturing factories.
Advancements in LLM technology are new driving factors for the field of robotics. In December 2023, researchers unveiled a humanoid robot called Alter3, which leverages GPT-4. Besides being used for communication, the LLM enables the robot to generate spontaneous movements based on linguistic prompts. Thanks to this integration, Alter3 can perform actions like adopting specific poses or sequences without explicit programming, demonstrating the capability to recognize new concepts without labeled examples.
Agentic AI
Agentic AI is the natural next step in AI development that will vastly enhance the way in which we use and interact with AI. Traditional AI bots heavily rely on pre-programmed rules and, therefore, have limited scope for independent decision-making. The goal of agentic AI is to construct assistants that would be unprecedentedly autonomous, make decisions without human feedback, and perform tasks without requiring intervention. Unlike GenAI, whose main functionality is generating content in response to user prompts, agentic assistants are focused on optimizing specific goals and objectives - and do so independently. This can be achieved by assembling a complex network of specialized models (“agents”), each with a particular role and task, as well as access to memory and external tools. This technology has incredible promise across many sectors, from manufacturing to health to sales support and customer service, and is being trialed and tested for live implementation.
Google has been investing heavily over the past year in the development of agentic models, and the new version of their flagship generative AI, Gemini 2.0, is specially designed to help build AI agents. Moreover, OpenAI released a research preview of their first autonomous agentic AI tool called Operator. Operator is an agent able to perform a range of different tasks on the website independently, and it can be used to automate various browser related activities, such as placing online orders and filling out online forms.
We’re already seeing Agentic AI turbocharged with the integration of multimodal models into agentic robotics and the concept of agentic RAG. Combining the advancements of these technologies, the future of powerful and complex autonomous solutions will soon transcend imagination into reality.
The Rise of Open-weight Models
Open-weight models are models whose weights (i.e., the output of the model training process) are made available to the broader public. This allows users to implement the model locally, adapt it, and fine-tune it without the constraints of a proprietary model. Traditionally, open-weight models were scoring lower against leading proprietary models in AI performance benchmarking. This is because training a large GenAI solution requires tremendous computing power and is, therefore, incredibly expensive. The biggest players on the market, who are able to afford to train a high-quality GenAI, usually keep their models ringfenced and only allow access to the inference API. The recent release of an open-weight DeepSeek-R1 model might be on course to disrupt this trend.
In January 2025, a Chinese AI lab called DeepSeek released several open-weight foundation models that performed comparably in reasoning performance to top close-weight models from OpenAI. DeepSeek claims the cost of training the models was only $6M, which is significantly lower than average. Moreover, reviewing the pricing of DeepSeek-R1 API against the popular OpenAI-o1 API shows the DeepSeek model is approximately 27x cheaper than o1 to operate, making it a very tempting option for a cost-conscious developer.
DeepSeek models might look like a breakthrough in AI training and deployment costs; however, upon a closer look, these models are ridden with problems, from insufficient safety guardrails, to insecure loading, to embedded bias and data privacy concerns.
As frontier-level open-weight models are likely to proliferate, deploying such models should be done with utmost caution. Models released by untrusted entities might contain security flaws, biases, and hidden backdoors and should be carefully evaluated prior to local deployment. People choosing to use hosted solutions should also be acutely aware of privacy issues concerning the prompts they send to these models.

Securing Agentic AI: A Beginner's Guide
The rise of generative AI has unlocked new possibilities across industries, and among the most promising developments is the emergence of agentic AI. Unlike traditional AI systems that respond to isolated prompts, agentic AI systems can plan, reason, and take autonomous action to achieve complex goals.
Introduction
The rise of generative AI has unlocked new possibilities across industries, and among the most promising developments is the emergence of agentic AI. Unlike traditional AI systems that respond to isolated prompts, agentic AI systems can plan, reason, and take autonomous action to achieve complex goals.
In a recent webinar poll conducted by Gartner in January 2025, 64% of respondents indicated that they plan to pursue agentic AI initiatives within the next year. But what exactly is agentic AI? How does it work? And what should organizations consider when deploying these systems, especially from a security standpoint?
As the term agentic AI becomes more widely used, it’s important to distinguish between two emerging categories of agents. On one side, there are “computer use” agents, such as OpenAI’s Operator or Claude’s Computer Use, designed to navigate desktop environments like a human, using interfaces like keyboards and screen inputs. These systems often mimic human behavior to complete general-purpose tasks and may introduce new risks from indirect prompt injections or as a form of shadow AI. On the other side are business logic or application-specific agents, such as Copilot agents or n8n flows, which are built to interact with predefined APIs or systems under enterprise governance. This blog primarily focuses on the second category: enterprise-integrated agentic systems, where security and oversight are essential to safe deployment.
This beginner’s guide breaks down the foundational concepts behind agentic AI and provides practical advice for safe and secure adoption.
What Is Agentic AI?
Agentic AI refers to artificial intelligence systems that demonstrate agency — the ability to autonomously pursue goals by making decisions, executing actions, and adapting based on feedback. These systems extend the capabilities of large language models (LLMs) by adding memory, tool access, and task management, allowing them to operate more like intelligent agents than simple chatbots.
Essentially, agentic AI is about transforming LLMs into AI agents that can proactively solve problems, take initiative, and interact with their environment.
Key Capabilities of Agentic AI Systems:
- Autonomy: Operate independently without constant human input.
- Goal Orientation: Pursue high-level objectives through multiple steps.
- Tool Use: Invoke APIs, search engines, file systems, and even other models.
- Memory and Reflection: Retain and use information from past interactions to improve performance.
These core features enable agentic systems to execute complex, multi-step tasks across time, which is a major advancement in the evolution of AI.
How Does Agentic AI Work?
Most agentic AI systems are built on top of LLMs like GPT, Claude, or Gemini, using orchestration frameworks such as LangChain, AutoGen, or OpenAI’s Agents SDK. These frameworks enable developers to:
- Define tasks and goals
- Integrate external tools (e.g., databases, search, code interpreters)
- Store and manage memory
- Create feedback loops for iterative reasoning (plan → act → evaluate → repeat)
For example, consider an AI agent tasked with planning a vacation. Instead of simply answering “Where should I go in April?”, an agentic system might:
- Research destinations with favorable weather
- Check flight and hotel availability
- Compare options based on budget and preferences
- Build a full itinerary
- Offer to book the trip for you
This step-by-step reasoning and execution illustrates the agent’s ability to handle complex objectives with minimal oversight while utilizing various tools.
Real-World Use Cases of Agentic AI
Agentic AI is being adopted across sectors to streamline operations, enhance decision-making, and reduce manual overhead:
- Finance: AI agents generate real-time reports, detect fraud, and support compliance reviews.
- Cybersecurity: Agentic systems help triage threats, monitor activity, and flag anomalies.
- Customer Service: Virtual agents resolve multi-step tickets autonomously, improving response times.
- Healthcare: AI agents assist with literature reviews and decision support in diagnostics.
- DevOps: Code review bots and system monitoring agents help reduce downtime and catch bugs earlier.
The ability to chain tasks and interact with tools makes agentic AI highly adaptable across industries.
The Security Risks of Agentic AI
With greater autonomy comes a larger attack surface. According to a recent Gartner study, over 50% of successful cybersecurity attacks against AI agents will exploit access control issues in the coming year, using direct or indirect prompt injection as an attack vector. This being said, agentic AI systems introduce unique risks that organizations must address early:
- Prompt Injection: Malicious inputs can hijack the agent’s instructions or logic.
- Tool Misuse: Unrestricted access to external tools may result in unintended or harmful actions.
- Memory Poisoning: False or manipulated data stored in memory can influence future decisions.
- Goal Misalignment: Poorly defined goals can lead agents to optimize for unsafe or undesirable outcomes.
As these intelligent agents grow in complexity and capability, their security must evolve just as quickly.
Best Practices for Building Secure Agentic AI
Getting started with agentic AI doesn't have to be risky. If you implement foundational safeguards. Here are five essential best practices:
- Start Simple: Limit the agent’s scope by restricting tasks, tools, and memory to reduce complexity.
- Implement Guardrails: Define strict constraints on the agent’s tool access and behavior. For example, HiddenLayers AIDR can provide this capability today by identifying and responding to tool usage.
- Log Everything: Record all actions and decisions for observability, auditing, and debugging.
- Validate Inputs and Outputs: Regularly verify that the agent is functioning as intended.
- Red Team Your Agents: Simulate adversarial attacks to uncover vulnerabilities and improve resilience.
By embedding security at the foundation, you’ll be better prepared to scale agentic AI safely and responsibly.
Final Thoughts
Agentic AI marks a major step forward in artificial intelligence's capabilities, bringing us closer to systems that can reason, act, and adapt like human collaborators. But these advancements come with real-world risks that demand attention.
Whether you're building your first AI agent or integrating agentic AI into your enterprise architecture, it’s critical to balance innovation with holistic security practices.
At HiddenLayer, the future of agentic AI can be both powerful and protected. If you're looking to explore how you can secure your agentic AI adoption, contact our team to book a demo.

AI Red Teaming Best Practices
Organizations deploying AI must ensure resilience against adversarial attacks before models go live. This blog covers best practices for <a href="https://hiddenlayer.com/innovation-hub/a-guide-to-ai-red-teaming/">AI red teaming, drawing on industry frameworks and insights from real-world engagements by HiddenLayer’s Professional Services team.
Summary
Organizations deploying AI must ensure resilience against adversarial attacks before models go live. This blog covers best practices for AI red teaming, drawing on industry frameworks and insights from real-world engagements by HiddenLayer’s Professional Services team.
Framework & Considerations for Gen AI Red Teaming
OWASP is a leader in standardizing AI red teaming. Resources like the OWASP Top 10 for Large Language Models (LLMs) and the recently released GenAI Red Teaming Guide provide critical insights into how adversaries may target AI systems and offer helpful guidance for security leaders.
HiddenLayer has been a proud contributor to this work, partnering with OWASP’s Top 10 for LLM Applications and supporting community-driven security standards for GenAI.
The OWASP Top 10 for Large Language Model Applications has undergone multiple revisions, with the most recent version released earlier this year. This document outlines common threats to LLM applications, such as Prompt Injection and Sensitive Information Disclosure, which help shape the objectives of a red team engagement.
Complementing this, OWASP's GenAI Red Teaming Guide helps practitioners define the specific goals and scope of their testing efforts. A key element of the guide is the Blueprint for GenAI Red Teaming—a structured, phased approach to red teaming that includes planning, execution, and post-engagement processes (see Figure 4 below, reproduced from OWASP’s GenAI Red Teaming Guide). The Blueprint helps teams translate high-level objectives into actionable tasks, ensuring consistency and thoroughness across engagements.
Together, the OWASP Top 10 and the GenAI Red Teaming Guide provide a foundational framework for red teaming GenAI systems. The Top 10 informs what to test, while the Blueprint defines how to test it. Additional considerations, such as modality-specific risks or manual vs. automated testing, build on this core framework to provide a more holistic view of the red teaming strategy.

Defining the Objectives
With foundational frameworks like the OWASP Top 10 and the GenAI Red Teaming Guide in place, the next step is operationalizing them into a red team engagement. That begins with clearly defining your objectives. These objectives will shape the scope of testing, determine the tools and techniques used, and ultimately influence the impact of the red team’s findings. A vague or overly broad scope can dilute the effectiveness of the engagement. Clarity at this stage is essential.
- Content Generation Testing: Can the model produce harmful outputs? If it inherently cannot generate specific content (e.g., weapon instructions), security controls preventing such outputs become secondary.
- Implementation Controls: Examining system prompts, third-party guardrails, and defenses against malicious inputs.
- Agentic AI Risks: Assessing external integrations and unintended autonomy, particularly for AI agents with decision-making capabilities.
- Runtime Behaviors: Evaluating how AI-driven processes impact downstream business operations.
Automated Versus Manual Red Teaming
As we’ve discussed in depth previously, many open-source and commercial tools are available to organizations wishing to automate the testing of their generative AI deployments against adversarial attacks. Leveraging automation is great for a few reasons:
- A repeatable baseline for testing model updates.
- The ability to identify low-hanging fruit quickly.
- Efficiency in testing adversarial prompts at scale.
Certain automated red teaming tools, such as PyRIT, work by allowing red teams to specify an objective in the form of a prompt to an attacking LLM. This attacking LLM then dynamically generates prompts to send to the target LLM, refining its prompts based on the output of the target LLM until it hopefully achieves the red team’s objective. While such tools can be useful, it can take more time to refine one’s initial prompt to the attacking LLM than it would take just to attack the target LLM directly. For red teamers on an engagement with a limited time scope, this tradeoff needs to be considered beforehand to avoid wasting valuable time.
Automation has limits. The nature of AI threats—where adversaries continually adapt—demands human ingenuity. Manual red teaming allows for dynamic, real-time adjustments that automation can’t replicate. The cat-and-mouse game between AI defenders and attackers makes human-driven testing indispensable.
Defining The Objectives
Arguably, the most important part of a red team engagement is defining the overall objectives of the test. A successful red team engagement starts with clear objectives. Organizations must define:
- Model Type & Modality: Attacks on text-based models differ from those on image or audio-based systems, which introduce attack possibilities like adversarial perturbations and hiding prompts within the image or audio channel.
- Testing Goals: Establishing clear objectives (e.g., prompt injection, data leakage) ensures both parties align on success criteria.
The OWASP GenAI Red Teaming Guide is a great starting point for new red teamers to define what these objectives will be. Without an industry-standard taxonomy of attacks, organizations will need to define their own potential objectives based on their own skillsets, expertise, and experience attacking genAI systems. These objectives can then be discussed and agreed upon before any engagement takes place.
Following a Playbook
The process of establishing manual red teaming can be tedious, time-consuming, and can risk getting off track. This is where having a pre-defined playbook comes in handy. A playbook helps:
- Map objectives to specific techniques (e.g., testing for "Generation of Toxic Content" via Prompt Injection or KROP attacks).
- Ensure consistency across engagements.
- Onboard less experienced red teamers faster by providing sample attack scenarios.
For example, if “Generation of Toxic Content” is an objective of a red team engagement, the playbook would list subsequent techniques that could be used to achieve this objective. A red teamer can refer to the playbook and see that something like Prompt Injection or KROP would be a valuable technique to test. For more mature red team organizations, sample prompts can be associated with techniques that will enable less experienced red teamers to ramp up quickly and provide value on engagements.
Documenting and Sharing Results
The final task for a red team engagement is to ensure that all results are properly documented so that they can be shared with the client. An important consideration when sharing results is providing enough information and context so that the client can reproduce all results after the engagement. This includes providing all sample prompts, responses, and any tooling used to create adversarial input into the genAI system during the engagement. Since the goal of a red team engagement is to improve an organization’s security posture, being able to test the attacks after making security changes allows the clients to validate their efforts.
Knowing that an AI system can be bypassed is an interesting data point. Understanding how to fix these issues is why red teaming is done. Every prompt and test done against an AI system must be done with the purpose of having a recommendation tied to how to prevent that attack in the future. Proving something can be broken without any method to fix it wastes the time of both the red teamers and the organization.
All of these findings and recommendations should then be packaged up and presented to the appropriate stakeholders on both sides. Allowing the organization to review the results and ask questions of the red team can provide tremendous value. Seeing how an attack can unfold or discussing why an attack works enables organizations to fully grasp how to secure their systems and get the full value of a red team engagement. The ultimate goal isn’t just to uncover vulnerabilities but rather to strengthen AI security.
Conclusion
Effective AI red teaming combines industry best practices with real-world expertise. By defining objectives, leveraging automation alongside human ingenuity, and following structured methodologies, organizations can proactively strengthen AI security. If you want to learn more about AI red teaming, the HiddenLayer Professional Services team is here to help. Contact us to learn more.

AI Security: 2025 Predictions Recommendations
It’s time to dust off the crystal ball once again! Over the past year, AI has truly been at the forefront of cyber security, with increased scrutiny from attackers, defenders, developers, and academia. As various forms of generative AI drive mass AI adoption, we find that the threats are not lagging far behind, with LLMs, RAGs, Agentic AI, integrations, and plugins being a hot topic for researchers and miscreants alike.
Predictions for 2025
It’s time to dust off the crystal ball once again! Over the past year, AI has truly been at the forefront of cyber security, with increased scrutiny from attackers, defenders, developers, and academia. As various forms of generative AI drive mass AI adoption, we find that the threats are not lagging far behind, with LLMs, RAGs, Agentic AI, integrations, and plugins being a hot topic for researchers and miscreants alike.
Looking ahead, we expect the AI security landscape will face even more sophisticated challenges in 2025:
- Agentic AI as a Target:
Integrating agentic AI will blur the lines between adversarial AI and traditional cyberattacks, leading to a new wave of targeted threats. Expect phishing and data leakage via agentic systems to be a hot topic. - Erosion of Trust in Digital Content:
As deepfake technologies become more accessible, audio, visual, and text-based digital content trust will face near-total erosion. Expect to see advances in AI watermarking to help combat such attacks. - Adversarial AI: Organizations will integrate adversarial machine learning (ML) into standard red team exercises, testing for AI vulnerabilities proactively before deployment.
- AI-Specific Incident Response:
For the first time, formal incident response guidelines tailored to AI systems will be developed, providing a structured approach to AI-related security breaches. Expect to see playbooks developed for AI risks. - Advanced Threat Evolution:
Fraud, misinformation, and network attacks will escalate as AI evolves across domains such as computer vision (CV), audio, and natural language processing (NLP). Expect to see attackers leveraging AI to increase both the speed and scale of attack, as well as semi-autonomous offensive models designed to aid in penetration testing and security research. - Emergence of AIPC (AI-Powered Cyberattacks):
As hardware vendors capitalize on AI with advances in bespoke chipsets and tooling to power AI technology, expect to see attacks targeting AI-capable endpoints intensify, including:- Local model tampering. Hijacking models to abuse predictions, bypass refusals, and perform harmful actions.
- Data poisoning.
- Abuse of agentic systems. For example, prompt injections in emails and documents to exploit local models.
- Exploitation of vulnerabilities in 3rd party AI libraries and models.
Recommendations for the Security Practitioner
In the 2024 threat report, we made several recommendations for organizations to consider that were similar in concept to existing security-related control practices but built specifically for AI, such as:
- Discovery and Asset Management: Identifying and cataloging AI systems and related assets.
- Risk Assessment and Threat Modeling: Evaluating potential vulnerabilities and attack vectors specific to AI.
- Data Security and Privacy: Ensuring robust protection for sensitive datasets.
- Model Robustness and Validation: Strengthening models to withstand adversarial attacks and verifying their integrity.
- Secure Development Practices: Embedding security throughout the AI development lifecycle.
- Continuous Monitoring and Incident Response: Establishing proactive detection and response mechanisms for AI-related threats.
These practices remain foundational as organizations navigate the continuously unfolding AI threat landscape.
Building on these recommendations, 2024 marked a turning point in the AI landscape. The rapid AI 'electrification' of industries saw nearly every IT vendor integrate or expand AI capabilities, while service providers across sectors—from HR to law firms and accountants—widely adopted AI to enhance offerings and optimize operations. This made 2024 the year that AI-related third—and fourth-party risk issues became acutely apparent.
During the Security for AI Council meeting at Black Hat this year, the subject of AI third-party risk arose. Everyone in the council acknowledged it was generally a struggle, with at least one member noting that a "requirement to notify before AI is used/embedded into a solution” clause was added in all vendor contracts. The council members who had already been asking vendors about their use of AI said those vendors didn’t have good answers. They “don't really know,” which is not only surprising but also a noted disappointment. The group acknowledged traditional security vendors were only slightly better than others, but overall, most vendors cannot respond adequately to AI risk questions. The council then collaborated to create a detailed set of AI 3rd party risk questions. We recommend you consider adding these key questions to your existing vendor evaluation processes going forward.
- Where did your model come from?
- Do you scan your models for malicious code? How do you determine if the model is poisoned?
- Do you log and monitor model interactions?
- Do you detect, alert, and respond to mitigate risks that are identified in the OWASP LLM Top 10?
- What is your threat model for AI-related attacks? Are your threat model and mitigations mapped or aligned to the MITRE Atlas?
- What AI incident response policies does your organization have in place in the event of security incidents that impact the safety, privacy, or security of individuals or the function of the model?
- Do you validate the integrity of the data presented by your AI system and/or model?
Remember that the security landscape—and AI technology—is dynamic and rapidly changing. It's crucial to stay informed about emerging threats and best practices. Regularly update and refine your AI-specific security program to address new challenges and vulnerabilities.
And a note of caution. In many cases, responsible and ethical AI frameworks fall short of ensuring models are secure before they go into production and after an AI system is in use. They focus on things such as biases, appropriate use, and privacy. While these are also required, don’t confuse these practices for security.
Securely Introducing Open Source Models into Your Organization
Open source models are powerful tools for data scientists, but they also come with risks. If your team downloads models from sources like Hugging Face without security checks, you could introduce security threats into your organization. You can eliminate this risk by introducing a process that scans models for vulnerabilities before they enter your organization and are utilized by data scientists. You can ensure that only safe models are used by leveraging HiddenLayer's Model Scanner combined with your CI/CD platform. In this blog, we'll walk you through how to set up a system where data scientists request models, security checks run automatically, and approved models are stored in a safe location like cloud storage, a model registry, or Databricks Unity Catalog.
Summary
Open source models are powerful tools for data scientists, but they also come with risks. If your team downloads models from sources like Hugging Face without security checks, you could introduce security threats into your organization. You can eliminate this risk by introducing a process that scans models for vulnerabilities before they enter your organization and are utilized by data scientists. You can ensure that only safe models are used by leveraging HiddenLayer's Model Scanner combined with your CI/CD platform. In this blog, we'll walk you through how to set up a system where data scientists request models, security checks run automatically, and approved models are stored in a safe location like cloud storage, a model registry, or Databricks Unity Catalog.
Introduction
Data Scientists download open source AI models from open repositories like Hugging Face or Kaggle every day. As of today security scans are rudimentary and are limited to specific model types and as a result, proper security checks are not taking place. If the model contains malicious code, it could expose sensitive company data, cause system failures, or create security vulnerabilities.
Organizations need a way to ensure that the models they use are safe before deploying them. However, blocking access to open source models isn't the answer—after all, these models provide huge benefits. Instead, companies should establish a secure process that allows data scientists to use open source models while protecting the organization from hidden threats.
In this blog, we’ll explore how you can implement a secure model approval workflow using HiddenLayer’s Model Scanner and GitHub Actions. This approach enables data scientists to request models through a simple GitHub form, have them automatically scanned for threats, and—if they pass—store them in a trusted location.
The Risk of Downloading Open Source Models
Downloading models directly from public repositories like Hugging Face might seem harmless, but it can introduce serious security risks:
- Malicious Code Injection: Some models may contain hidden backdoors or harmful scripts that execute when loaded.
- Unauthorized Data Access: A compromised model could expose your company’s sensitive data or leak information.
- System Instability: Poorly built or tampered models might crash systems, leading to downtime and productivity loss.
- Compliance Violations: Using unverified models could put your company at risk of breaking security and privacy regulations.
To prevent these issues, organizations need a structured way to approve and distribute open source models safely.
A Secure Process for Open Source Models
The key to safely using open source models is implementing a secure workflow. Here’s how you can do it:
- Model Request Form in GitHub
Instead of allowing direct downloads, require data scientists to request models through a GitHub form. This ensures that every model is reviewed before use.
This can be mandated by globally blocking API access to HuggingFace.
- Automated Security Scan with HiddenLayer Model Scanner
Once a request is submitted, a CI/CD pipeline (using GitHub Actions) automatically scans the model using HiddenLayer’s open source Model Scanner. This tool checks for malicious code, security vulnerabilities, and compliance issues.
- Secure Storage for Approved Models
If a model passes the security scan, it is pushed to a trusted location, such as:
- Cloud storage (AWS S3, Google Cloud Storage, etc.)
- A model registry (MLflow, Databricks Unity Catalog, etc.)
- A secure internal repository Now, data scientists can safely access and use only the approved models.
Benefits of This Process
Implementing this structured model approval process offers several advantages:
- Leverages Existing MLOps & GitOps Infrastructure: The workflow integrates seamlessly with existing CI/CD pipelines and security controls, reducing operational overhead.
- Single Entry Point for Open Source Models: This system ensures that all open source models entering the organization go through a centralized and tightly controlled approval process.
- Automated Security Checks: HiddenLayer’s Model Scanner automatically scans every model request, ensuring that no unverified models make their way into production.
- Compliance and Governance: The process ensures adherence to regulatory requirements by providing a documented trail of all approved and rejected models.
- Improved Collaboration: Data scientists can access secure, organization-approved models without delays while security teams maintain full visibility and control.
Implementing the Secure Model Workflow
Here’s a step-by-step process of how you can set up this workflow:
- Create a GitHub Form: Data scientists submit requests for open source models through this form.
- Trigger a CI/CD Pipeline: The form submission kicks off an automated workflow using GitHub Actions.
- Scan the Model with HiddenLayer: The HiddenLayer Model Scanner runs security checks on the requested model.
- Store or Reject the Model:
- If safe, the model is pushed to a secure storage location.
- If unsafe, the request is flagged for review and triage.
- Access Approved Models: Data scientists can retrieve and use models from a secure storage location.

Figure 1 - Secure Model Workflow
Conclusion
Open source models have moved the needle for AI development, but they come with risks that organizations can't ignore. By implementing a single point of access into your organization for models that are scanned by HiddenLayer, you can allow data scientists to use these models safely. This process ensures that only verified, threat-free models make their way into your systems, protecting your organization from potential harm.
By taking this proactive approach, you create a balance between innovation and security, allowing your Data Scientists to work with open source models, while keeping your organization safe.

Enhancing AI Security with HiddenLayer’s Refusal Detection
Security risks in AI applications are not one-size-fits-all. A system processing sensitive customer data presents vastly different security challenges compared to one that aggregates internet data for market analysis. To effectively safeguard an AI application, developers and security professionals must implement comprehensive mechanisms that instruct models to decline contextually malicious requests—such as revealing personally identifiable information (PII) or ingesting data from untrusted sources. Monitoring these refusals provides an early and high-accuracy warning system for potential malicious behavior.
Introduction
Security risks in AI applications are not one-size-fits-all. A system processing sensitive customer data presents vastly different security challenges compared to one that aggregates internet data for market analysis. To effectively safeguard an AI application, developers and security professionals must implement comprehensive mechanisms that instruct models to decline contextually malicious requests—such as revealing personally identifiable information (PII) or ingesting data from untrusted sources. Monitoring these refusals provides an early and high-accuracy warning system for potential malicious behavior.
However, current guardrails provided by large language model (LLM) vendors fail to capture the unique risk profiles of different applications. HiddenLayer Refusal Detection, a new feature within the AI Sec Platform, is a specialized language model designed to alert and block users when AI models refuse a request, empowering businesses to define and enforce application-specific security measures.
Addressing the Gaps in AI Security
Today’s generic guardrails focus on broad-spectrum risks, such as detecting toxicity or preventing extreme-edge threats like bomb-making instructions. While these measures serve a purpose, they do not adequately address the nuanced security concerns of enterprise AI applications. Defining malicious behavior in AI security is not always straightforward—a request to retrieve a credit card number, for example, cannot be inherently categorized as malicious without considering the application’s intent, the requester's authentication status, and the card’s ownership.
Without customizable security layers, businesses are forced to take an overly cautious approach, restricting use cases that could otherwise be securely enabled. Traditional business logic rules, such as allowing customers to retrieve their own stored credit card information while blocking unauthorized access, struggle to encapsulate the full scope of nuanced security concerns.
Generative AI models excel at interpreting nuanced security instructions. Organizations can significantly enhance their AI security posture by embedding clear directives regarding acceptable and malicious use cases. While adversarial techniques like prompt injections can still attempt to circumvent protections, monitoring when an AI model refuses a request serves as a strong signal of potential malicious activity.
Introducing HiddenLayer Refusal Detection
HiddenLayer’s Refusal Detection leverages advanced language models to track and analyze refusals, whether they originate from upstream LLM guardrails or custom security configurations. Unlike traditional solutions, which rely on limited API-based flagging, HiddenLayer’s technology offers comprehensive monitoring capabilities across various AI models.
Key Features of HiddenLayer Refusal Detection:
- Universal Model Compatibility – Works with any AI model, not just specific vendor ecosystems.
- Multilingual Support – Provides basic non-English coverage to extend security reach globally.
- SOC Integration – Enables security operations teams to receive real-time alerts on refusals, enhancing visibility into potential threats.
By identifying refusal patterns, security teams can gain crucial insights into attacker methodologies, allowing them to strengthen AI security defenses proactively.
Empowering Enterprises with Seamless Implementation
Refusal Detection is included as a core feature in HiddenLayer’s AIDR, allowing security teams to activate it with minimal effort. Organizations can begin monitoring AI outputs for refusals using a more powerful detection framework by simply setting the relevant flag within their AI system.
Get Started with HiddenLayer’s Refusal Detection
To leverage this advanced security feature, update to the latest version of AIDR. Refusal detection is enabled by default with a configuration flag set at instantiation. Comprehensive deployment guidance is available in our online documentation portal.
By proactively monitoring AI refusals, enterprises can reinforce their AI security posture, mitigate risks, and stay ahead of emerging threats in an increasingly AI-driven world.

Understand AI Security, Clearly Defined
Explore our glossary to get clear, practical definitions of the terms shaping AI security, governance, and risk management.